 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving One-Shot Learning through Fusing Side Information
Jan 23, 2018
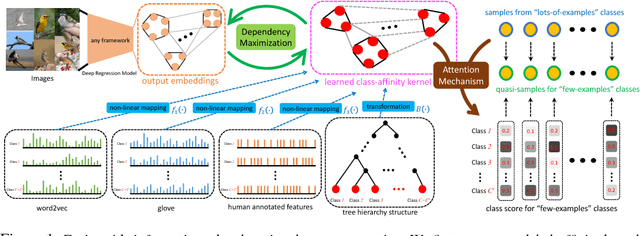

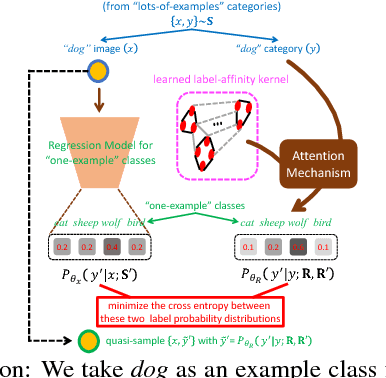
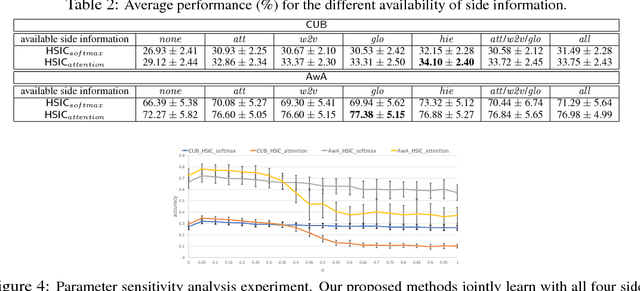
Deep Neural Networks (DNNs) often struggle with one-shot learning where we have only one or a few labeled training examples per category. In this paper, we argue that by using side information, we may compensate the missing information across classes. We introduce two statistical approaches for fusing side information into data representation learning to improve one-shot learning. First, we propose to enforce the statistical dependency between data representations and multiple types of side information. Second, we introduce an attention mechanism to efficiently treat examples belonging to the 'lots-of-examples' classes as quasi-samples (additional training samples) for 'one-example' classes. We empirically show that our learning architecture improves over traditional softmax regression networks as well as state-of-the-art attentional regression networks on one-shot recognition tasks.