


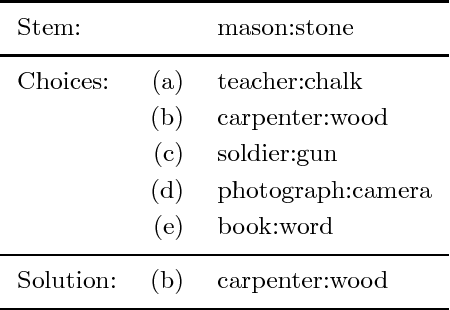
We present an algorithm for learning from unlabeled text, based on the Vector Space Model (VSM) of information retrieval, that can solve verbal analogy questions of the kind found in the SAT college entrance exam. A verbal analogy has the form A:B::C:D, meaning "A is to B as C is to D"; for example, mason:stone::carpenter:wood. SAT analogy questions provide a word pair, A:B, and the problem is to select the most analogous word pair, C:D, from a set of five choices. The VSM algorithm correctly answers 47% of a collection of 374 college-level analogy questions (random guessing would yield 20% correct; the average college-bound senior high school student answers about 57% correctly). We motivate this research by applying it to a difficult problem in natural language processing, determining semantic relations in noun-modifier pairs. The problem is to classify a noun-modifier pair, such as "laser printer", according to the semantic relation between the noun (printer) and the modifier (laser). We use a supervised nearest-neighbour algorithm that assigns a class to a given noun-modifier pair by finding the most analogous noun-modifier pair in the training data. With 30 classes of semantic relations, on a collection of 600 labeled noun-modifier pairs, the learning algorithm attains an F value of 26.5% (random guessing: 3.3%). With 5 classes of semantic relations, the F value is 43.2% (random: 20%). The performance is state-of-the-art for both verbal analogies and noun-modifier relations.
🔥 Discover incredible developments in machine intelligence
🤖 Quickly get code for any ML model
🔑 Get help from authors, engineers & researchers
 Add to Chrome
Add to Chrome
 Add to Firefox
Add to Firefox