Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Adaptive Acceleration for Optimization
Mar 04, 2019
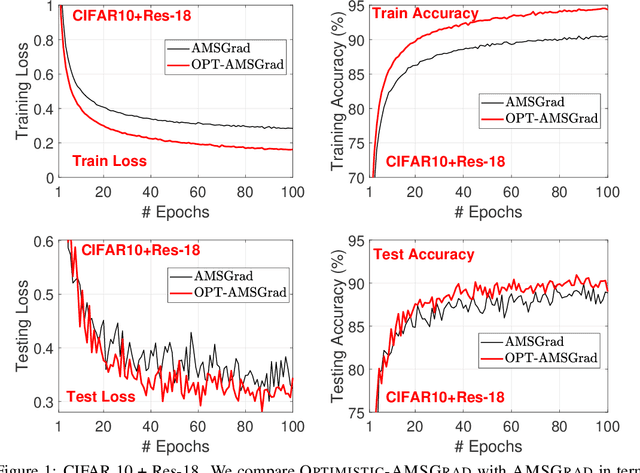
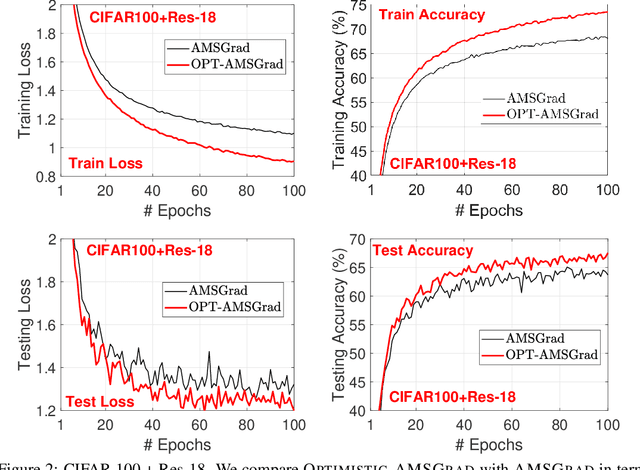
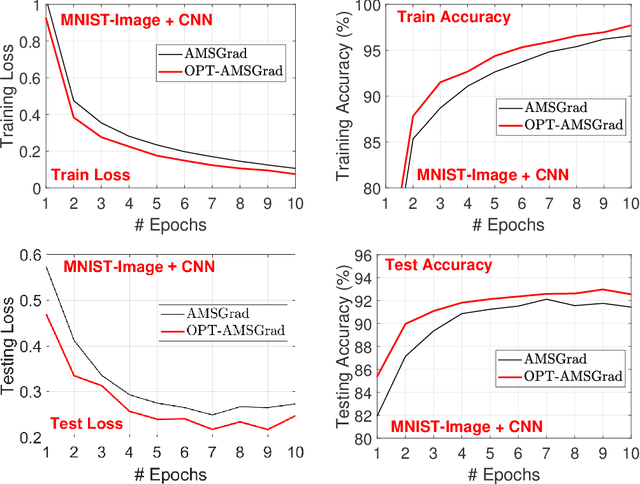
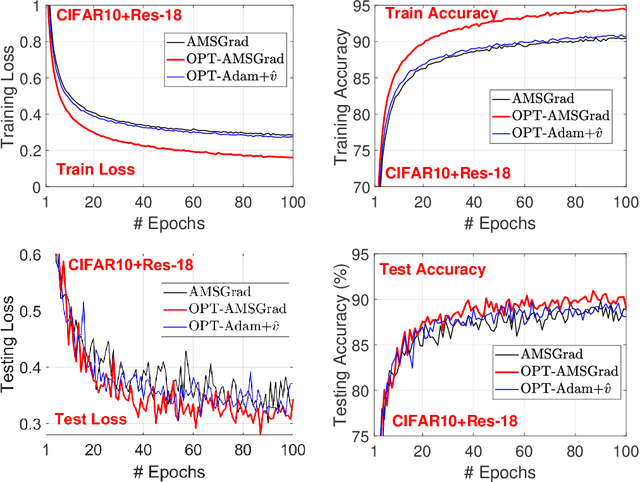
We consider a new variant of \textsc{AMSGrad}. AMSGrad \cite{RKK18} is a popular adaptive gradient based optimization algorithm that is widely used in training deep neural networks. Our new variant of the algorithm assumes that mini-batch gradients in consecutive iterations have some underlying structure, which makes the gradients sequentially predictable. By exploiting the predictability and some ideas from the field of \textsc{Optimistic Online learning}, the new algorithm can accelerate the convergence and enjoy a tighter regret bound. We conduct experiments on training various neural networks on several datasets to show that the proposed method speeds up the convergence in practice.
View paper on
 OpenReview
OpenReview