 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInner Product Similarity Search using Compositional Codes
Jun 20, 2014

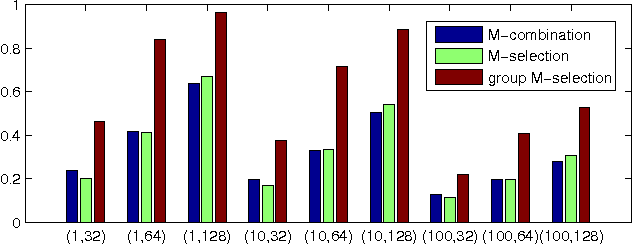
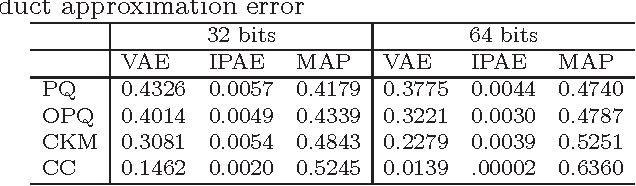
This paper addresses the nearest neighbor search problem under inner product similarity and introduces a compact code-based approach. The idea is to approximate a vector using the composition of several elements selected from a source dictionary and to represent this vector by a short code composed of the indices of the selected elements. The inner product between a query vector and a database vector is efficiently estimated from the query vector and the short code of the database vector. We show the superior performance of the proposed group $M$-selection algorithm that selects $M$ elements from $M$ source dictionaries for vector approximation in terms of search accuracy and efficiency for compact codes of the same length via theoretical and empirical analysis. Experimental results on large-scale datasets ($1M$ and $1B$ SIFT features, $1M$ linear models and Netflix) demonstrate the superiority of the proposed approach.