 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Stream Parallelization of Recurrent Neural Networks for Low Power and Fast Inference
Mar 30, 2018
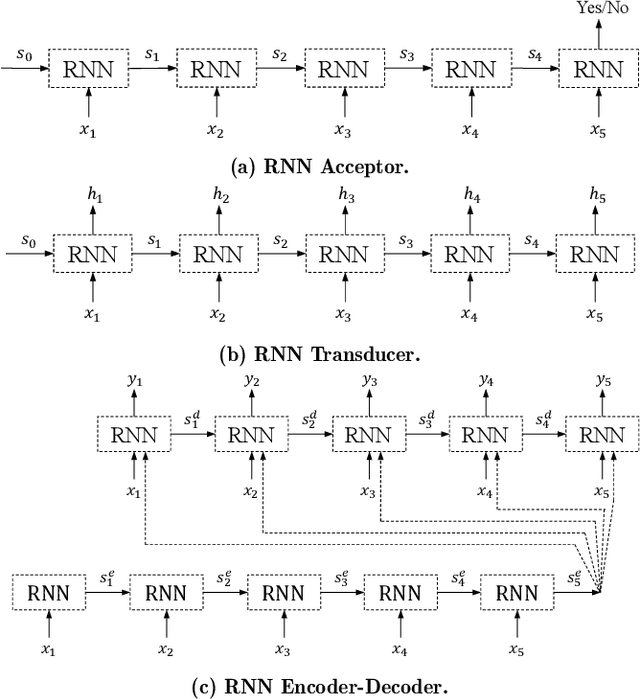
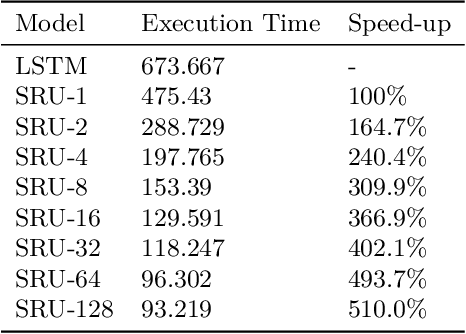
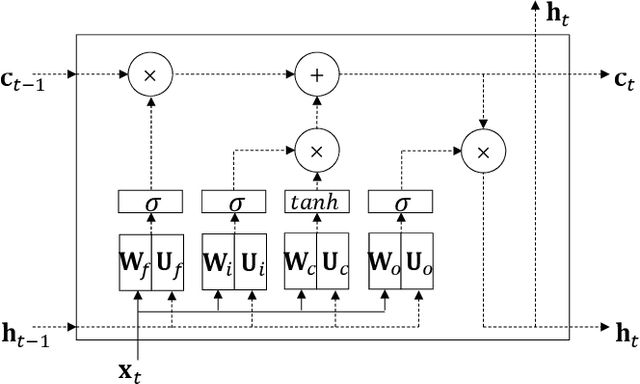
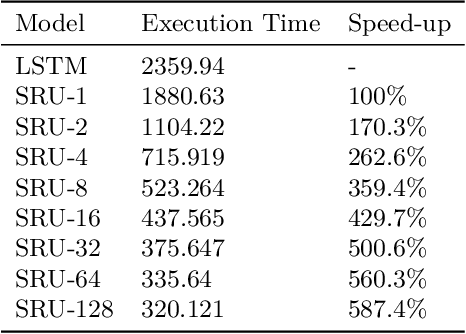
As neural network algorithms show high performance in many applications, their efficient inference on mobile and embedded systems are of great interests. When a single stream recurrent neural network (RNN) is executed for a personal user in embedded systems, it demands a large amount of DRAM accesses because the network size is usually much bigger than the cache size and the weights of an RNN are used only once at each time step. We overcome this problem by parallelizing the algorithm and executing it multiple time steps at a time. This approach also reduces the power consumption by lowering the number of DRAM accesses. QRNN (Quasi Recurrent Neural Networks) and SRU (Simple Recurrent Unit) based recurrent neural networks are used for implementation. The experiments for SRU showed about 300% and 930% of speed-up when the numbers of multi time steps are 4 and 16, respectively, in an ARM CPU based system.