 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Walk via Deep Reinforcement Learning
Dec 26, 2018

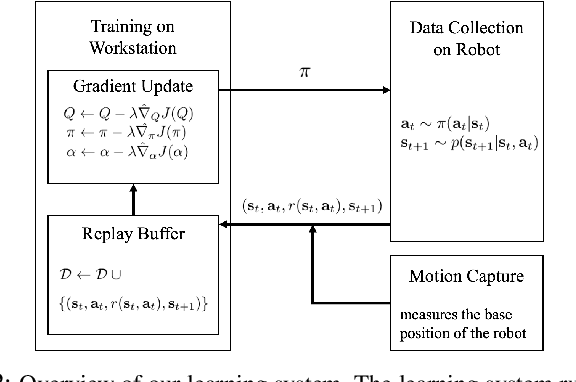
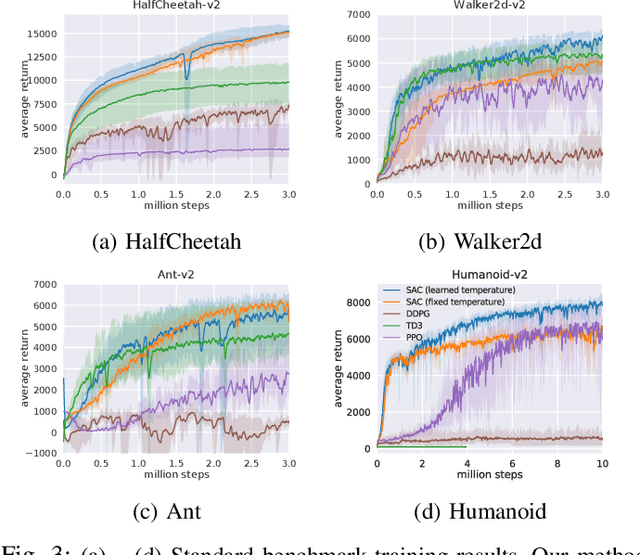
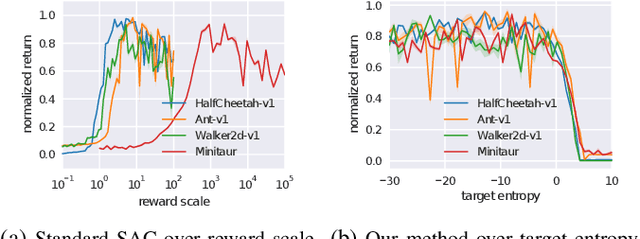
Deep reinforcement learning suggests the promise of fully automated learning of robotic control policies that directly map sensory inputs to low-level actions. However, applying deep reinforcement learning methods on real-world robots is exceptionally difficult, due both to the sample complexity and, just as importantly, the sensitivity of such methods to hyperparameters. While hyperparameter tuning can be performed in parallel in simulated domains, it is usually impractical to tune hyperparameters directly on real-world robotic platforms, especially legged platforms like quadrupedal robots that can be damaged through extensive trial-and-error learning. In this paper, we develop a stable variant of the soft actor-critic deep reinforcement learning algorithm that requires minimal hyperparameter tuning, while also requiring only a modest number of trials to learn multilayer neural network policies. This algorithm is based on the framework of maximum entropy reinforcement learning, and automatically trades off exploration against exploitation by dynamically and automatically tuning a temperature parameter that determines the stochasticity of the policy. We show that this method achieves state-of-the-art performance on four standard benchmark environments. We then demonstrate that it can be used to learn quadrupedal locomotion gaits on a real-world Minitaur robot, learning to walk from scratch directly in the real world in two hours of training.