 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKT-Speech-Crawler: Automatic Dataset Construction for Speech Recognition from YouTube Videos
Mar 01, 2019
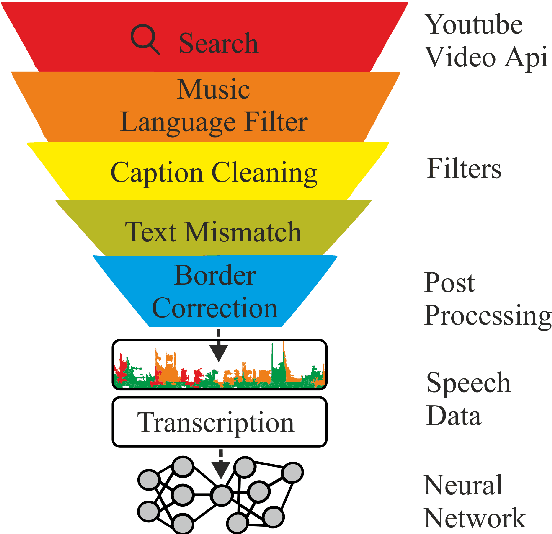
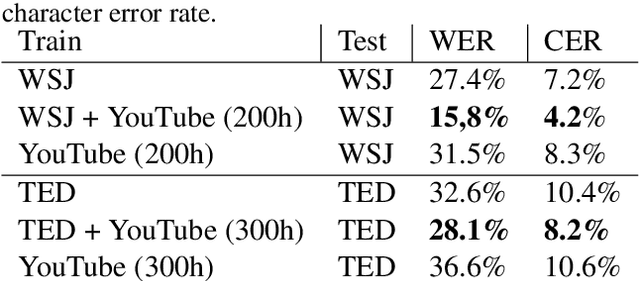
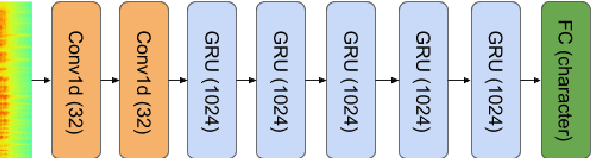
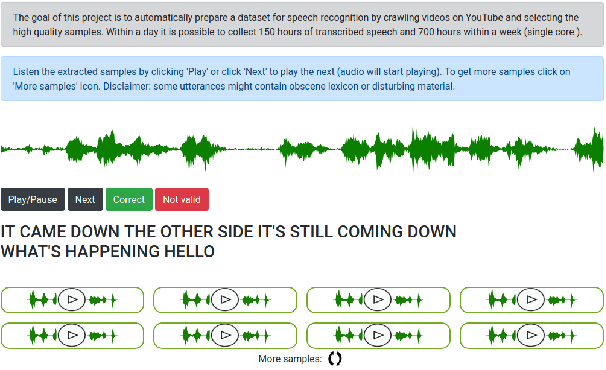
In this paper, we describe KT-Speech-Crawler: an approach for automatic dataset construction for speech recognition by crawling YouTube videos. We outline several filtering and post-processing steps, which extract samples that can be used for training end-to-end neural speech recognition systems. In our experiments, we demonstrate that a single-core version of the crawler can obtain around 150 hours of transcribed speech within a day, containing an estimated 3.5% word error rate in the transcriptions. Automatically collected samples contain reading and spontaneous speech recorded in various conditions including background noise and music, distant microphone recordings, and a variety of accents and reverberation. When training a deep neural network on speech recognition, we observed around 40\% word error rate reduction on the Wall Street Journal dataset by integrating 200 hours of the collected samples into the training set. The demo (http://emnlp-demo.lakomkin.me/) and the crawler code (https://github.com/EgorLakomkin/KTSpeechCrawler) are publicly available.