Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gammatone Frequency Cepstral Coefficients with Neural Networks for Emotion Recognition from Speech
Jun 23, 2018

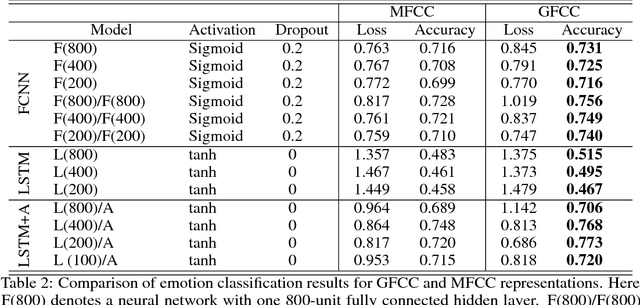
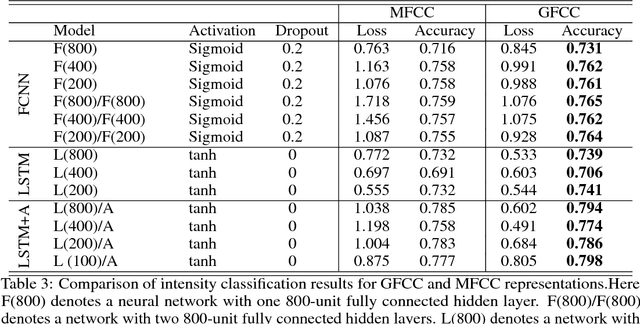
Current approaches to speech emotion recognition focus on speech features that can capture the emotional content of a speech signal. Mel Frequency Cepstral Coefficients (MFCCs) are one of the most commonly used representations for audio speech recognition and classification. This paper proposes Gammatone Frequency Cepstral Coefficients (GFCCs) as a potentially better representation of speech signals for emotion recognition. The effectiveness of MFCC and GFCC representations are compared and evaluated over emotion and intensity classification tasks with fully connected and recurrent neural network architectures. The results provide evidence that GFCCs outperform MFCCs in speech emotion recognition.
* 5 pages, 1 figure, 3 tables
View paper on