Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrueLabel + Confusions: A Spectrum of Probabilistic Models in Analyzing Multiple Ratings
Jun 18, 2012
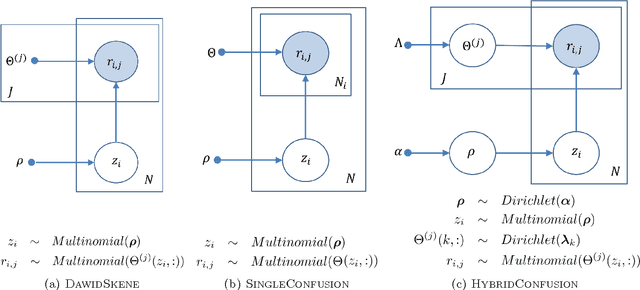

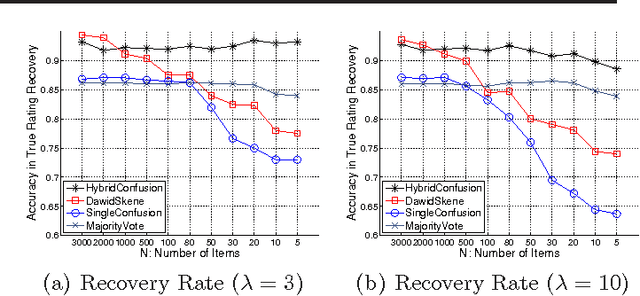
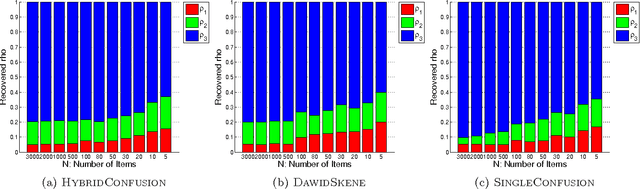
This paper revisits the problem of analyzing multiple ratings given by different judges. Different from previous work that focuses on distilling the true labels from noisy crowdsourcing ratings, we emphasize gaining diagnostic insights into our in-house well-trained judges. We generalize the well-known DawidSkene model (Dawid & Skene, 1979) to a spectrum of probabilistic models under the same "TrueLabel + Confusion" paradigm, and show that our proposed hierarchical Bayesian model, called HybridConfusion, consistently outperforms DawidSkene on both synthetic and real-world data sets.
* ICML2012
View paper on