Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining convolutional neural networks with megapixel images
Apr 16, 2018
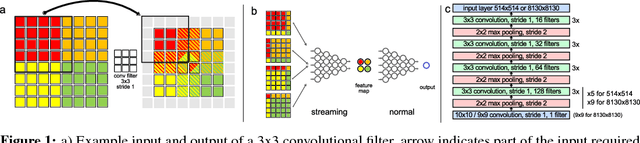
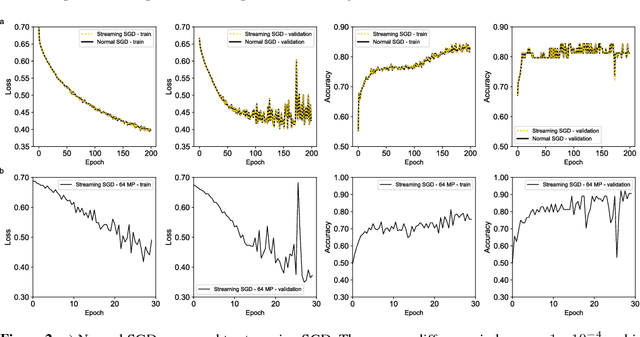
To train deep convolutional neural networks, the input data and the intermediate activations need to be kept in memory to calculate the gradient descent step. Given the limited memory available in the current generation accelerator cards, this limits the maximum dimensions of the input data. We demonstrate a method to train convolutional neural networks holding only parts of the image in memory while giving equivalent results. We quantitatively compare this new way of training convolutional neural networks with conventional training. In addition, as a proof of concept, we train a convolutional neural network with 64 megapixel images, which requires 97% less memory than the conventional approach.
* Submitted to MIDL 2018
View paper on