 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinating Statistical Moment and Subspace Descriptors from Object and Saliency Detectors for Action Recognition
Jan 14, 2020

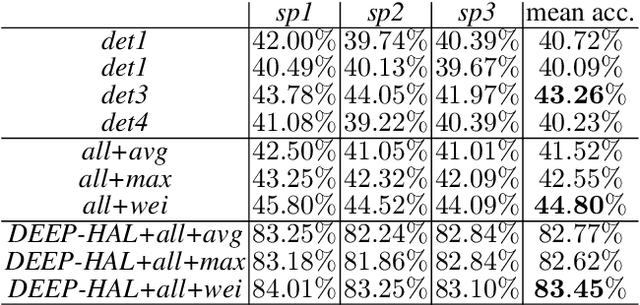


In this paper, we build on a deep translational action recognition network which takes RGB frames as input to learn to predict both action concepts and auxiliary supervisory feature descriptors e.g., Optical Flow Features and/or Improved Dense Trajectory descriptors. The translation is performed by so-called hallucination streams trained to predict auxiliary cues which are simultaneously fed into classification layers, and then hallucinated for free at the testing stage to boost recognition. In this paper, we design and hallucinate two descriptors, one leveraging four popular object detectors applied to training videos, and the other leveraging image- and video-level saliency detectors. The first descriptor encodes the detector- and ImageNet-wise class prediction scores, confidence scores, and spatial locations of bounding boxes and frame indexes to capture the spatio-temporal distribution of features per video. Another descriptor encodes spatio-angular gradient distributions of saliency maps and intensity patterns. Inspired by the characteristic function of the probability distribution, we capture four statistical moments on the above intermediate descriptors. As numbers of coefficients in the mean, covariance, coskewness and cokurtotsis grow linearly, quadratically, cubically and quartically w.r.t. the dimension of feature vectors, we describe the covariance matrix by its leading n' eigenvectors (so-called subspace) and we capture skewness/kurtosis rather than costly coskewness/cokurtosis. We obtain state of the art on three popular datasets.