 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Recognizing Human-Object Interactions
Mar 27, 2018



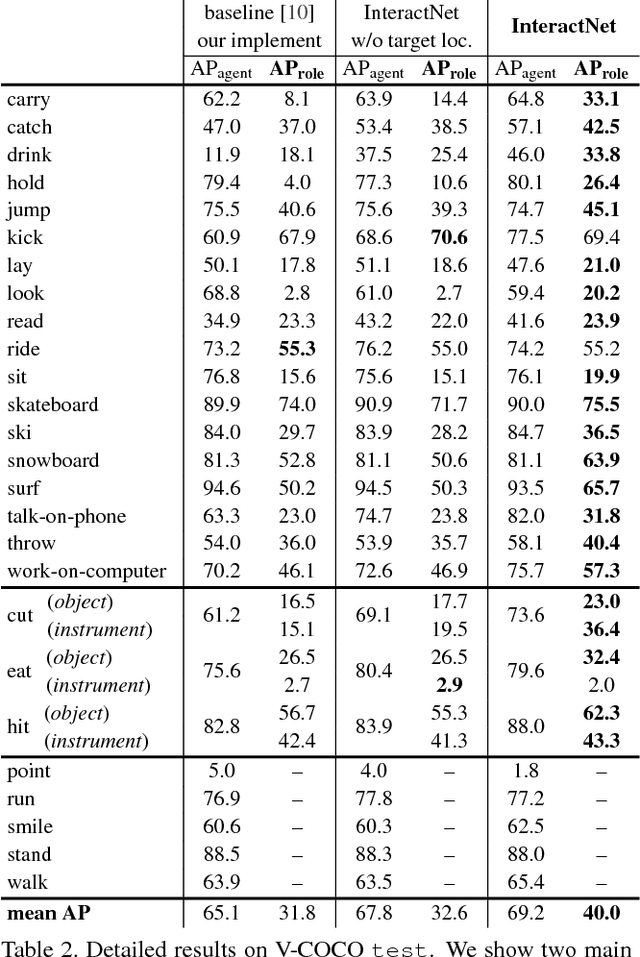
To understand the visual world, a machine must not only recognize individual object instances but also how they interact. Humans are often at the center of such interactions and detecting human-object interactions is an important practical and scientific problem. In this paper, we address the task of detecting <human, verb, object> triplets in challenging everyday photos. We propose a novel model that is driven by a human-centric approach. Our hypothesis is that the appearance of a person -- their pose, clothing, action -- is a powerful cue for localizing the objects they are interacting with. To exploit this cue, our model learns to predict an action-specific density over target object locations based on the appearance of a detected person. Our model also jointly learns to detect people and objects, and by fusing these predictions it efficiently infers interaction triplets in a clean, jointly trained end-to-end system we call InteractNet. We validate our approach on the recently introduced Verbs in COCO (V-COCO) and HICO-DET datasets, where we show quantitatively compelling results.