Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSong From PI: A Musically Plausible Network for Pop Music Generation
Nov 10, 2016
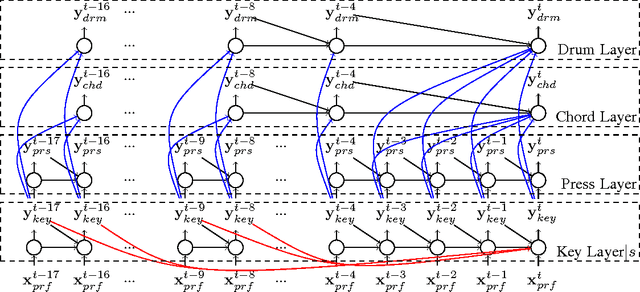


We present a novel framework for generating pop music. Our model is a hierarchical Recurrent Neural Network, where the layers and the structure of the hierarchy encode our prior knowledge about how pop music is composed. In particular, the bottom layers generate the melody, while the higher levels produce the drums and chords. We conduct several human studies that show strong preference of our generated music over that produced by the recent method by Google. We additionally show two applications of our framework: neural dancing and karaoke, as well as neural story singing.
* under review at ICLR 2017
View paper on
 OpenReview
OpenReview