 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge scale continuous-time mean-variance portfolio allocation via reinforcement learning
Jul 26, 2019
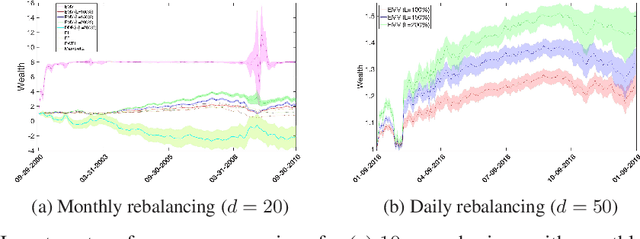
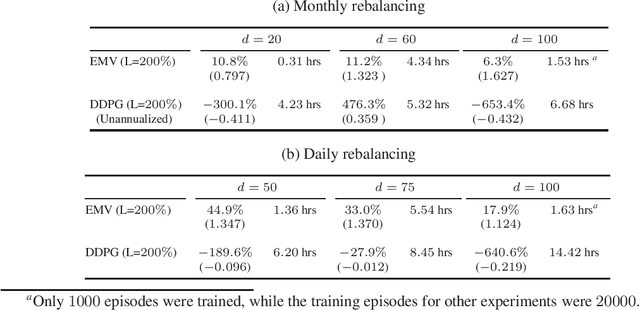
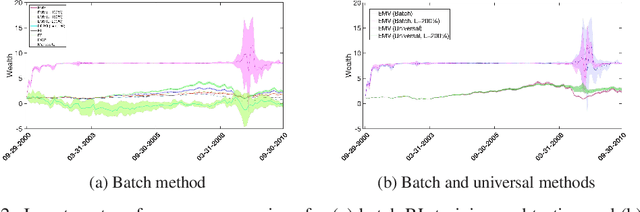
We propose to solve large scale Markowitz mean-variance (MV) portfolio allocation problem using reinforcement learning (RL). By adopting the recently developed continuous-time exploratory control framework, we formulate the exploratory MV problem in high dimensions. We further show the optimality of a multivariate Gaussian feedback policy, with time-decaying variance, in trading off exploration and exploitation. Based on a provable policy improvement theorem, we devise a scalable and data-efficient RL algorithm and conduct large scale empirical tests using data from the S&P 500 stocks. We found that our method consistently achieves over 10% annualized returns and it outperforms econometric methods and the deep RL method by large margins, for both long and medium terms of investment with monthly and daily trading.