 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Learning of Nonstationary Kernels for Natural Language Modeling
Feb 01, 2018
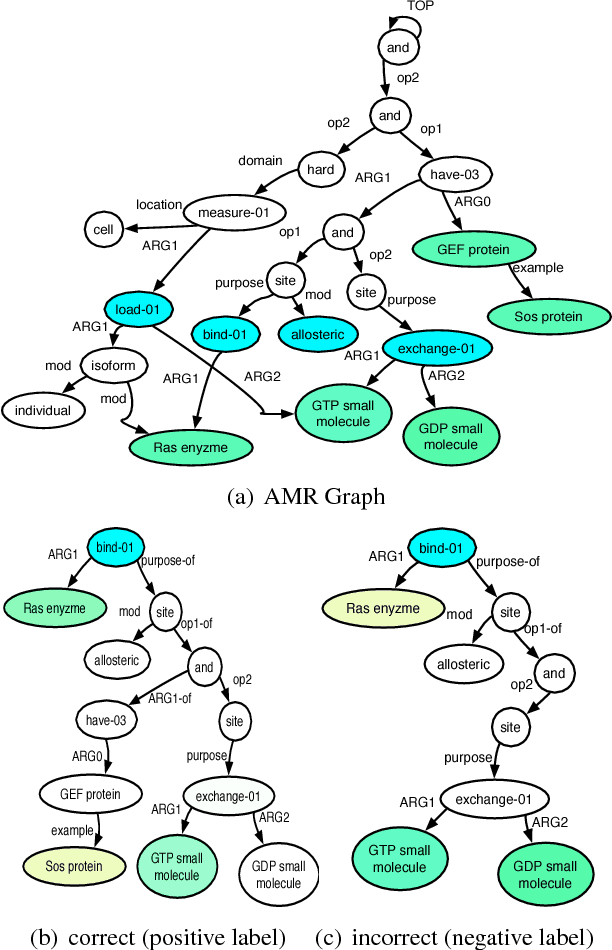
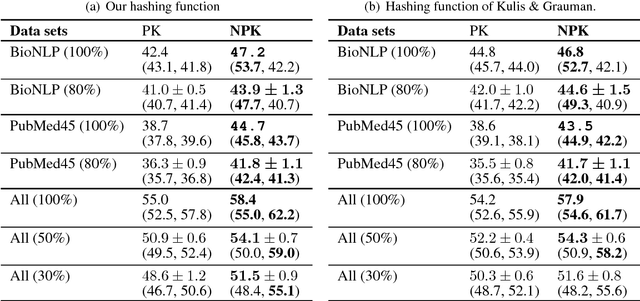
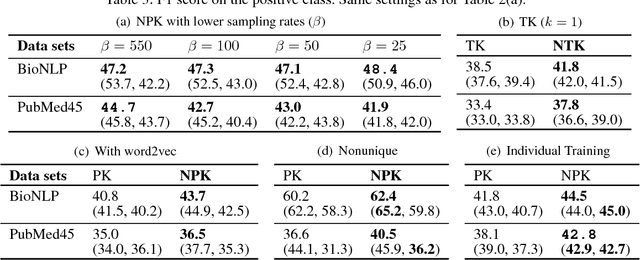
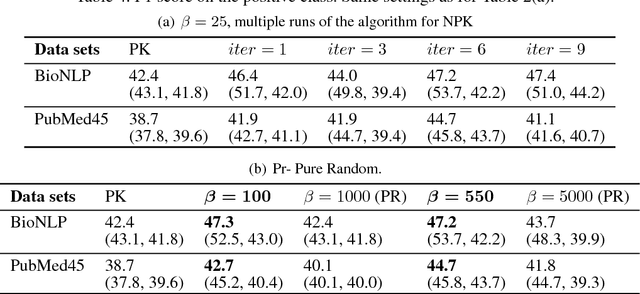
Natural language processing often involves computations with semantic or syntactic graphs to facilitate sophisticated reasoning based on structural relationships. While convolution kernels provide a powerful tool for comparing graph structure based on node (word) level relationships, they are difficult to customize and can be computationally expensive. We propose a generalization of convolution kernels, with a nonstationary model, for better expressibility of natural languages in supervised settings. For a scalable learning of the parameters introduced with our model, we propose a novel algorithm that leverages stochastic sampling on k-nearest neighbor graphs, along with approximations based on locality-sensitive hashing. We demonstrate the advantages of our approach on a challenging real-world (structured inference) problem of automatically extracting biological models from the text of scientific papers.