 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
TimeCSL: Unsupervised Contrastive Learning of General Shapelets for Explorable Time Series Analysis
Apr 07, 2024
Unsupervised (a.k.a. Self-supervised) representation learning (URL) has emerged as a new paradigm for time series analysis, because it has the ability to learn generalizable time series representation beneficial for many downstream tasks without using labels that are usually difficult to obtain. Considering that existing approaches have limitations in the design of the representation encoder and the learning objective, we have proposed Contrastive Shapelet Learning (CSL), the first URL method that learns the general-purpose shapelet-based representation through unsupervised contrastive learning, and shown its superior performance in several analysis tasks, such as time series classification, clustering, and anomaly detection. In this paper, we develop TimeCSL, an end-to-end system that makes full use of the general and interpretable shapelets learned by CSL to achieve explorable time series analysis in a unified pipeline. We introduce the system components and demonstrate how users interact with TimeCSL to solve different analysis tasks in the unified pipeline, and gain insight into their time series by exploring the learned shapelets and representation.
Foundation Models for Time Series Analysis: A Tutorial and Survey
Mar 21, 2024Time series analysis stands as a focal point within the data mining community, serving as a cornerstone for extracting valuable insights crucial to a myriad of real-world applications. Recent advancements in Foundation Models (FMs) have fundamentally reshaped the paradigm of model design for time series analysis, boosting various downstream tasks in practice. These innovative approaches often leverage pre-trained or fine-tuned FMs to harness generalized knowledge tailored specifically for time series analysis. In this survey, we aim to furnish a comprehensive and up-to-date overview of FMs for time series analysis. While prior surveys have predominantly focused on either the application or the pipeline aspects of FMs in time series analysis, they have often lacked an in-depth understanding of the underlying mechanisms that elucidate why and how FMs benefit time series analysis. To address this gap, our survey adopts a model-centric classification, delineating various pivotal elements of time-series FMs, including model architectures, pre-training techniques, adaptation methods, and data modalities. Overall, this survey serves to consolidate the latest advancements in FMs pertinent to time series analysis, accentuating their theoretical underpinnings, recent strides in development, and avenues for future research exploration.
Caformer: Rethinking Time Series Analysis from Causal Perspective
Mar 13, 2024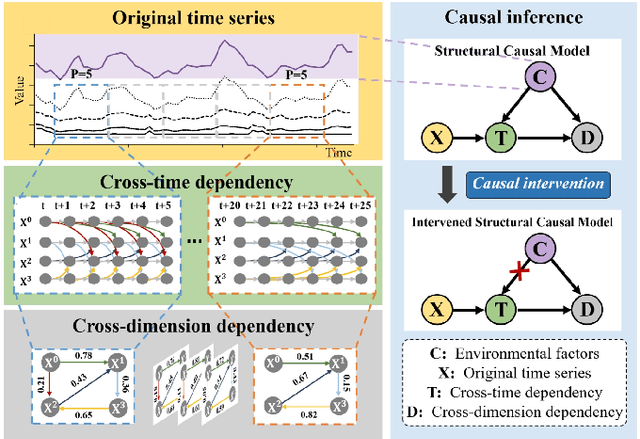
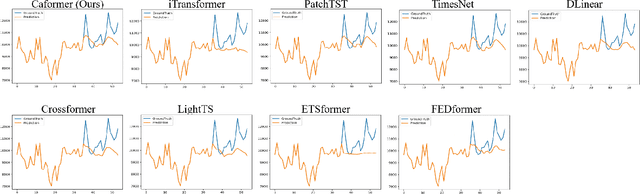
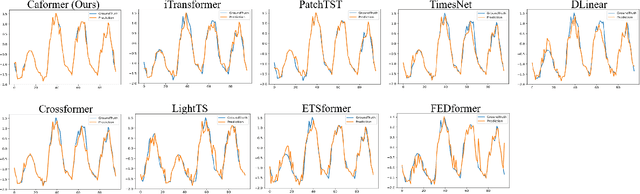
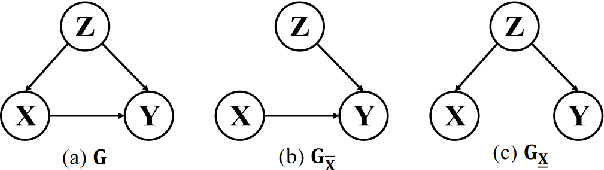
Time series analysis is a vital task with broad applications in various domains. However, effectively capturing cross-dimension and cross-time dependencies in non-stationary time series poses significant challenges, particularly in the context of environmental factors. The spurious correlation induced by the environment confounds the causal relationships between cross-dimension and cross-time dependencies. In this paper, we introduce a novel framework called Caformer (\underline{\textbf{Ca}}usal Trans\underline{\textbf{former}}) for time series analysis from a causal perspective. Specifically, our framework comprises three components: Dynamic Learner, Environment Learner, and Dependency Learner. The Dynamic Learner unveils dynamic interactions among dimensions, the Environment Learner mitigates spurious correlations caused by environment with a back-door adjustment, and the Dependency Learner aims to infer robust interactions across both time and dimensions. Our Caformer demonstrates consistent state-of-the-art performance across five mainstream time series analysis tasks, including long- and short-term forecasting, imputation, classification, and anomaly detection, with proper interpretability.
Deep Learning for Satellite Image Time Series Analysis: A Review
Apr 11, 2024Earth observation (EO) satellite missions have been providing detailed images about the state of the Earth and its land cover for over 50 years. Long term missions, such as NASA's Landsat, Terra, and Aqua satellites, and more recently, the ESA's Sentinel missions, record images of the entire world every few days. Although single images provide point-in-time data, repeated images of the same area, or satellite image time series (SITS) provide information about the changing state of vegetation and land use. These SITS are useful for modeling dynamic processes and seasonal changes such as plant phenology. They have potential benefits for many aspects of land and natural resource management, including applications in agricultural, forest, water, and disaster management, urban planning, and mining. However, the resulting satellite image time series (SITS) are complex, incorporating information from the temporal, spatial, and spectral dimensions. Therefore, deep learning methods are often deployed as they can analyze these complex relationships. This review presents a summary of the state-of-the-art methods of modelling environmental, agricultural, and other Earth observation variables from SITS data using deep learning methods. We aim to provide a resource for remote sensing experts interested in using deep learning techniques to enhance Earth observation models with temporal information.
TOTEM: TOkenized Time Series EMbeddings for General Time Series Analysis
Feb 26, 2024The field of general time series analysis has recently begun to explore unified modeling, where a common architectural backbone can be retrained on a specific task for a specific dataset. In this work, we approach unification from a complementary vantage point: unification across tasks and domains. To this end, we explore the impact of discrete, learnt, time series data representations that enable generalist, cross-domain training. Our method, TOTEM, or TOkenized Time Series EMbeddings, proposes a simple tokenizer architecture that embeds time series data from varying domains using a discrete vectorized representation learned in a self-supervised manner. TOTEM works across multiple tasks and domains with minimal to no tuning. We study the efficacy of TOTEM with an extensive evaluation on 17 real world time series datasets across 3 tasks. We evaluate both the specialist (i.e., training a model on each domain) and generalist (i.e., training a single model on many domains) settings, and show that TOTEM matches or outperforms previous best methods on several popular benchmarks. The code can be found at: https://github.com/SaberaTalukder/TOTEM.
ConvTimeNet: A Deep Hierarchical Fully Convolutional Model for Multivariate Time Series Analysis
Mar 03, 2024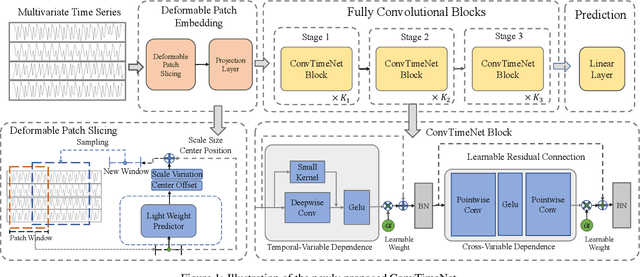
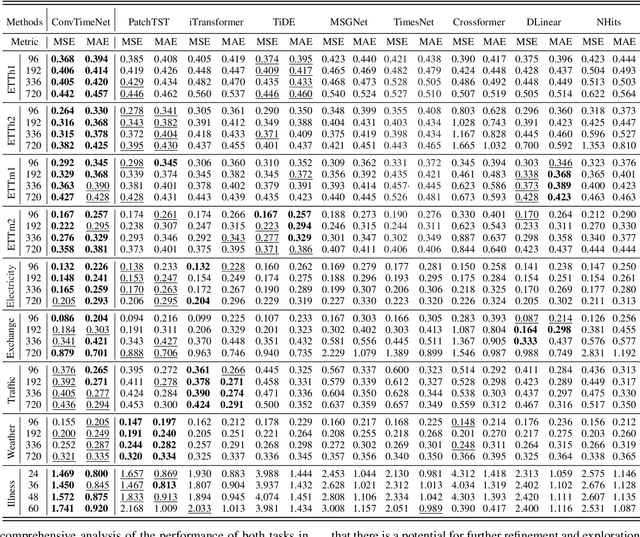
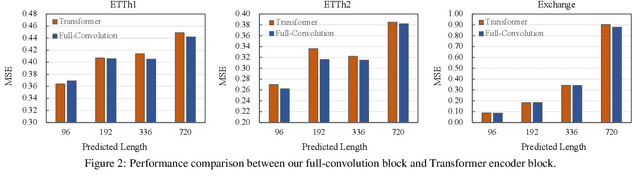
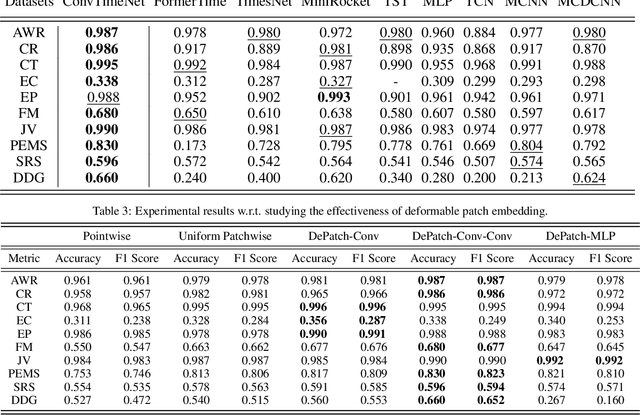
This paper introduces ConvTimeNet, a novel deep hierarchical fully convolutional network designed to serve as a general-purpose model for time series analysis. The key design of this network is twofold, designed to overcome the limitations of traditional convolutional networks. Firstly, we propose an adaptive segmentation of time series into sub-series level patches, treating these as fundamental modeling units. This setting avoids the sparsity semantics associated with raw point-level time steps. Secondly, we design a fully convolutional block by skillfully integrating deepwise and pointwise convolution operations, following the advanced building block style employed in Transformer encoders. This backbone network allows for the effective capture of both global sequence and cross-variable dependence, as it not only incorporates the advancements of Transformer architecture but also inherits the inherent properties of convolution. Furthermore, multi-scale representations of given time series instances can be learned by controlling the kernel size flexibly. Extensive experiments are conducted on both time series forecasting and classification tasks. The results consistently outperformed strong baselines in most situations in terms of effectiveness.The code is publicly available.
Empowering Time Series Analysis with Large Language Models: A Survey
Feb 05, 2024Recently, remarkable progress has been made over large language models (LLMs), demonstrating their unprecedented capability in varieties of natural language tasks. However, completely training a large general-purpose model from the scratch is challenging for time series analysis, due to the large volumes and varieties of time series data, as well as the non-stationarity that leads to concept drift impeding continuous model adaptation and re-training. Recent advances have shown that pre-trained LLMs can be exploited to capture complex dependencies in time series data and facilitate various applications. In this survey, we provide a systematic overview of existing methods that leverage LLMs for time series analysis. Specifically, we first state the challenges and motivations of applying language models in the context of time series as well as brief preliminaries of LLMs. Next, we summarize the general pipeline for LLM-based time series analysis, categorize existing methods into different groups (i.e., direct query, tokenization, prompt design, fine-tune, and model integration), and highlight the key ideas within each group. We also discuss the applications of LLMs for both general and spatial-temporal time series data, tailored to specific domains. Finally, we thoroughly discuss future research opportunities to empower time series analysis with LLMs.
Position Paper: What Can Large Language Models Tell Us about Time Series Analysis
Feb 05, 2024Time series analysis is essential for comprehending the complexities inherent in various real-world systems and applications. Although large language models (LLMs) have recently made significant strides, the development of artificial general intelligence (AGI) equipped with time series analysis capabilities remains in its nascent phase. Most existing time series models heavily rely on domain knowledge and extensive model tuning, predominantly focusing on prediction tasks. In this paper, we argue that current LLMs have the potential to revolutionize time series analysis, thereby promoting efficient decision-making and advancing towards a more universal form of time series analytical intelligence. Such advancement could unlock a wide range of possibilities, including modality switching and time series question answering. We encourage researchers and practitioners to recognize the potential of LLMs in advancing time series analysis and emphasize the need for trust in these related efforts. Furthermore, we detail the seamless integration of time series analysis with existing LLM technologies and outline promising avenues for future research.
Decoding Multilingual Topic Dynamics and Trend Identification through ARIMA Time Series Analysis on Social Networks: A Novel Data Translation Framework Enhanced by LDA/HDP Models
Mar 18, 2024In this study, the authors present a novel methodology adept at decoding multilingual topic dynamics and identifying communication trends during crises. We focus on dialogues within Tunisian social networks during the Coronavirus Pandemic and other notable themes like sports and politics. We start by aggregating a varied multilingual corpus of comments relevant to these subjects. This dataset undergoes rigorous refinement during data preprocessing. We then introduce our No-English-to-English Machine Translation approach to handle linguistic differences. Empirical tests of this method showed high accuracy and F1 scores, highlighting its suitability for linguistically coherent tasks. Delving deeper, advanced modeling techniques, specifically LDA and HDP models are employed to extract pertinent topics from the translated content. This leads to applying ARIMA time series analysis to decode evolving topic trends. Applying our method to a multilingual Tunisian dataset, we effectively identified key topics mirroring public sentiment. Such insights prove vital for organizations and governments striving to understand public perspectives during crises. Compared to standard approaches, our model outperforms, as confirmed by metrics like Coherence Score, U-mass, and Topic Coherence. Additionally, an in-depth assessment of the identified topics revealed notable thematic shifts in discussions, with our trends identification indicating impressive accuracy, backed by RMSE-based analysis.
MTSA-SNN: A Multi-modal Time Series Analysis Model Based on Spiking Neural Network
Feb 08, 2024Time series analysis and modelling constitute a crucial research area. Traditional artificial neural networks struggle with complex, non-stationary time series data due to high computational complexity, limited ability to capture temporal information, and difficulty in handling event-driven data. To address these challenges, we propose a Multi-modal Time Series Analysis Model Based on Spiking Neural Network (MTSA-SNN). The Pulse Encoder unifies the encoding of temporal images and sequential information in a common pulse-based representation. The Joint Learning Module employs a joint learning function and weight allocation mechanism to fuse information from multi-modal pulse signals complementary. Additionally, we incorporate wavelet transform operations to enhance the model's ability to analyze and evaluate temporal information. Experimental results demonstrate that our method achieved superior performance on three complex time-series tasks. This work provides an effective event-driven approach to overcome the challenges associated with analyzing intricate temporal information. Access to the source code is available at https://github.com/Chenngzz/MTSA-SNN}{https://github.com/Chenngzz/MTSA-SNN
* 6 pages, 6 figures, published to International Conference on Computer Supported Cooperative Work in Design