 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Lexical, Syntactic, and Semantic Features for Chinese Textual Entailment in NTCIR RITE Evaluation Tasks
Apr 08, 2015
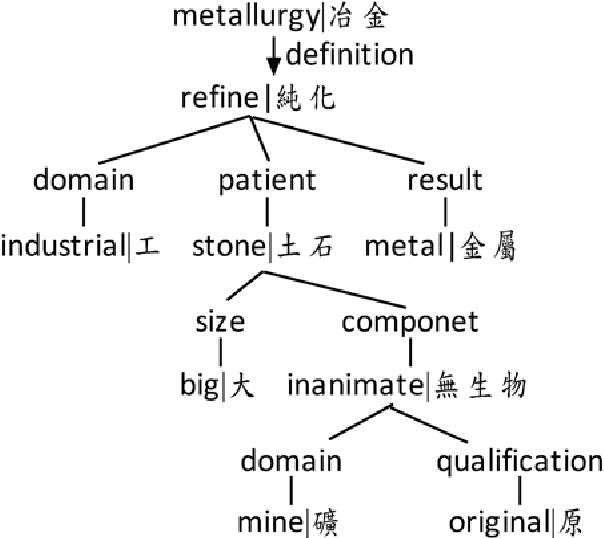
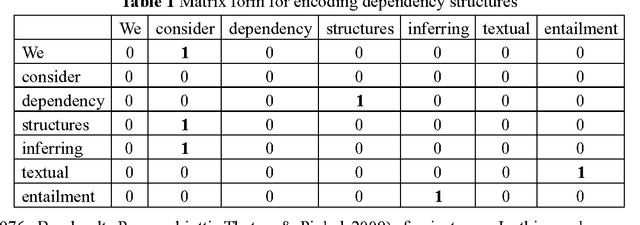
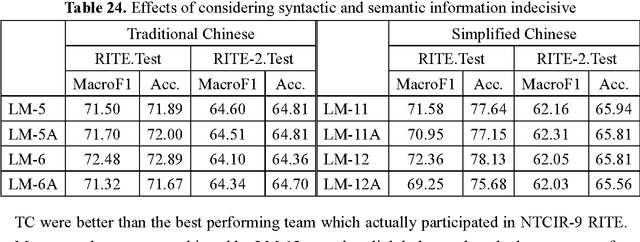
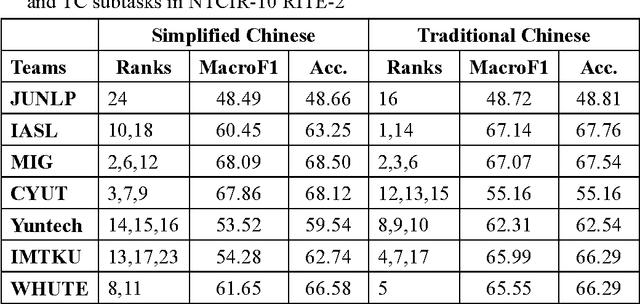
We computed linguistic information at the lexical, syntactic, and semantic levels for Recognizing Inference in Text (RITE) tasks for both traditional and simplified Chinese in NTCIR-9 and NTCIR-10. Techniques for syntactic parsing, named-entity recognition, and near synonym recognition were employed, and features like counts of common words, statement lengths, negation words, and antonyms were considered to judge the entailment relationships of two statements, while we explored both heuristics-based functions and machine-learning approaches. The reported systems showed robustness by simultaneously achieving second positions in the binary-classification subtasks for both simplified and traditional Chinese in NTCIR-10 RITE-2. We conducted more experiments with the test data of NTCIR-9 RITE, with good results. We also extended our work to search for better configurations of our classifiers and investigated contributions of individual features. This extended work showed interesting results and should encourage further discussion.