 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring neural speech waveform synthesizers to musical instrument sounds generation
Oct 27, 2019
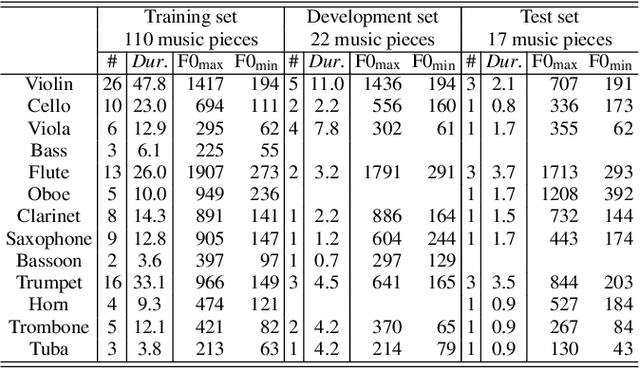
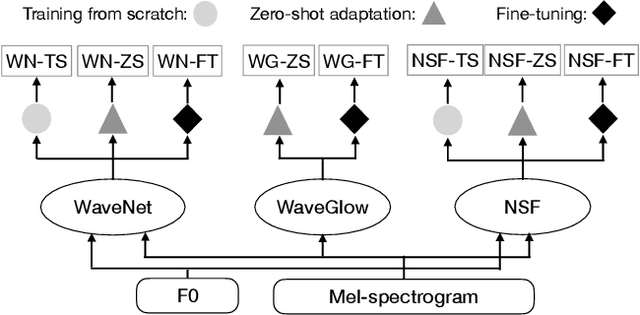
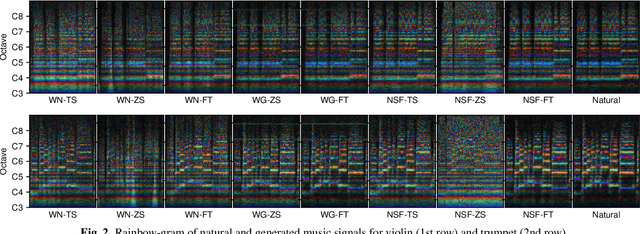
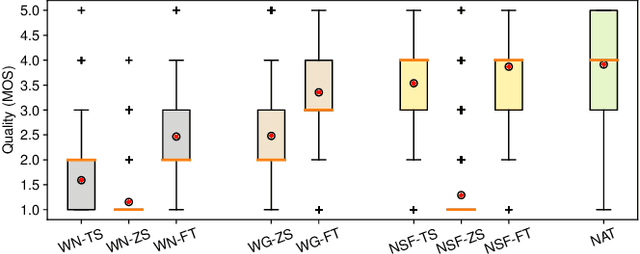
Recent neural waveform synthesizers such as WaveNet, WaveGlow, and the neural-source-filter (NSF) model have shown good performance in speech synthesis despite their different methods of waveform generation. The similarity between speech and music audio synthesis techniques suggests interesting avenues to explore in terms of the best way to apply speech synthesizers in the music domain. This work compares three neural synthesizers used for musical instrument sounds generation under three scenarios: training from scratch on music data, zero-shot learning from the speech domain, and fine-tuning-based adaptation from the speech to the music domain. The results of a large-scale perceptual test demonstrated that the performance of three synthesizers improved when they were pre-trained on speech data and fine-tuned on music data, which indicates the usefulness of knowledge from speech data for music audio generation. Among the synthesizers, WaveGlow showed the best potential in zero-shot learning while NSF performed best in the other scenarios and could generate samples that were perceptually close to natural audio.