 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMO-SPEECH: End-to-End Multi-Channel Multi-Speaker Speech Recognition
Oct 16, 2019
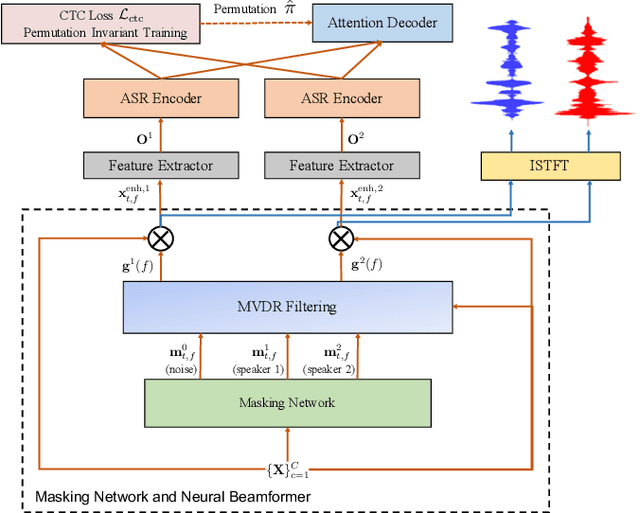
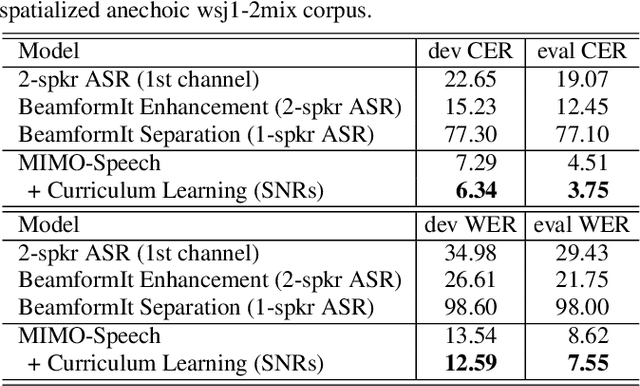
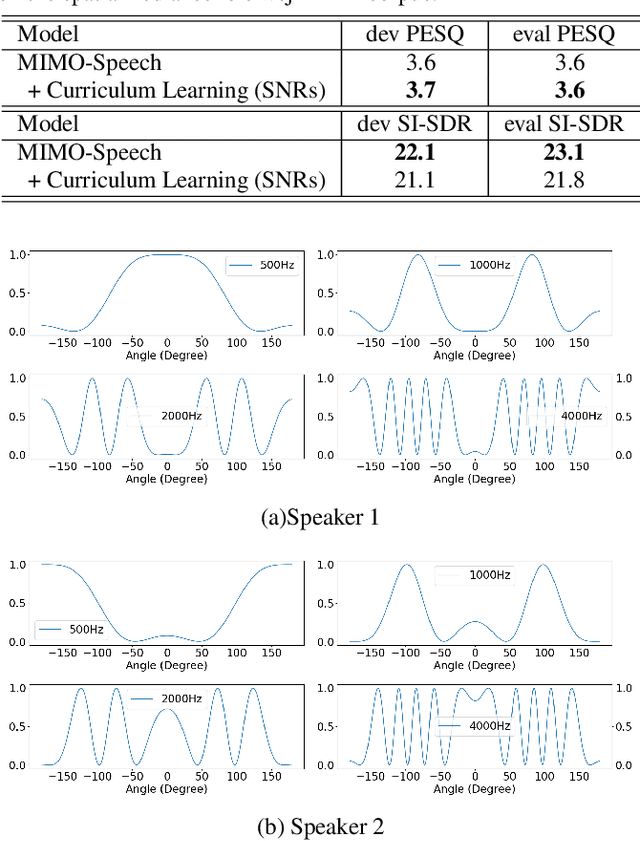
Recently, the end-to-end approach has proven its efficacy in monaural multi-speaker speech recognition. However, high word error rates (WERs) still prevent these systems from being used in practical applications. On the other hand, the spatial information in multi-channel signals has proven helpful in far-field speech recognition tasks. In this work, we propose a novel neural sequence-to-sequence (seq2seq) architecture, MIMO-Speech, which extends the original seq2seq to deal with multi-channel input and multi-channel output so that it can fully model multi-channel multi-speaker speech separation and recognition. MIMO-Speech is a fully neural end-to-end framework, which is optimized only via an ASR criterion. It is comprised of: 1) a monaural masking network, 2) a multi-source neural beamformer, and 3) a multi-output speech recognition model. With this processing, the input overlapped speech is directly mapped to text sequences. We further adopted a curriculum learning strategy, making the best use of the training set to improve the performance. The experiments on the spatialized wsj1-2mix corpus show that our model can achieve more than 60% WER reduction compared to the single-channel system with high quality enhanced signals (SI-SDR = 23.1 dB) obtained by the above separation function.