 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Regularized Reinforcement Learning
Mar 02, 2019
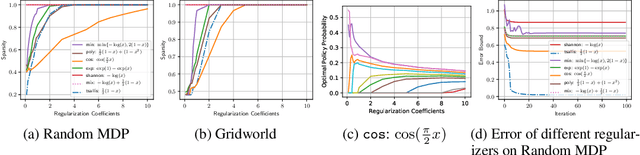
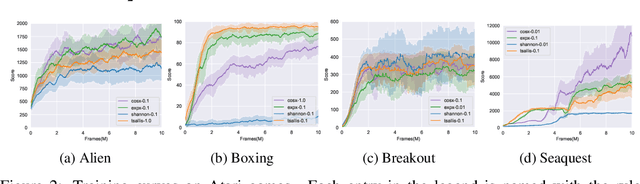
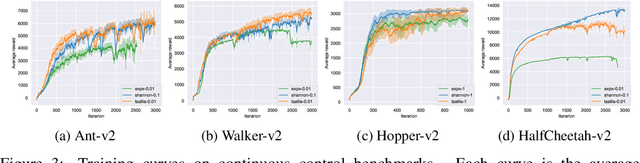
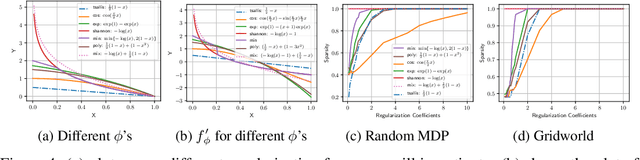
We propose and study a general framework for regularized Markov decision processes (MDPs) where the goal is to find an optimal policy that maximizes the expected discounted total reward plus a policy regularization term. The extant entropy-regularized MDPs can be cast into our framework. Moreover, under our framework there are many regularization terms can bring multi-modality and sparsity which are potentially useful in reinforcement learning. In particular, we present sufficient and necessary conditions that induce a sparse optimal policy. We also conduct a full mathematical analysis of the proposed regularized MDPs, including the optimality condition, performance error and sparseness control. We provide a generic method to devise regularization forms and propose off-policy actor-critic algorithms in complex environment settings. We empirically analyze the statistical properties of optimal policies and compare the performance of different sparse regularization forms in discrete and continuous environments.