 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Chatbots Using Clustered Actions and Human-Likeness Rewards
Aug 27, 2019
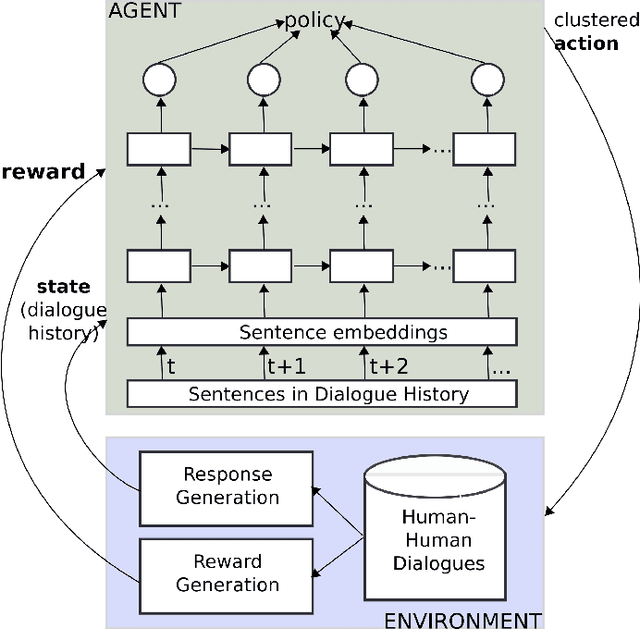
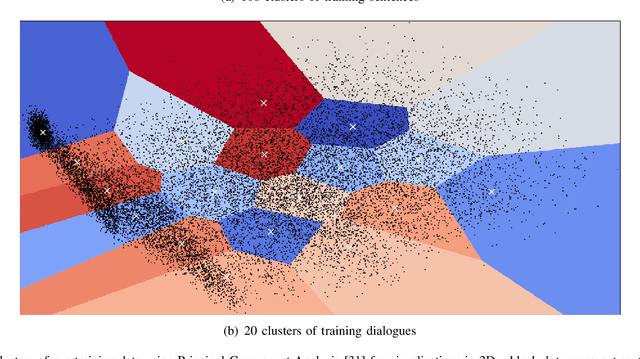
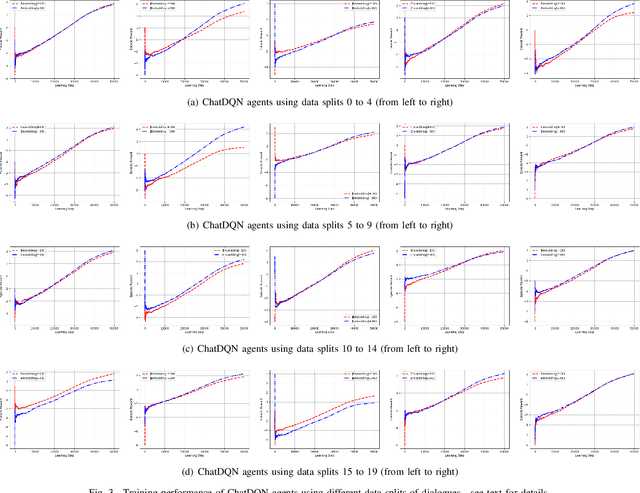
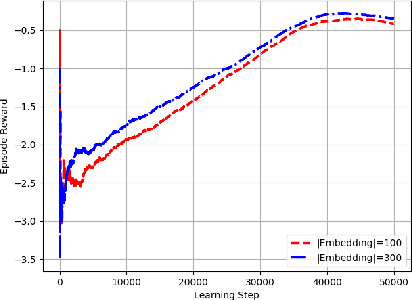
Training chatbots using the reinforcement learning paradigm is challenging due to high-dimensional states, infinite action spaces and the difficulty in specifying the reward function. We address such problems using clustered actions instead of infinite actions, and a simple but promising reward function based on human-likeness scores derived from human-human dialogue data. We train Deep Reinforcement Learning (DRL) agents using chitchat data in raw text---without any manual annotations. Experimental results using different splits of training data report the following. First, that our agents learn reasonable policies in the environments they get familiarised with, but their performance drops substantially when they are exposed to a test set of unseen dialogues. Second, that the choice of sentence embedding size between 100 and 300 dimensions is not significantly different on test data. Third, that our proposed human-likeness rewards are reasonable for training chatbots as long as they use lengthy dialogue histories of >=10 sentences.