 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARNN: Linear Attention Recurrent Neural Network
Aug 16, 2018
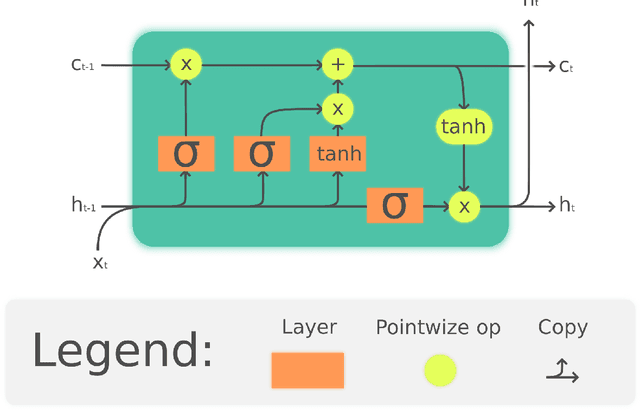
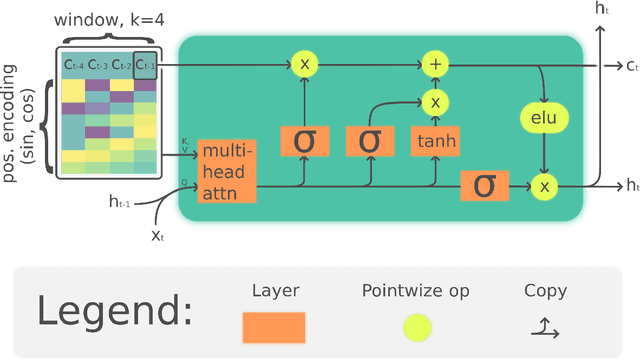

The Linear Attention Recurrent Neural Network (LARNN) is a recurrent attention module derived from the Long Short-Term Memory (LSTM) cell and ideas from the consciousness Recurrent Neural Network (RNN). Yes, it LARNNs. The LARNN uses attention on its past cell state values for a limited window size $k$. The formulas are also derived from the Batch Normalized LSTM (BN-LSTM) cell and the Transformer Network for its Multi-Head Attention Mechanism. The Multi-Head Attention Mechanism is used inside the cell such that it can query its own $k$ past values with the attention window. This has the effect of augmenting the rank of the tensor with the attention mechanism, such that the cell can perform complex queries to question its previous inner memories, which should augment the long short-term effect of the memory. With a clever trick, the LARNN cell with attention can be easily used inside a loop on the cell state, just like how any other Recurrent Neural Network (RNN) cell can be looped linearly through time series. This is due to the fact that its state, which is looped upon throughout time steps within time series, stores the inner states in a "first in, first out" queue which contains the $k$ most recent states and on which it is easily possible to add static positional encoding when the queue is represented as a tensor. This neural architecture yields better results than the vanilla LSTM cells. It can obtain results of 91.92% for the test accuracy, compared to the previously attained 91.65% using vanilla LSTM cells. Note that this is not to compare to other research, where up to 93.35% is obtained, but costly using 18 LSTM cells rather than with 2 to 3 cells as analyzed here. Finally, an interesting discovery is made, such that adding activation within the multi-head attention mechanism's linear layers can yield better results in the context researched hereto.