 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMICIK: MIning Cross-Layer Inherent Similarity Knowledge for Deep Model Compression
Feb 03, 2019
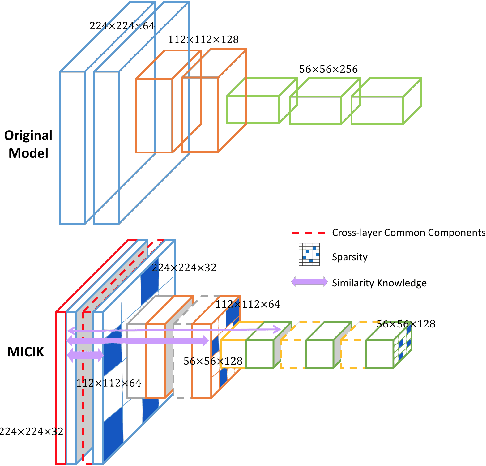

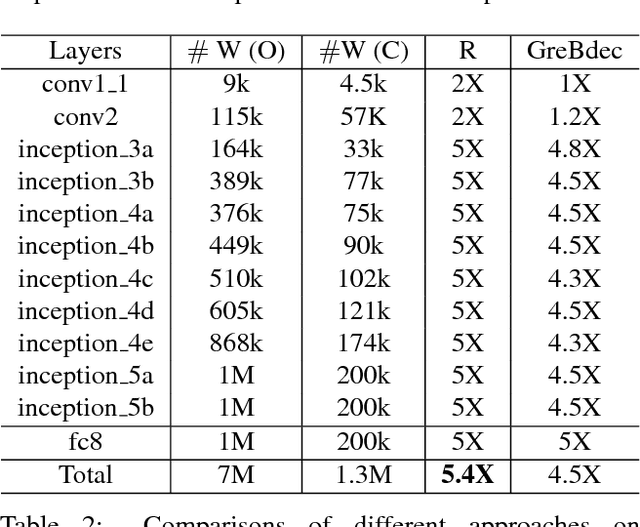
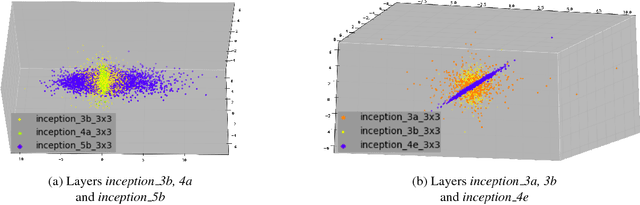
State-of-the-art deep model compression methods exploit the low-rank approximation and sparsity pruning to remove redundant parameters from a learned hidden layer. However, they process each hidden layer individually while neglecting the common components across layers, and thus are not able to fully exploit the potential redundancy space for compression. To solve the above problem and enable further compression of a model, removing the cross-layer redundancy and mining the layer-wise inheritance knowledge is necessary. In this paper, we introduce a holistic model compression framework, namely MIning Cross-layer Inherent similarity Knowledge (MICIK), to fully excavate the potential redundancy space. The proposed MICIK framework simultaneously, (1) learns the common and unique weight components across deep neural network layers to increase compression rate; (2) preserves the inherent similarity knowledge of nearby layers and distant layers to minimize the accuracy loss and (3) can be complementary to other existing compression techniques such as knowledge distillation. Extensive experiments on large-scale convolutional neural networks demonstrate that MICIK is superior over state-of-the-art model compression approaches with 16X parameter reduction on VGG-16 and 6X on GoogLeNet, all without accuracy loss.