 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotional Voice Conversion using multitask learning with Text-to-speech
Nov 11, 2019
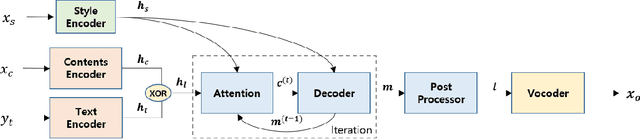

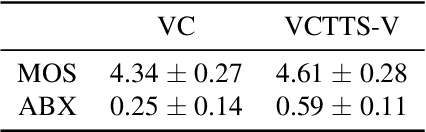
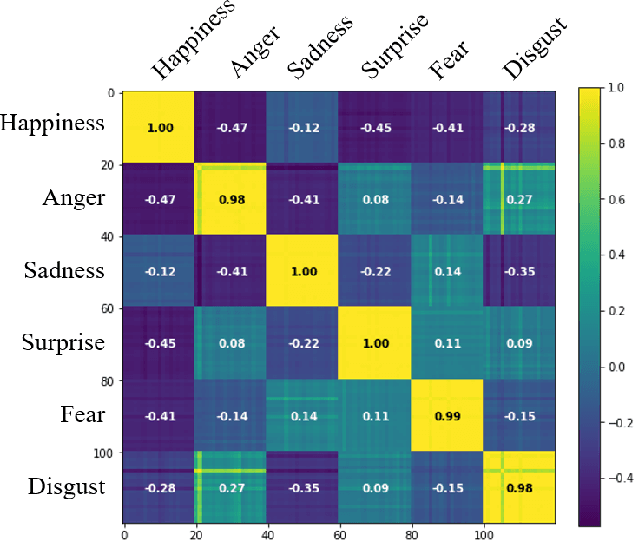
Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.