 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
A Study of Recent Contributions on Information Extraction
Mar 15, 2018
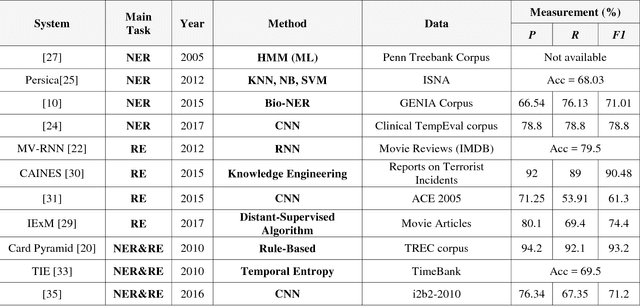
This paper reports on modern approaches in Information Extraction (IE) and its two main sub-tasks of Named Entity Recognition (NER) and Relation Extraction (RE). Basic concepts and the most recent approaches in this area are reviewed, which mainly include Machine Learning (ML) based approaches and the more recent trend to Deep Learning (DL) based methods.
Vietnamese Open Information Extraction
Jan 23, 2018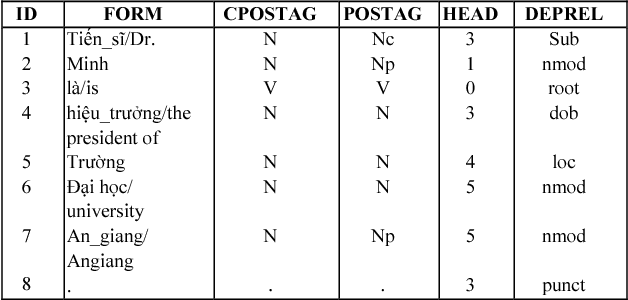
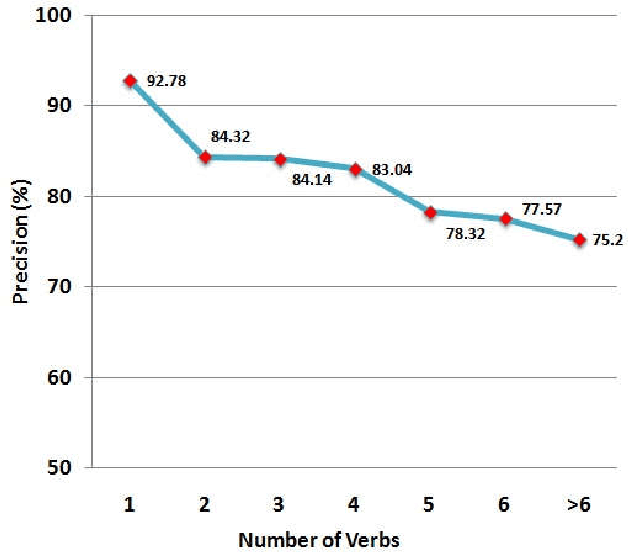
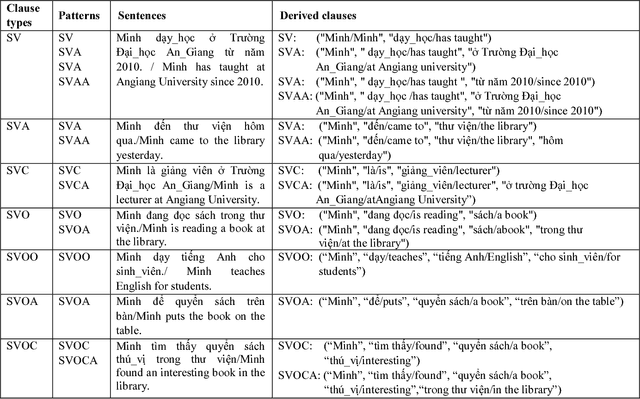
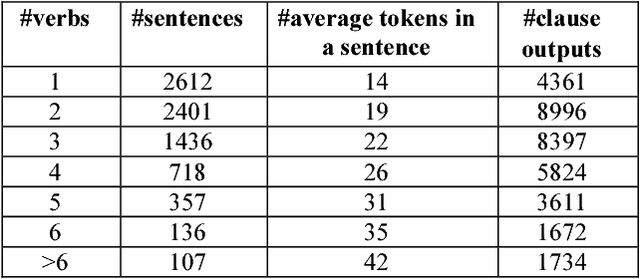
Open information extraction (OIE) is the process to extract relations and their arguments automatically from textual documents without the need to restrict the search to predefined relations. In recent years, several OIE systems for the English language have been created but there is not any system for the Vietnamese language. In this paper, we propose a method of OIE for Vietnamese using a clause-based approach. Accordingly, we exploit Vietnamese dependency parsing using grammar clauses that strives to consider all possible relations in a sentence. The corresponding clause types are identified by their propositions as extractable relations based on their grammatical functions of constituents. As a result, our system is the first OIE system named vnOIE for the Vietnamese language that can generate open relations and their arguments from Vietnamese text with highly scalable extraction while being domain independent. Experimental results show that our OIE system achieves promising results with a precision of 83.71%.
Improving Malware Detection Accuracy by Extracting Icon Information
Dec 10, 2017
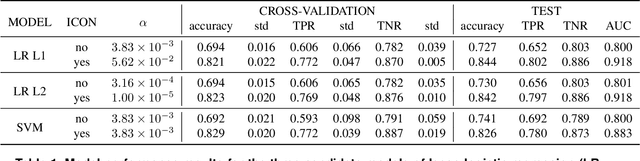
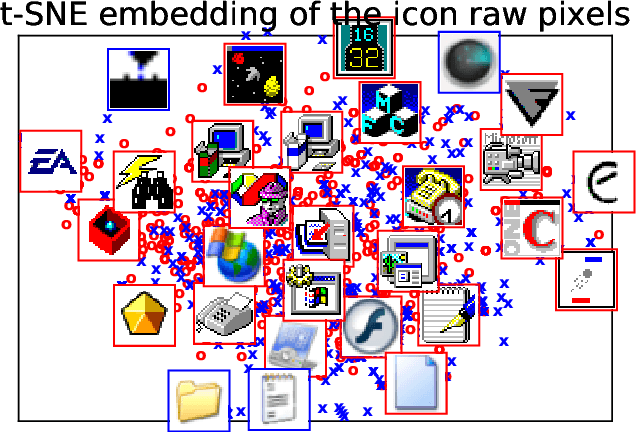
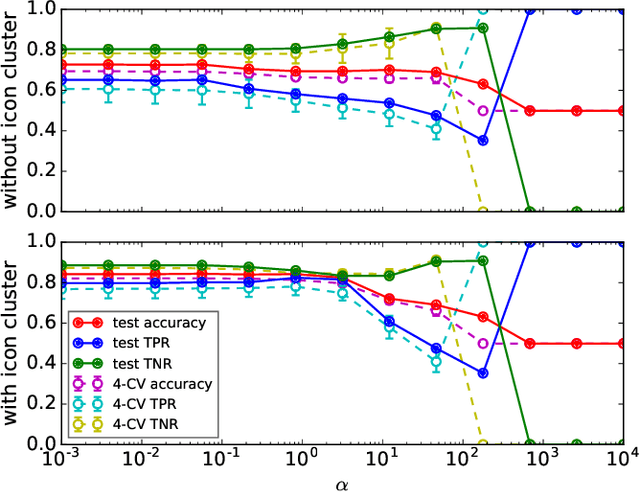
Detecting PE malware files is now commonly approached using statistical and machine learning models. While these models commonly use features extracted from the structure of PE files, we propose that icons from these files can also help better predict malware. We propose an innovative machine learning approach to extract information from icons. Our proposed approach consists of two steps: 1) extracting icon features using summary statics, histogram of gradients (HOG), and a convolutional autoencoder, 2) clustering icons based on the extracted icon features. Using publicly available data and by using machine learning experiments, we show our proposed icon clusters significantly boost the efficacy of malware prediction models. In particular, our experiments show an average accuracy increase of 10% when icon clusters are used in the prediction model.
Joint Recognition of Handwritten Text and Named Entities with a Neural End-to-end Model
Mar 22, 2018
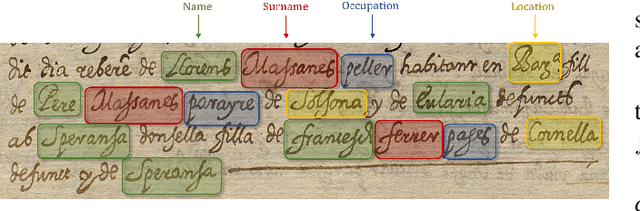
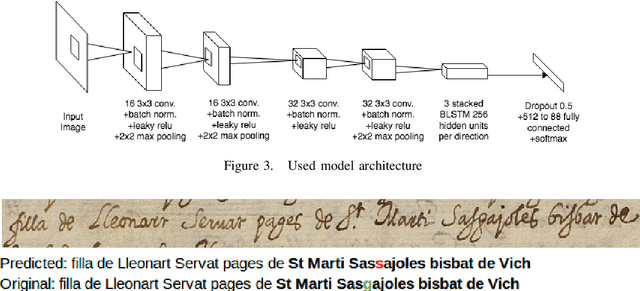

When extracting information from handwritten documents, text transcription and named entity recognition are usually faced as separate subsequent tasks. This has the disadvantage that errors in the first module affect heavily the performance of the second module. In this work we propose to do both tasks jointly, using a single neural network with a common architecture used for plain text recognition. Experimentally, the work has been tested on a collection of historical marriage records. Results of experiments are presented to show the effect on the performance for different configurations: different ways of encoding the information, doing or not transfer learning and processing at text line or multi-line region level. The results are comparable to state of the art reported in the ICDAR 2017 Information Extraction competition, even though the proposed technique does not use any dictionaries, language modeling or post processing.
Relation Extraction : A Survey
Dec 14, 2017

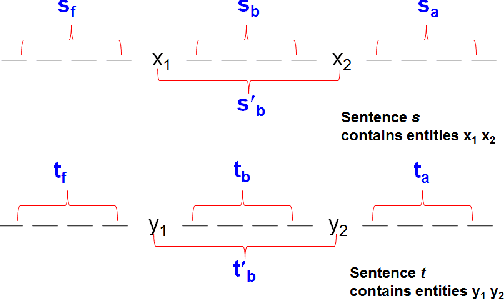
With the advent of the Internet, large amount of digital text is generated everyday in the form of news articles, research publications, blogs, question answering forums and social media. It is important to develop techniques for extracting information automatically from these documents, as lot of important information is hidden within them. This extracted information can be used to improve access and management of knowledge hidden in large text corpora. Several applications such as Question Answering, Information Retrieval would benefit from this information. Entities like persons and organizations, form the most basic unit of the information. Occurrences of entities in a sentence are often linked through well-defined relations; e.g., occurrences of person and organization in a sentence may be linked through relations such as employed at. The task of Relation Extraction (RE) is to identify such relations automatically. In this paper, we survey several important supervised, semi-supervised and unsupervised RE techniques. We also cover the paradigms of Open Information Extraction (OIE) and Distant Supervision. Finally, we describe some of the recent trends in the RE techniques and possible future research directions. This survey would be useful for three kinds of readers - i) Newcomers in the field who want to quickly learn about RE; ii) Researchers who want to know how the various RE techniques evolved over time and what are possible future research directions and iii) Practitioners who just need to know which RE technique works best in various settings.
Combining Static and Dynamic Features for Multivariate Sequence Classification
Dec 20, 2017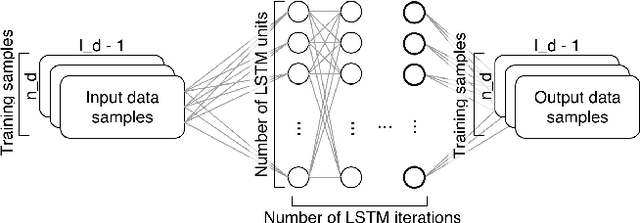
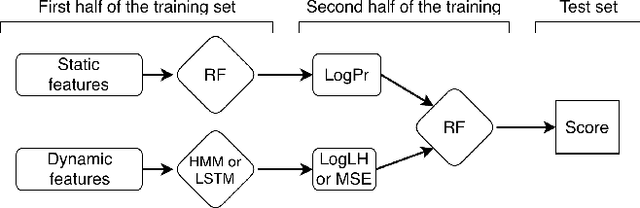
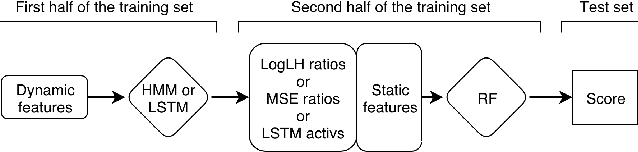
Model precision in a classification task is highly dependent on the feature space that is used to train the model. Moreover, whether the features are sequential or static will dictate which classification method can be applied as most of the machine learning algorithms are designed to deal with either one or another type of data. In real-life scenarios, however, it is often the case that both static and dynamic features are present, or can be extracted from the data. In this work, we demonstrate how generative models such as Hidden Markov Models (HMM) and Long Short-Term Memory (LSTM) artificial neural networks can be used to extract temporal information from the dynamic data. We explore how the extracted information can be combined with the static features in order to improve the classification performance. We evaluate the existing techniques and suggest a hybrid approach, which outperforms other methods on several public datasets.
Multimodal Attribute Extraction
Nov 29, 2017
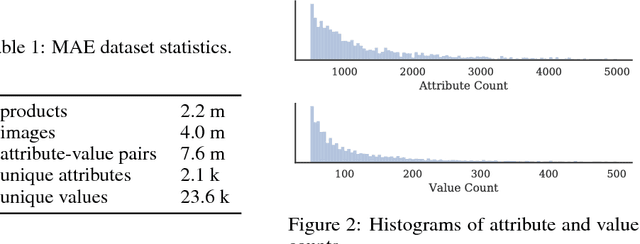
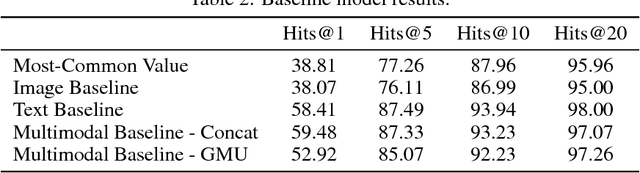
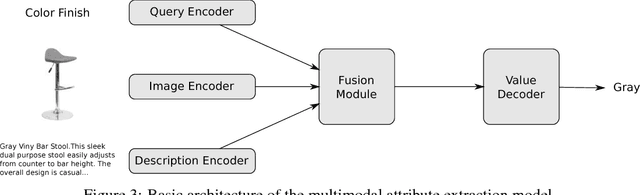
The broad goal of information extraction is to derive structured information from unstructured data. However, most existing methods focus solely on text, ignoring other types of unstructured data such as images, video and audio which comprise an increasing portion of the information on the web. To address this shortcoming, we propose the task of multimodal attribute extraction. Given a collection of unstructured and semi-structured contextual information about an entity (such as a textual description, or visual depictions) the task is to extract the entity's underlying attributes. In this paper, we provide a dataset containing mixed-media data for over 2 million product items along with 7 million attribute-value pairs describing the items which can be used to train attribute extractors in a weakly supervised manner. We provide a variety of baselines which demonstrate the relative effectiveness of the individual modes of information towards solving the task, as well as study human performance.
Assertion-based QA with Question-Aware Open Information Extraction
Jan 23, 2018
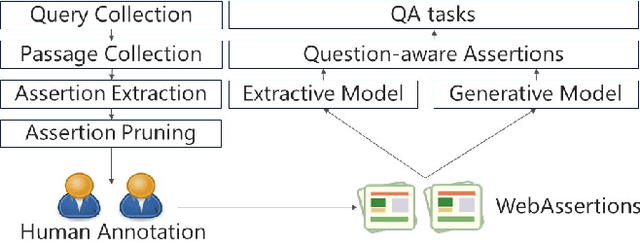

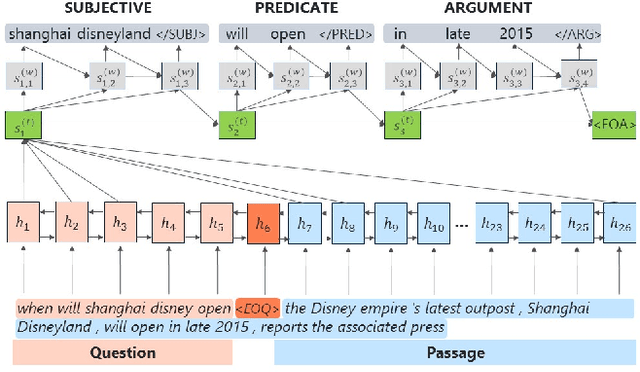
We present assertion based question answering (ABQA), an open domain question answering task that takes a question and a passage as inputs, and outputs a semi-structured assertion consisting of a subject, a predicate and a list of arguments. An assertion conveys more evidences than a short answer span in reading comprehension, and it is more concise than a tedious passage in passage-based QA. These advantages make ABQA more suitable for human-computer interaction scenarios such as voice-controlled speakers. Further progress towards improving ABQA requires richer supervised dataset and powerful models of text understanding. To remedy this, we introduce a new dataset called WebAssertions, which includes hand-annotated QA labels for 358,427 assertions in 55,960 web passages. To address ABQA, we develop both generative and extractive approaches. The backbone of our generative approach is sequence to sequence learning. In order to capture the structure of the output assertion, we introduce a hierarchical decoder that first generates the structure of the assertion and then generates the words of each field. The extractive approach is based on learning to rank. Features at different levels of granularity are designed to measure the semantic relevance between a question and an assertion. Experimental results show that our approaches have the ability to infer question-aware assertions from a passage. We further evaluate our approaches by incorporating the ABQA results as additional features in passage-based QA. Results on two datasets show that ABQA features significantly improve the accuracy on passage-based~QA.
Adversary Detection in Neural Networks via Persistent Homology
Nov 28, 2017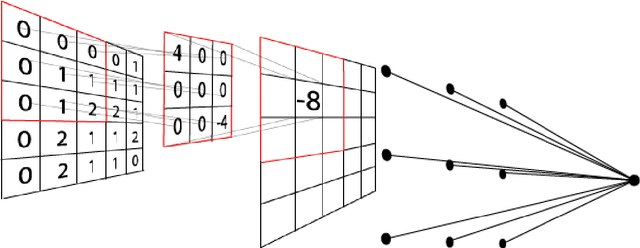



We outline a detection method for adversarial inputs to deep neural networks. By viewing neural network computations as graphs upon which information flows from input space to out- put distribution, we compare the differences in graphs induced by different inputs. Specifically, by applying persistent homology to these induced graphs, we observe that the structure of the most persistent subgraphs which generate the first homology group differ between adversarial and unperturbed inputs. Based on this observation, we build a detection algorithm that depends only on the topological information extracted during training. We test our algorithm on MNIST and achieve 98% detection adversary accuracy with F1-score 0.98.
Fast Interactive Image Retrieval using large-scale unlabeled data
Feb 12, 2018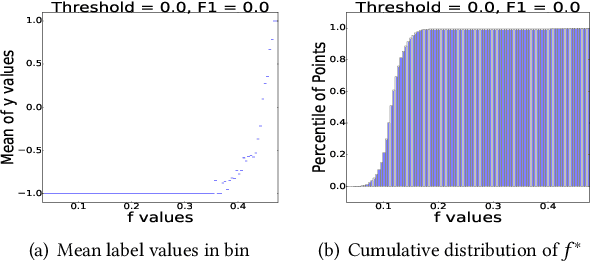
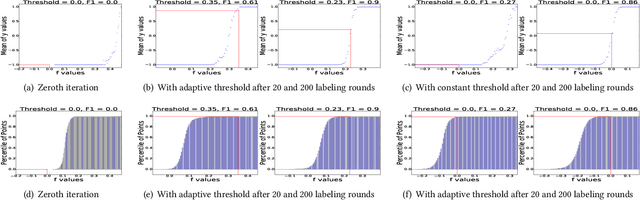
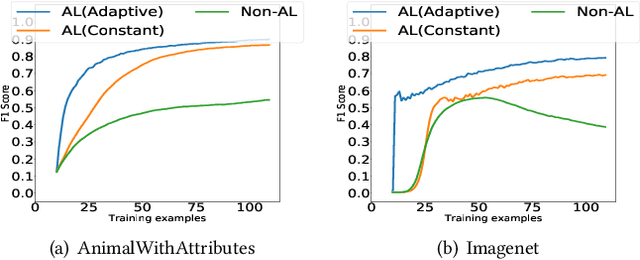
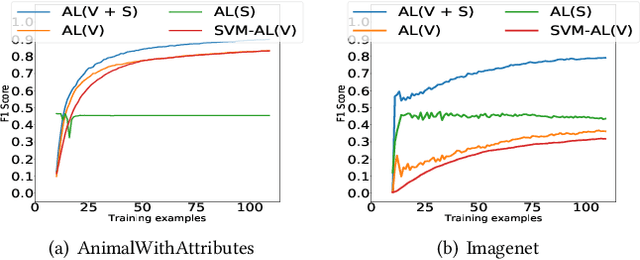
An interactive image retrieval system learns which images in the database belong to a user's query concept, by analyzing the example images and feedback provided by the user. The challenge is to retrieve the relevant images with minimal user interaction. In this work, we propose to solve this problem by posing it as a binary classification task of classifying all images in the database as being relevant or irrelevant to the user's query concept. Our method combines active learning with graph-based semi-supervised learning (GSSL) to tackle this problem. Active learning reduces the number of user interactions by querying the labels of the most informative points and GSSL allows to use abundant unlabeled data along with the limited labeled data provided by the user. To efficiently find the most informative point, we use an uncertainty sampling based method that queries the label of the point nearest to the decision boundary of the classifier. We estimate this decision boundary using our heuristic of adaptive threshold. To utilize huge volumes of unlabeled data we use an efficient approximation based method that reduces the complexity of GSSL from $O(n^3)$ to $O(n)$, making GSSL scalable. We make the classifier robust to the diversity and noisy labels associated with images in large databases by incorporating information from multiple modalities such as visual information extracted from deep learning based models and semantic information extracted from the WordNet. High F1 scores within few relevance feedback rounds in our experiments with concepts defined on AnimalWithAttributes and Imagenet (1.2 million images) datasets indicate the effectiveness and scalability of our approach.