 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlowFast Networks for Video Recognition
Dec 10, 2018
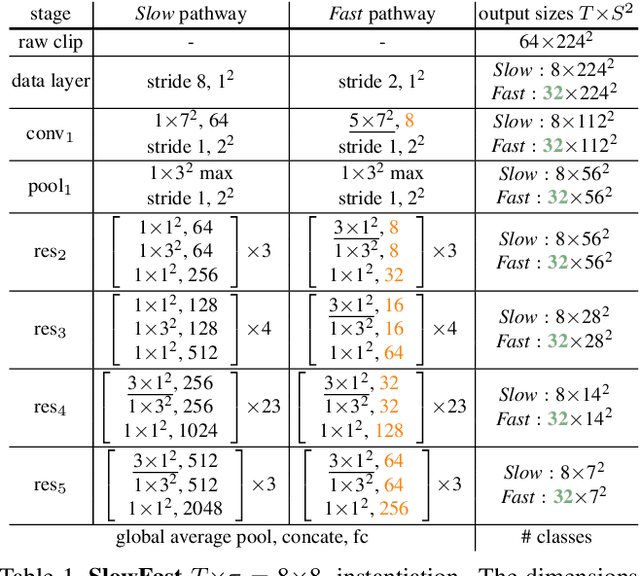

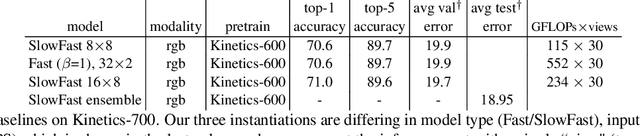
We present SlowFast networks for video recognition. Our model involves (i) a Slow pathway, operating at low frame rate, to capture spatial semantics, and (ii) a Fast pathway, operating at high frame rate, to capture motion at fine temporal resolution. The Fast pathway can be made very lightweight by reducing its channel capacity, yet can learn useful temporal information for video recognition. Our models achieve strong performance for both action classification and detection in video, and large improvements are pin-pointed as contributions by our SlowFast concept. We report 79.0% accuracy on the Kinetics dataset without using any pre-training, largely surpassing the previous best results of this kind. On AVA action detection we achieve a new state-of-the-art of 28.3 mAP. Code will be made publicly available.