 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Gradient Algorithms Have No Guarantees of Convergence in Continuous Action and State Multi-Agent Settings
Jul 08, 2019
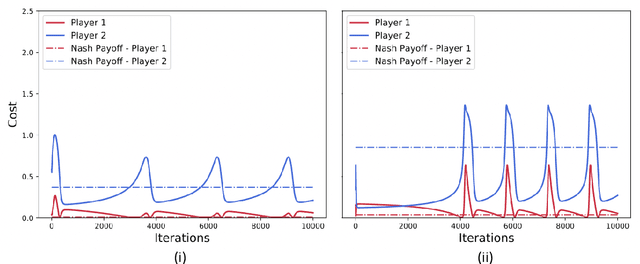
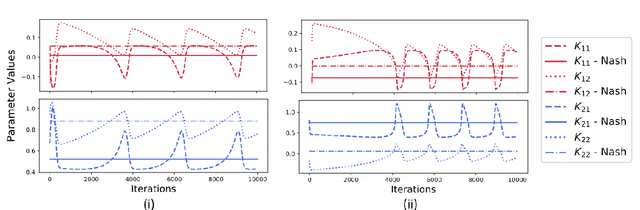
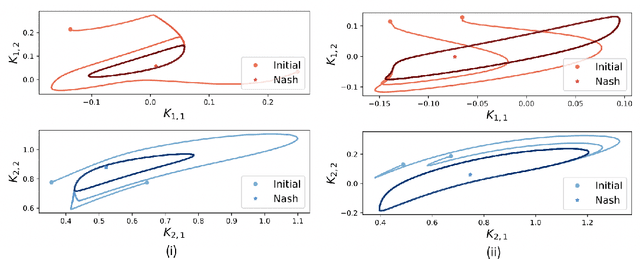
We show by counterexample that policy-gradient algorithms have no guarantees of even local convergence to Nash equilibria in continuous action and state space multi-agent settings. To do so, we analyze gradient-play in $N$-player general-sum linear quadratic games. In such games the state and action spaces are continuous and the unique global Nash equilibrium can be found be solving coupled Ricatti equations. Further, gradient-play in LQ games is equivalent to multi-agent policy gradient. We first prove that the only critical point of the gradient dynamics in these games is the unique global Nash equilibrium. We then give sufficient conditions under which policy gradient will avoid the Nash equilibrium, and generate a large number of general-sum linear quadratic games that satisfy these conditions. The existence of such games indicates that one of the most popular approaches to solving reinforcement learning problems in the classic reinforcement learning setting has no guarantee of convergence in multi-agent settings. Further, the ease with which we can generate these counterexamples suggests that such situations are not mere edge cases and are in fact quite common.