


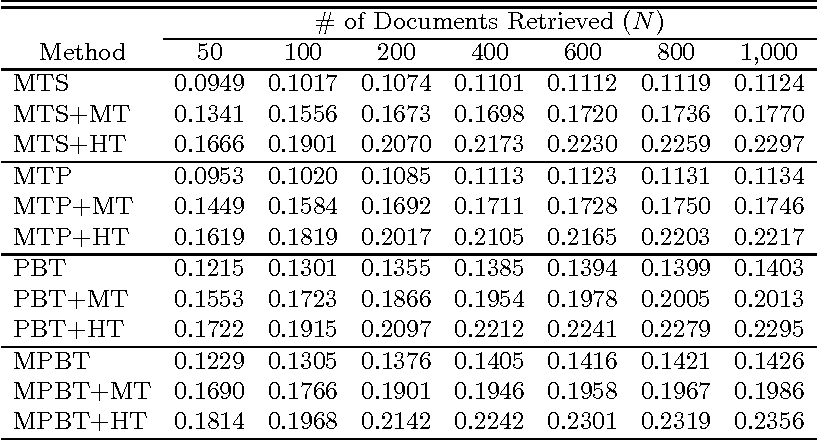
Cross-language information retrieval (CLIR), where queries and documents are in different languages, needs a translation of queries and/or documents, so as to standardize both of them into a common representation. For this purpose, the use of machine translation is an effective approach. However, computational cost is prohibitive in translating large-scale document collections. To resolve this problem, we propose a two-stage CLIR method. First, we translate a given query into the document language, and retrieve a limited number of foreign documents. Second, we machine translate only those documents into the user language, and re-rank them based on the translation result. We also show the effectiveness of our method by way of experiments using Japanese queries and English technical documents.
🔥 Discover incredible developments in machine intelligence
🤖 Quickly get code for any ML model
🔑 Get help from authors, engineers & researchers
 Add to Chrome
Add to Chrome
 Add to Firefox
Add to Firefox