 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Yu": models, code, and papers
Emotion-Anchored Contrastive Learning Framework for Emotion Recognition in Conversation
Mar 29, 2024
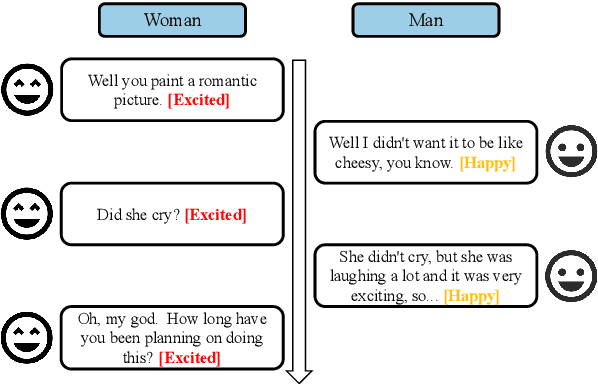
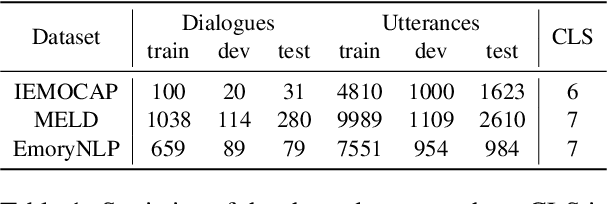
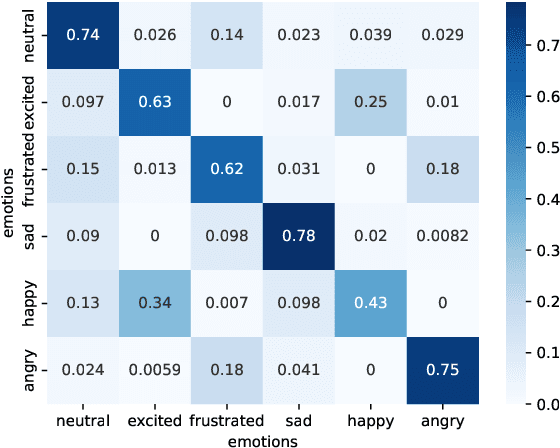
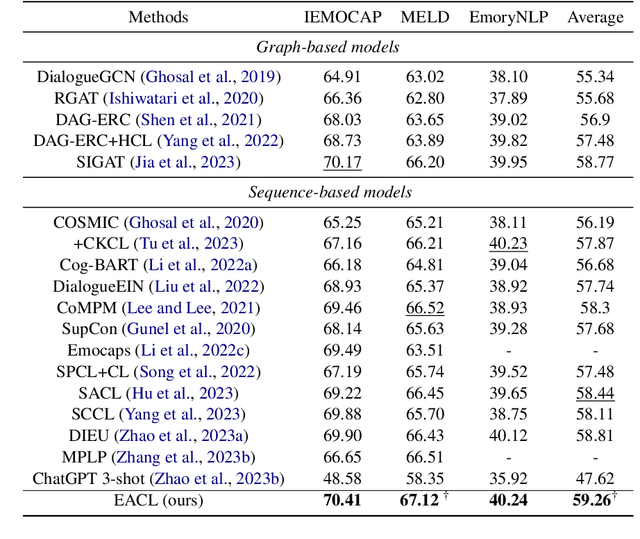
Emotion Recognition in Conversation (ERC) involves detecting the underlying emotion behind each utterance within a conversation. Effectively generating representations for utterances remains a significant challenge in this task. Recent works propose various models to address this issue, but they still struggle with differentiating similar emotions such as excitement and happiness. To alleviate this problem, We propose an Emotion-Anchored Contrastive Learning (EACL) framework that can generate more distinguishable utterance representations for similar emotions. To achieve this, we utilize label encodings as anchors to guide the learning of utterance representations and design an auxiliary loss to ensure the effective separation of anchors for similar emotions. Moreover, an additional adaptation process is proposed to adapt anchors to serve as effective classifiers to improve classification performance. Across extensive experiments, our proposed EACL achieves state-of-the-art emotion recognition performance and exhibits superior performance on similar emotions. Our code is available at https://github.com/Yu-Fangxu/EACL.
Cross-Resolution Land Cover Classification Using Outdated Products and Transformers
Mar 06, 2024Large-scale high-resolution land cover classification is a prerequisite for constructing Earth system models and addressing ecological and resource issues. Advancements in satellite sensor technology have led to an improvement in spatial resolution and wider coverage areas. Nevertheless, the lack of high-resolution labeled data is still a challenge, hindering the largescale application of land cover classification methods. In this paper, we propose a Transformerbased weakly supervised method for cross-resolution land cover classification using outdated data. First, to capture long-range dependencies without missing the fine-grained details of objects, we propose a U-Net-like Transformer based on a reverse difference mechanism (RDM) using dynamic sparse attention. Second, we propose an anti-noise loss calculation (ANLC) module based on optimal transport (OT). Anti-noise loss calculation identifies confident areas (CA) and vague areas (VA) based on the OT matrix, which relieves the impact of noises in outdated land cover products. By introducing a weakly supervised loss with weights and employing unsupervised loss, the RDM-based U-Net-like Transformer was trained. Remote sensing images with 1 m resolution and the corresponding ground-truths of six states in the United States were employed to validate the performance of the proposed method. The experiments utilized outdated land cover products with 30 m resolution from 2013 as training labels, and produced land cover maps with 1 m resolution from 2017. The results show the superiority of the proposed method compared to state-of-the-art methods. The code is available at https://github.com/yu-ni1989/ANLC-Former.
ICHPro: Intracerebral Hemorrhage Prognosis Classification Via Joint-attention Fusion-based 3d Cross-modal Network
Feb 17, 2024Intracerebral Hemorrhage (ICH) is the deadliest subtype of stroke, necessitating timely and accurate prognostic evaluation to reduce mortality and disability. However, the multi-factorial nature and complexity of ICH make methods based solely on computed tomography (CT) image features inadequate. Despite the capacity of cross-modal networks to fuse additional information, the effective combination of different modal features remains a significant challenge. In this study, we propose a joint-attention fusion-based 3D cross-modal network termed ICHPro that simulates the ICH prognosis interpretation process utilized by neurosurgeons. ICHPro includes a joint-attention fusion module to fuse features from CT images with demographic and clinical textual data. To enhance the representation of cross-modal features, we introduce a joint loss function. ICHPro facilitates the extraction of richer cross-modal features, thereby improving classification performance. Upon testing our method using a five-fold cross-validation, we achieved an accuracy of 89.11%, an F1 score of 0.8767, and an AUC value of 0.9429. These results outperform those obtained from other advanced methods based on the test dataset, thereby demonstrating the superior efficacy of ICHPro. The code is available at our Github: https://github.com/YU-deep/ICH.
OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset
Feb 15, 2024Recent work has shown the immense potential of synthetically generated datasets for training large language models (LLMs), especially for acquiring targeted skills. Current large-scale math instruction tuning datasets such as MetaMathQA (Yu et al., 2024) and MAmmoTH (Yue et al., 2024) are constructed using outputs from closed-source LLMs with commercially restrictive licenses. A key reason limiting the use of open-source LLMs in these data generation pipelines has been the wide gap between the mathematical skills of the best closed-source LLMs, such as GPT-4, and the best open-source LLMs. Building on the recent progress in open-source LLMs, our proposed prompting novelty, and some brute-force scaling, we construct OpenMathInstruct-1, a math instruction tuning dataset with 1.8M problem-solution pairs. The dataset is constructed by synthesizing code-interpreter solutions for GSM8K and MATH, two popular math reasoning benchmarks, using the recently released and permissively licensed Mixtral model. Our best model, OpenMath-CodeLlama-70B, trained on a subset of OpenMathInstruct-1, achieves a score of 84.6% on GSM8K and 50.7% on MATH, which is competitive with the best gpt-distilled models. We release our code, models, and the OpenMathInstruct-1 dataset under a commercially permissive license.
COLD-Attack: Jailbreaking LLMs with Stealthiness and Controllability
Feb 13, 2024Jailbreaks on Large language models (LLMs) have recently received increasing attention. For a comprehensive assessment of LLM safety, it is essential to consider jailbreaks with diverse attributes, such as contextual coherence and sentiment/stylistic variations, and hence it is beneficial to study controllable jailbreaking, i.e. how to enforce control on LLM attacks. In this paper, we formally formulate the controllable attack generation problem, and build a novel connection between this problem and controllable text generation, a well-explored topic of natural language processing. Based on this connection, we adapt the Energy-based Constrained Decoding with Langevin Dynamics (COLD), a state-of-the-art, highly efficient algorithm in controllable text generation, and introduce the COLD-Attack framework which unifies and automates the search of adversarial LLM attacks under a variety of control requirements such as fluency, stealthiness, sentiment, and left-right-coherence. The controllability enabled by COLD-Attack leads to diverse new jailbreak scenarios which not only cover the standard setting of generating fluent suffix attacks, but also allow us to address new controllable attack settings such as revising a user query adversarially with minimal paraphrasing, and inserting stealthy attacks in context with left-right-coherence. Our extensive experiments on various LLMs (Llama-2, Mistral, Vicuna, Guanaco, GPT-3.5) show COLD-Attack's broad applicability, strong controllability, high success rate, and attack transferability. Our code is available at https://github.com/Yu-Fangxu/COLD-Attack.
Source Code is a Graph, Not a Sequence: A Cross-Lingual Perspective on Code Clone Detection
Dec 27, 2023Source code clone detection is the task of finding code fragments that have the same or similar functionality, but may differ in syntax or structure. This task is important for software maintenance, reuse, and quality assurance (Roy et al. 2009). However, code clone detection is challenging, as source code can be written in different languages, domains, and styles. In this paper, we argue that source code is inherently a graph, not a sequence, and that graph-based methods are more suitable for code clone detection than sequence-based methods. We compare the performance of two state-of-the-art models: CodeBERT (Feng et al. 2020), a sequence-based model, and CodeGraph (Yu et al. 2023), a graph-based model, on two benchmark data-sets: BCB (Svajlenko et al. 2014) and PoolC (PoolC no date). We show that CodeGraph outperforms CodeBERT on both data-sets, especially on cross-lingual code clones. To the best of our knowledge, this is the first work to demonstrate the superiority of graph-based methods over sequence-based methods on cross-lingual code clone detection.
Flow-Based Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Nov 03, 2023Cooperatively utilizing both ego-vehicle and infrastructure sensor data can significantly enhance autonomous driving perception abilities. However, the uncertain temporal asynchrony and limited communication conditions can lead to fusion misalignment and constrain the exploitation of infrastructure data. To address these issues in vehicle-infrastructure cooperative 3D (VIC3D) object detection, we propose the Feature Flow Net (FFNet), a novel cooperative detection framework. FFNet is a flow-based feature fusion framework that uses a feature flow prediction module to predict future features and compensate for asynchrony. Instead of transmitting feature maps extracted from still-images, FFNet transmits feature flow, leveraging the temporal coherence of sequential infrastructure frames. Furthermore, we introduce a self-supervised training approach that enables FFNet to generate feature flow with feature prediction ability from raw infrastructure sequences. Experimental results demonstrate that our proposed method outperforms existing cooperative detection methods while only requiring about 1/100 of the transmission cost of raw data and covers all latency in one model on the DAIR-V2X dataset. The code is available at \href{https://github.com/haibao-yu/FFNet-VIC3D}{https://github.com/haibao-yu/FFNet-VIC3D}.
Verilog-to-PyG -- A Framework for Graph Learning and Augmentation on RTL Designs
Nov 09, 2023The complexity of modern hardware designs necessitates advanced methodologies for optimizing and analyzing modern digital systems. In recent times, machine learning (ML) methodologies have emerged as potent instruments for assessing design quality-of-results at the Register-Transfer Level (RTL) or Boolean level, aiming to expedite design exploration of advanced RTL configurations. In this presentation, we introduce an innovative open-source framework that translates RTL designs into graph representation foundations, which can be seamlessly integrated with the PyTorch Geometric graph learning platform. Furthermore, the Verilog-to-PyG (V2PYG) framework is compatible with the open-source Electronic Design Automation (EDA) toolchain OpenROAD, facilitating the collection of labeled datasets in an utterly open-source manner. Additionally, we will present novel RTL data augmentation methods (incorporated in our framework) that enable functional equivalent design augmentation for the construction of an extensive graph-based RTL design database. Lastly, we will showcase several using cases of V2PYG with detailed scripting examples. V2PYG can be found at \url{https://yu-maryland.github.io/Verilog-to-PyG/}.
Module-wise Adaptive Distillation for Multimodality Foundation Models
Oct 06, 2023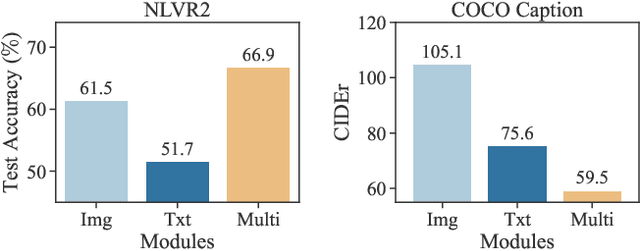
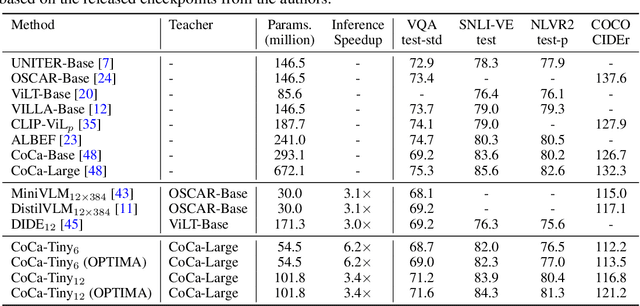
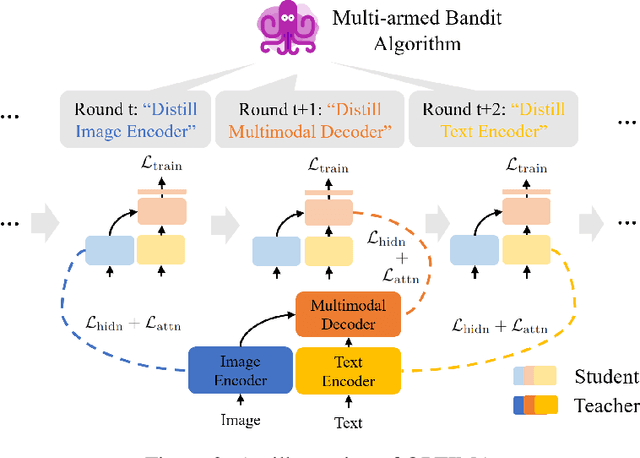
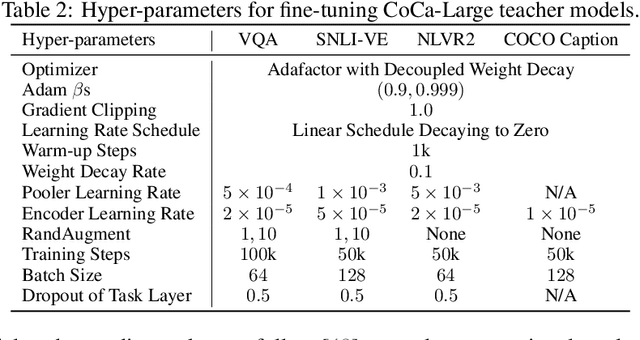
Pre-trained multimodal foundation models have demonstrated remarkable generalizability but pose challenges for deployment due to their large sizes. One effective approach to reducing their sizes is layerwise distillation, wherein small student models are trained to match the hidden representations of large teacher models at each layer. Motivated by our observation that certain architecture components, referred to as modules, contribute more significantly to the student's performance than others, we propose to track the contributions of individual modules by recording the loss decrement after distillation each module and choose the module with a greater contribution to distill more frequently. Such an approach can be naturally formulated as a multi-armed bandit (MAB) problem, where modules and loss decrements are considered as arms and rewards, respectively. We then develop a modified-Thompson sampling algorithm named OPTIMA to address the nonstationarity of module contributions resulting from model updating. Specifically, we leverage the observed contributions in recent history to estimate the changing contribution of each module and select modules based on these estimations to maximize the cumulative contribution. We evaluate the effectiveness of OPTIMA through distillation experiments on various multimodal understanding and image captioning tasks, using the CoCa-Large model (Yu et al., 2022) as the teacher model.