 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition of Isolated Words using Zernike and MFCC features for Audio Visual Speech Recognition
Jul 04, 2014


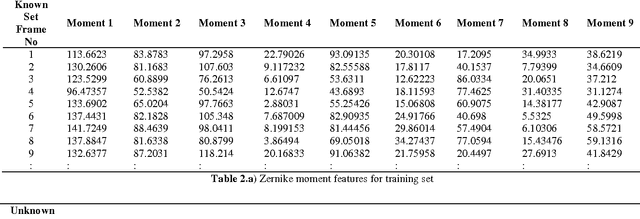
Automatic Speech Recognition (ASR) by machine is an attractive research topic in signal processing domain and has attracted many researchers to contribute in this area. In recent year, there have been many advances in automatic speech reading system with the inclusion of audio and visual speech features to recognize words under noisy conditions. The objective of audio-visual speech recognition system is to improve recognition accuracy. In this paper we computed visual features using Zernike moments and audio feature using Mel Frequency Cepstral Coefficients (MFCC) on vVISWa (Visual Vocabulary of Independent Standard Words) dataset which contains collection of isolated set of city names of 10 speakers. The visual features were normalized and dimension of features set was reduced by Principal Component Analysis (PCA) in order to recognize the isolated word utterance on PCA space.The performance of recognition of isolated words based on visual only and audio only features results in 63.88 and 100 respectively.