 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges of Feature Selection for Big Data Analytics
Nov 07, 2016
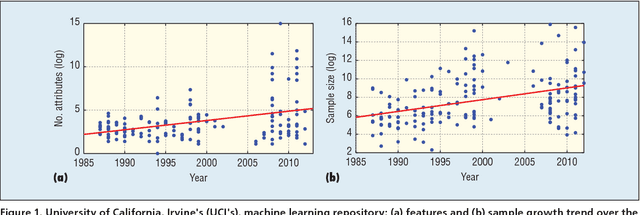
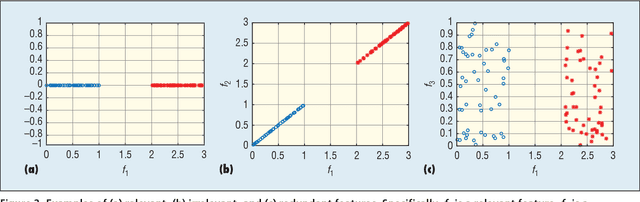
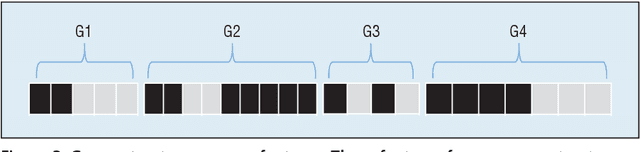
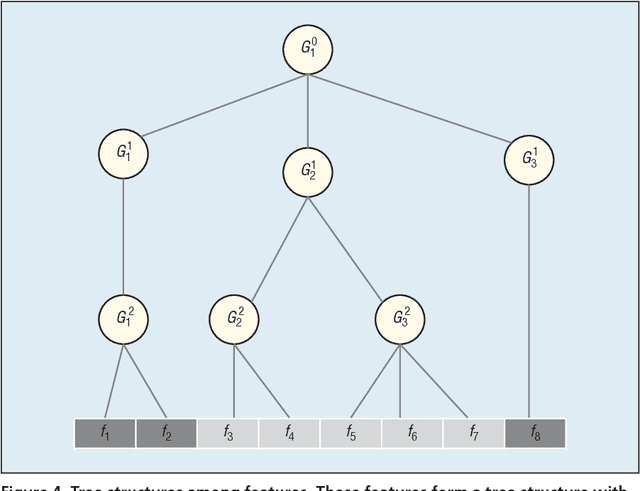
We are surrounded by huge amounts of large-scale high dimensional data. It is desirable to reduce the dimensionality of data for many learning tasks due to the curse of dimensionality. Feature selection has shown its effectiveness in many applications by building simpler and more comprehensive model, improving learning performance, and preparing clean, understandable data. Recently, some unique characteristics of big data such as data velocity and data variety present challenges to the feature selection problem. In this paper, we envision these challenges of feature selection for big data analytics. In particular, we first give a brief introduction about feature selection and then detail the challenges of feature selection for structured, heterogeneous and streaming data as well as its scalability and stability issues. At last, to facilitate and promote the feature selection research, we present an open-source feature selection repository (scikit-feature), which consists of most of current popular feature selection algorithms.