 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Zhang": models, code, and papers
Study on the static detection of ICF target based on muonic X-ray sphere encoded imaging
Apr 18, 2024
Muon Induced X-ray Emission (MIXE) was discovered by Chinese physicist Zhang Wenyu as early as 1947, and it can conduct non-destructive elemental analysis inside samples. Research has shown that MIXE can retain the high efficiency of direct imaging while benefiting from the low noise of pinhole imaging through encoding holes. The related technology significantly improves the counting rate while maintaining imaging quality. The sphere encoding technology effectively solves the imaging blurring caused by the tilting of the encoding system, and successfully images micrometer sized X-ray sources. This paper will combine MIXE and X-ray sphere coding imaging techniques, including ball coding and zone plates, to study the method of non-destructive deep structure imaging of ICF targets and obtaining sub element distribution. This method aims to develop a new method for ICF target detection, which is particularly important for inertial confinement fusion. At the same time, this method can be used to detect and analyze materials that are difficult to penetrate or sensitive, and is expected to solve the problem of element resolution and imaging that traditional technologies cannot overcome. It will provide new methods for the future development of multiple fields such as particle physics, material science, and X-ray optics.
Clipped SGD Algorithms for Privacy Preserving Performative Prediction: Bias Amplification and Remedies
Apr 17, 2024Clipped stochastic gradient descent (SGD) algorithms are among the most popular algorithms for privacy preserving optimization that reduces the leakage of users' identity in model training. This paper studies the convergence properties of these algorithms in a performative prediction setting, where the data distribution may shift due to the deployed prediction model. For example, the latter is caused by strategical users during the training of loan policy for banks. Our contributions are two-fold. First, we show that the straightforward implementation of a projected clipped SGD (PCSGD) algorithm may converge to a biased solution compared to the performative stable solution. We quantify the lower and upper bound for the magnitude of the bias and demonstrate a bias amplification phenomenon where the bias grows with the sensitivity of the data distribution. Second, we suggest two remedies to the bias amplification effect. The first one utilizes an optimal step size design for PCSGD that takes the privacy guarantee into account. The second one uses the recently proposed DiceSGD algorithm [Zhang et al., 2024]. We show that the latter can successfully remove the bias and converge to the performative stable solution. Numerical experiments verify our analysis.
Automatic Alignment of Discourse Relations of Different Discourse Annotation Frameworks
Apr 06, 2024
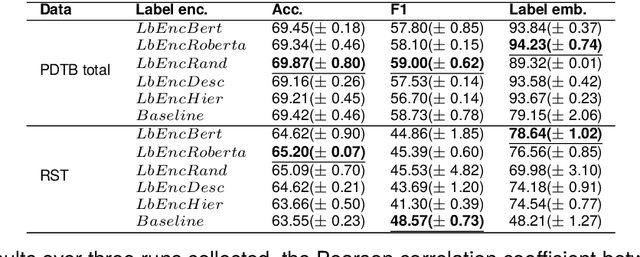


Existing discourse corpora are annotated based on different frameworks, which show significant dissimilarities in definitions of arguments and relations and structural constraints. Despite surface differences, these frameworks share basic understandings of discourse relations. The relationship between these frameworks has been an open research question, especially the correlation between relation inventories utilized in different frameworks. Better understanding of this question is helpful for integrating discourse theories and enabling interoperability of discourse corpora annotated under different frameworks. However, studies that explore correlations between discourse relation inventories are hindered by different criteria of discourse segmentation, and expert knowledge and manual examination are typically needed. Some semi-automatic methods have been proposed, but they rely on corpora annotated in multiple frameworks in parallel. In this paper, we introduce a fully automatic approach to address the challenges. Specifically, we extend the label-anchored contrastive learning method introduced by Zhang et al. (2022b) to learn label embeddings during a classification task. These embeddings are then utilized to map discourse relations from different frameworks. We show experimental results on RST-DT (Carlson et al., 2001) and PDTB 3.0 (Prasad et al., 2018).
On the Role of Summary Content Units in Text Summarization Evaluation
Apr 02, 2024At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
OOSTraj: Out-of-Sight Trajectory Prediction With Vision-Positioning Denoising
Apr 02, 2024Trajectory prediction is fundamental in computer vision and autonomous driving, particularly for understanding pedestrian behavior and enabling proactive decision-making. Existing approaches in this field often assume precise and complete observational data, neglecting the challenges associated with out-of-view objects and the noise inherent in sensor data due to limited camera range, physical obstructions, and the absence of ground truth for denoised sensor data. Such oversights are critical safety concerns, as they can result in missing essential, non-visible objects. To bridge this gap, we present a novel method for out-of-sight trajectory prediction that leverages a vision-positioning technique. Our approach denoises noisy sensor observations in an unsupervised manner and precisely maps sensor-based trajectories of out-of-sight objects into visual trajectories. This method has demonstrated state-of-the-art performance in out-of-sight noisy sensor trajectory denoising and prediction on the Vi-Fi and JRDB datasets. By enhancing trajectory prediction accuracy and addressing the challenges of out-of-sight objects, our work significantly contributes to improving the safety and reliability of autonomous driving in complex environments. Our work represents the first initiative towards Out-Of-Sight Trajectory prediction (OOSTraj), setting a new benchmark for future research. The code is available at \url{https://github.com/Hai-chao-Zhang/OOSTraj}.
ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
Mar 27, 2024We establish rigorous benchmarks for visual perception robustness. Synthetic images such as ImageNet-C, ImageNet-9, and Stylized ImageNet provide specific type of evaluation over synthetic corruptions, backgrounds, and textures, yet those robustness benchmarks are restricted in specified variations and have low synthetic quality. In this work, we introduce generative model as a data source for synthesizing hard images that benchmark deep models' robustness. Leveraging diffusion models, we are able to generate images with more diversified backgrounds, textures, and materials than any prior work, where we term this benchmark as ImageNet-D. Experimental results show that ImageNet-D results in a significant accuracy drop to a range of vision models, from the standard ResNet visual classifier to the latest foundation models like CLIP and MiniGPT-4, significantly reducing their accuracy by up to 60\%. Our work suggests that diffusion models can be an effective source to test vision models. The code and dataset are available at https://github.com/chenshuang-zhang/imagenet_d.
Sensor Network Localization via Riemannian Conjugate Gradient and Rank Reduction: An Extended Version
Mar 13, 2024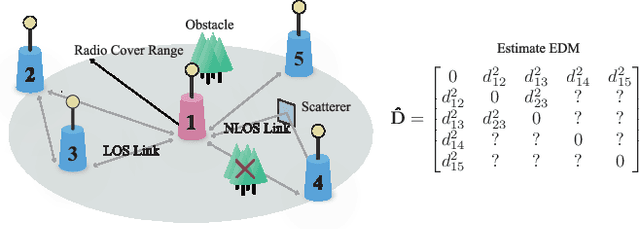
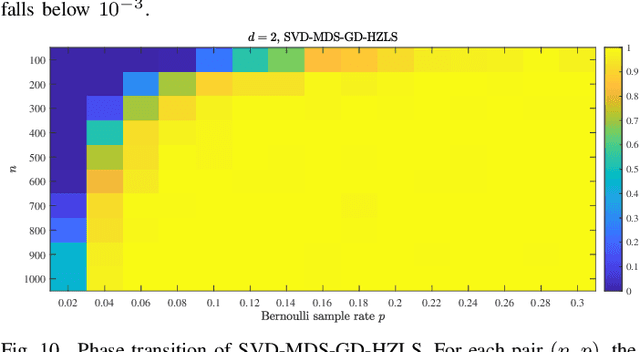
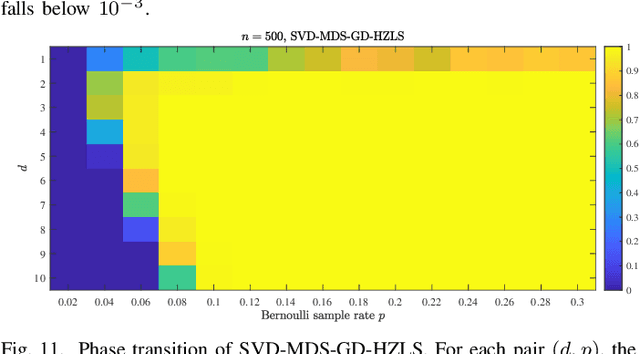
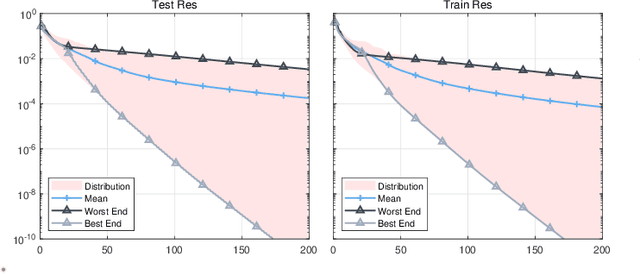
This paper addresses the Sensor Network Localization (SNL) problem using received signal strength. The SNL is formulated as an Euclidean Distance Matrix Completion (EDMC) problem under the unit ball sample model. Using the Burer-Monteiro factorization type cost function, the EDMC is solved by Riemannian conjugate gradient with Hager-Zhang line search method on a quotient manifold. A "rank reduction" preprocess is proposed for proper initialization and to achieve global convergence with high probability. Simulations on a synthetic scene show that our approach attains better localization accuracy and is computationally efficient compared to several baseline methods. Characterization of a small local basin of attraction around the global optima of the s-stress function under Bernoulli sampling rule and incoherence matrix completion framework is conducted for the first time. Theoretical result conjectures that the Euclidean distance problem with a structure-less sample mask can be effectively handled using spectral initialization followed by vanilla first-order methods. This preliminary analysis, along with the aforementioned numerical accomplishments, provides insights into revealing the landscape of the s-stress function and may stimulate the design of simpler algorithms to tackle the non-convex formulation of general EDMC problems.
ViTCN: Vision Transformer Contrastive Network For Reasoning
Mar 15, 2024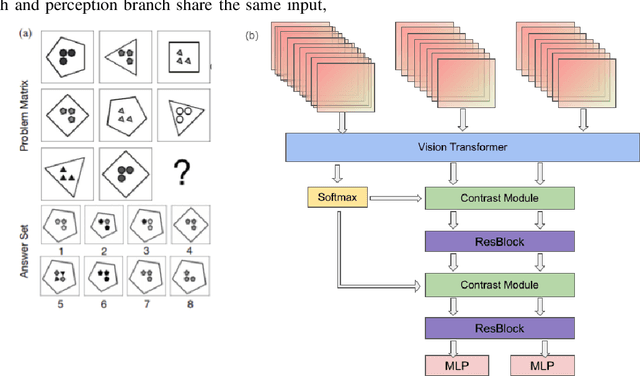

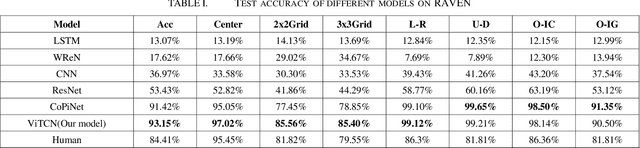
Machine learning models have achieved significant milestones in various domains, for example, computer vision models have an exceptional result in object recognition, and in natural language processing, where Large Language Models (LLM) like GPT can start a conversation with human-like proficiency. However, abstract reasoning remains a challenge for these models, Can AI really thinking like a human? still be a question yet to be answered. Raven Progressive Matrices (RPM) is a metric designed to assess human reasoning capabilities. It presents a series of eight images as a problem set, where the participant should try to discover the underlying rules among these images and select the most appropriate image from eight possible options that best completes the sequence. This task always be used to test human reasoning abilities and IQ. Zhang et al proposed a dataset called RAVEN which can be used to test Machine Learning model abstract reasoning ability. In this paper, we purposed Vision Transformer Contrastive Network which build on previous work with the Contrastive Perceptual Inference network (CoPiNet), which set a new benchmark for permutationinvariant models Raven Progressive Matrices by incorporating contrast effects from psychology, cognition, and education, and extends this foundation by leveraging the cutting-edge Vision Transformer architecture. This integration aims to further refine the machine ability to process and reason about spatial-temporal information from pixel-level inputs and global wise features on RAVEN dataset.
On Cyclical MCMC Sampling
Mar 01, 2024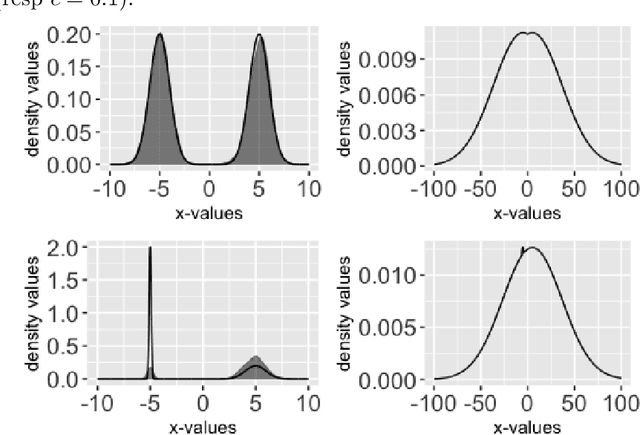
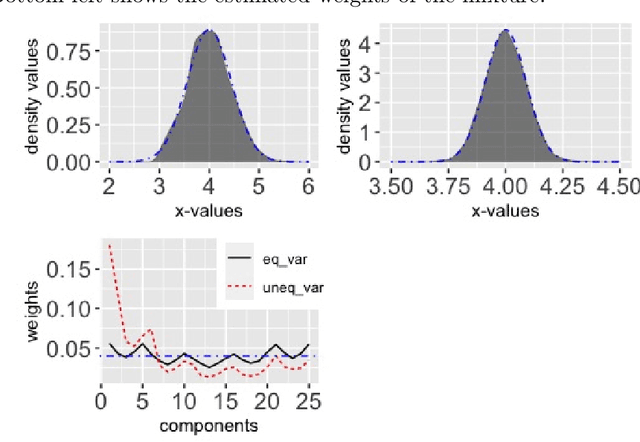
Cyclical MCMC is a novel MCMC framework recently proposed by Zhang et al. (2019) to address the challenge posed by high-dimensional multimodal posterior distributions like those arising in deep learning. The algorithm works by generating a nonhomogeneous Markov chain that tracks -- cyclically in time -- tempered versions of the target distribution. We show in this work that cyclical MCMC converges to the desired probability distribution in settings where the Markov kernels used are fast mixing, and sufficiently long cycles are employed. However in the far more common settings of slow mixing kernels, the algorithm may fail to produce samples from the desired distribution. In particular, in a simple mixture example with unequal variance, we show by simulation that cyclical MCMC fails to converge to the desired limit. Finally, we show that cyclical MCMC typically estimates well the local shape of the target distribution around each mode, even when we do not have convergence to the target.