 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
A Sentiment Analysis of Medical Text Based on Deep Learning
Apr 16, 2024
The field of natural language processing (NLP) has made significant progress with the rapid development of deep learning technologies. One of the research directions in text sentiment analysis is sentiment analysis of medical texts, which holds great potential for application in clinical diagnosis. However, the medical field currently lacks sufficient text datasets, and the effectiveness of sentiment analysis is greatly impacted by different model design approaches, which presents challenges. Therefore, this paper focuses on the medical domain, using bidirectional encoder representations from transformers (BERT) as the basic pre-trained model and experimenting with modules such as convolutional neural network (CNN), fully connected network (FCN), and graph convolutional networks (GCN) at the output layer. Experiments and analyses were conducted on the METS-CoV dataset to explore the training performance after integrating different deep learning networks. The results indicate that CNN models outperform other networks when trained on smaller medical text datasets in combination with pre-trained models like BERT. This study highlights the significance of model selection in achieving effective sentiment analysis in the medical domain and provides a reference for future research to develop more efficient model architectures.
On the Causal Nature of Sentiment Analysis
Apr 17, 2024Sentiment analysis (SA) aims to identify the sentiment expressed in a text, such as a product review. Given a review and the sentiment associated with it, this paper formulates SA as a combination of two tasks: (1) a causal discovery task that distinguishes whether a review "primes" the sentiment (Causal Hypothesis C1), or the sentiment "primes" the review (Causal Hypothesis C2); and (2) the traditional prediction task to model the sentiment using the review as input. Using the peak-end rule in psychology, we classify a sample as C1 if its overall sentiment score approximates an average of all the sentence-level sentiments in the review, and C2 if the overall sentiment score approximates an average of the peak and end sentiments. For the prediction task, we use the discovered causal mechanisms behind the samples to improve the performance of LLMs by proposing causal prompts that give the models an inductive bias of the underlying causal graph, leading to substantial improvements by up to 32.13 F1 points on zero-shot five-class SA. Our code is at https://github.com/cogito233/causal-sa
Evaluating Span Extraction in Generative Paradigm: A Reflection on Aspect-Based Sentiment Analysis
Apr 17, 2024In the era of rapid evolution of generative language models within the realm of natural language processing, there is an imperative call to revisit and reformulate evaluation methodologies, especially in the domain of aspect-based sentiment analysis (ABSA). This paper addresses the emerging challenges introduced by the generative paradigm, which has moderately blurred traditional boundaries between understanding and generation tasks. Building upon prevailing practices in the field, we analyze the advantages and shortcomings associated with the prevalent ABSA evaluation paradigms. Through an in-depth examination, supplemented by illustrative examples, we highlight the intricacies involved in aligning generative outputs with other evaluative metrics, specifically those derived from other tasks, including question answering. While we steer clear of advocating for a singular and definitive metric, our contribution lies in paving the path for a comprehensive guideline tailored for ABSA evaluations in this generative paradigm. In this position paper, we aim to provide practitioners with profound reflections, offering insights and directions that can aid in navigating this evolving landscape, ensuring evaluations that are both accurate and reflective of generative capabilities.
KazSAnDRA: Kazakh Sentiment Analysis Dataset of Reviews and Attitudes
Apr 09, 2024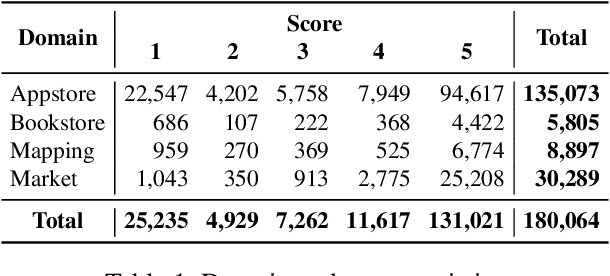
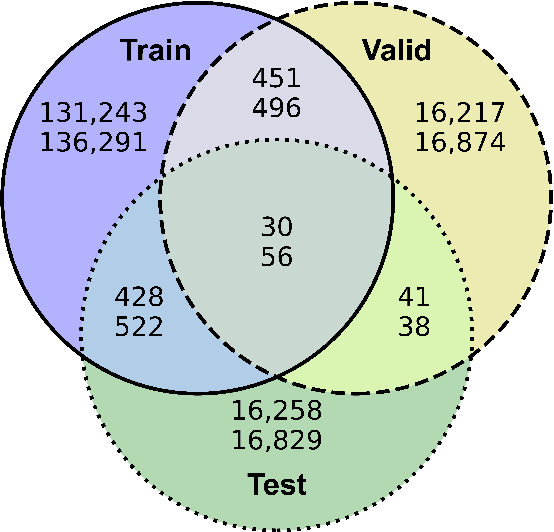


This paper presents KazSAnDRA, a dataset developed for Kazakh sentiment analysis that is the first and largest publicly available dataset of its kind. KazSAnDRA comprises an extensive collection of 180,064 reviews obtained from various sources and includes numerical ratings ranging from 1 to 5, providing a quantitative representation of customer attitudes. The study also pursued the automation of Kazakh sentiment classification through the development and evaluation of four machine learning models trained for both polarity classification and score classification. Experimental analysis included evaluation of the results considering both balanced and imbalanced scenarios. The most successful model attained an F1-score of 0.81 for polarity classification and 0.39 for score classification on the test sets. The dataset and fine-tuned models are open access and available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
Sentiment Analysis of Citations in Scientific Articles Using ChatGPT: Identifying Potential Biases and Conflicts of Interest
Apr 06, 2024Scientific articles play a crucial role in advancing knowledge and informing research directions. One key aspect of evaluating scientific articles is the analysis of citations, which provides insights into the impact and reception of the cited works. This article introduces the innovative use of large language models, particularly ChatGPT, for comprehensive sentiment analysis of citations within scientific articles. By leveraging advanced natural language processing (NLP) techniques, ChatGPT can discern the nuanced positivity or negativity of citations, offering insights into the reception and impact of cited works. Furthermore, ChatGPT's capabilities extend to detecting potential biases and conflicts of interest in citations, enhancing the objectivity and reliability of scientific literature evaluation. This study showcases the transformative potential of artificial intelligence (AI)-powered tools in enhancing citation analysis and promoting integrity in scholarly research.
Sentiment analysis and random forest to classify LLM versus human source applied to Scientific Texts
Apr 05, 2024After the launch of ChatGPT v.4 there has been a global vivid discussion on the ability of this artificial intelligence powered platform and some other similar ones for the automatic production of all kinds of texts, including scientific and technical texts. This has triggered a reflection in many institutions on whether education and academic procedures should be adapted to the fact that in future many texts we read will not be written by humans (students, scholars, etc.), at least, not entirely. In this work it is proposed a new methodology to classify texts coming from an automatic text production engine or a human, based on Sentiment Analysis as a source for feature engineering independent variables and then train with them a Random Forest classification algorithm. Using four different sentiment lexicons, a number of new features where produced, and then fed to a machine learning random forest methodology, to train such a model. Results seem very convincing that this may be a promising research line to detect fraud, in such environments where human are supposed to be the source of texts.
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Apr 02, 2024In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
Creating emoji lexica from unsupervised sentiment analysis of their descriptions
Apr 01, 2024Online media, such as blogs and social networking sites, generate massive volumes of unstructured data of great interest to analyze the opinions and sentiments of individuals and organizations. Novel approaches beyond Natural Language Processing are necessary to quantify these opinions with polarity metrics. So far, the sentiment expressed by emojis has received little attention. The use of symbols, however, has boomed in the past four years. About twenty billion are typed in Twitter nowadays, and new emojis keep appearing in each new Unicode version, making them increasingly relevant to sentiment analysis tasks. This has motivated us to propose a novel approach to predict the sentiments expressed by emojis in online textual messages, such as tweets, that does not require human effort to manually annotate data and saves valuable time for other analysis tasks. For this purpose, we automatically constructed a novel emoji sentiment lexicon using an unsupervised sentiment analysis system based on the definitions given by emoji creators in Emojipedia. Additionally, we automatically created lexicon variants by also considering the sentiment distribution of the informal texts accompanying emojis. All these lexica are evaluated and compared regarding the improvement obtained by including them in sentiment analysis of the annotated datasets provided by Kralj Novak et al. (2015). The results confirm the competitiveness of our approach.
EFSA: Towards Event-Level Financial Sentiment Analysis
Apr 08, 2024In this paper, we extend financial sentiment analysis~(FSA) to event-level since events usually serve as the subject of the sentiment in financial text. Though extracting events from the financial text may be conducive to accurate sentiment predictions, it has specialized challenges due to the lengthy and discontinuity of events in a financial text. To this end, we reconceptualize the event extraction as a classification task by designing a categorization comprising coarse-grained and fine-grained event categories. Under this setting, we formulate the \textbf{E}vent-Level \textbf{F}inancial \textbf{S}entiment \textbf{A}nalysis~(\textbf{EFSA} for short) task that outputs quintuples consisting of (company, industry, coarse-grained event, fine-grained event, sentiment) from financial text. A large-scale Chinese dataset containing $12,160$ news articles and $13,725$ quintuples is publicized as a brand new testbed for our task. A four-hop Chain-of-Thought LLM-based approach is devised for this task. Systematically investigations are conducted on our dataset, and the empirical results demonstrate the benchmarking scores of existing methods and our proposed method can reach the current state-of-the-art. Our dataset and framework implementation are available at https://anonymous.4open.science/r/EFSA-645E
TRABSA: Interpretable Sentiment Analysis of Tweets using Attention-based BiLSTM and Twitter-RoBERTa
Mar 30, 2024Sentiment analysis is crucial for understanding public opinion and consumer behavior. Existing models face challenges with linguistic diversity, generalizability, and explainability. We propose TRABSA, a hybrid framework integrating transformer-based architectures, attention mechanisms, and BiLSTM networks to address this. Leveraging RoBERTa-trained on 124M tweets, we bridge gaps in sentiment analysis benchmarks, ensuring state-of-the-art accuracy. Augmenting datasets with tweets from 32 countries and US states, we compare six word-embedding techniques and three lexicon-based labeling techniques, selecting the best for optimal sentiment analysis. TRABSA outperforms traditional ML and deep learning models with 94% accuracy and significant precision, recall, and F1-score gains. Evaluation across diverse datasets demonstrates consistent superiority and generalizability. SHAP and LIME analyses enhance interpretability, improving confidence in predictions. Our study facilitates pandemic resource management, aiding resource planning, policy formation, and vaccination tactics.