 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Complicated Question Intents Expressed in Decomposed Question Sequences
Nov 04, 2016
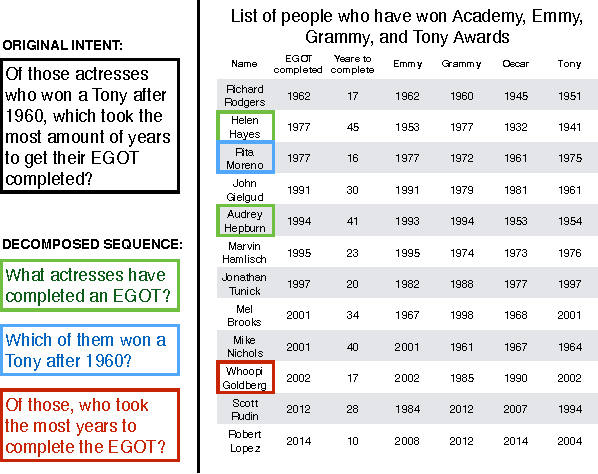
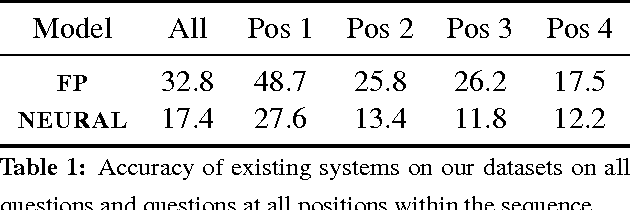
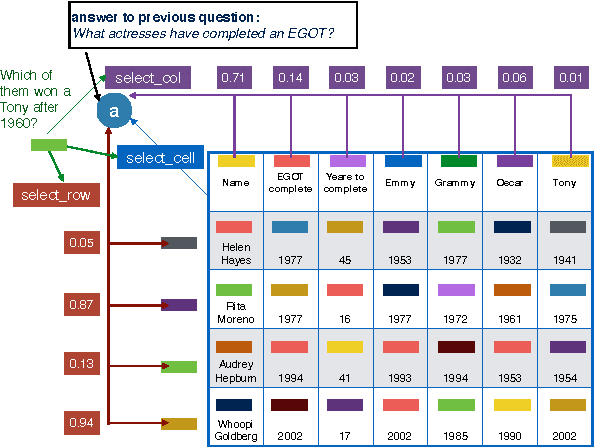

Recent work in semantic parsing for question answering has focused on long and complicated questions, many of which would seem unnatural if asked in a normal conversation between two humans. In an effort to explore a conversational QA setting, we present a more realistic task: answering sequences of simple but inter-related questions. We collect a dataset of 6,066 question sequences that inquire about semi-structured tables from Wikipedia, with 17,553 question-answer pairs in total. Existing QA systems face two major problems when evaluated on our dataset: (1) handling questions that contain coreferences to previous questions or answers, and (2) matching words or phrases in a question to corresponding entries in the associated table. We conclude by proposing strategies to handle both of these issues.