 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Mimicking: Better Word Embeddings by Attending to Informative Contexts
Apr 05, 2019
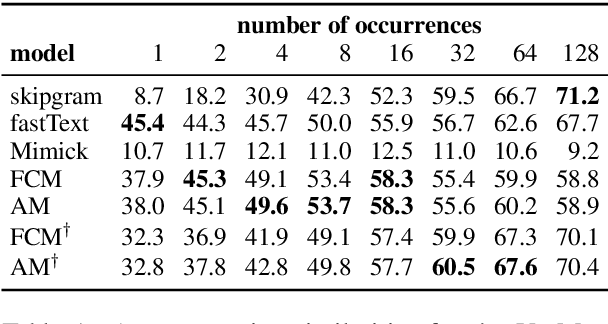
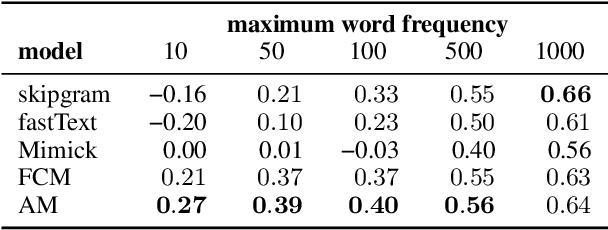
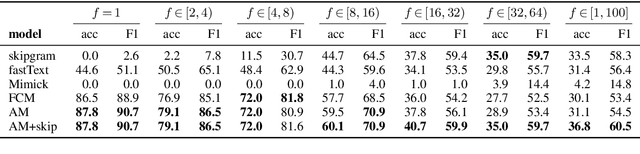
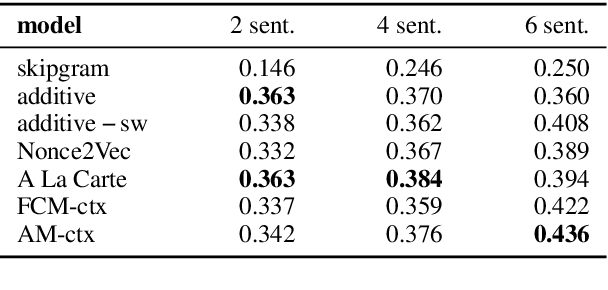
Learning high-quality embeddings for rare words is a hard problem because of sparse context information. Mimicking (Pinter et al., 2017) has been proposed as a solution: given embeddings learned by a standard algorithm, a model is first trained to reproduce embeddings of frequent words from their surface form and then used to compute embeddings for rare words. In this paper, we introduce attentive mimicking: the mimicking model is given access not only to a word's surface form, but also to all available contexts and learns to attend to the most informative and reliable contexts for computing an embedding. In an evaluation on four tasks, we show that attentive mimicking outperforms previous work for both rare and medium-frequency words. Thus, compared to previous work, attentive mimicking improves embeddings for a much larger part of the vocabulary, including the medium-frequency range.