 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFatma Güney
Self-supervised Object-Centric Learning for Videos
Oct 10, 2023
Unsupervised multi-object segmentation has shown impressive results on images by utilizing powerful semantics learned from self-supervised pretraining. An additional modality such as depth or motion is often used to facilitate the segmentation in video sequences. However, the performance improvements observed in synthetic sequences, which rely on the robustness of an additional cue, do not translate to more challenging real-world scenarios. In this paper, we propose the first fully unsupervised method for segmenting multiple objects in real-world sequences. Our object-centric learning framework spatially binds objects to slots on each frame and then relates these slots across frames. From these temporally-aware slots, the training objective is to reconstruct the middle frame in a high-level semantic feature space. We propose a masking strategy by dropping a significant portion of tokens in the feature space for efficiency and regularization. Additionally, we address over-clustering by merging slots based on similarity. Our method can successfully segment multiple instances of complex and high-variety classes in YouTube videos.
Privileged to Predicted: Towards Sensorimotor Reinforcement Learning for Urban Driving
Sep 18, 2023Reinforcement Learning (RL) has the potential to surpass human performance in driving without needing any expert supervision. Despite its promise, the state-of-the-art in sensorimotor self-driving is dominated by imitation learning methods due to the inherent shortcomings of RL algorithms. Nonetheless, RL agents are able to discover highly successful policies when provided with privileged ground truth representations of the environment. In this work, we investigate what separates privileged RL agents from sensorimotor agents for urban driving in order to bridge the gap between the two. We propose vision-based deep learning models to approximate the privileged representations from sensor data. In particular, we identify aspects of state representation that are crucial for the success of the RL agent such as desired route generation and stop zone prediction, and propose solutions to gradually develop less privileged RL agents. We also observe that bird's-eye-view models trained on offline datasets do not generalize to online RL training due to distribution mismatch. Through rigorous evaluation on the CARLA simulation environment, we shed light on the significance of the state representations in RL for autonomous driving and point to unresolved challenges for future research.
Have We Ever Encountered This Before? Retrieving Out-of-Distribution Road Obstacles from Driving Scenes
Sep 08, 2023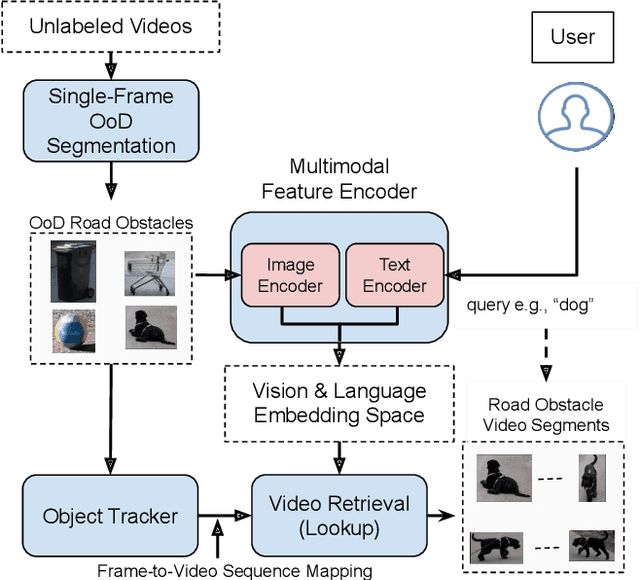
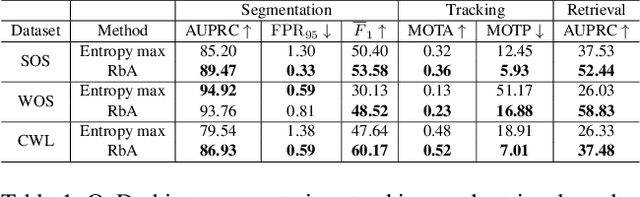
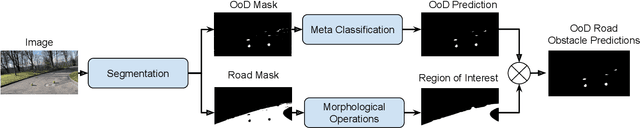
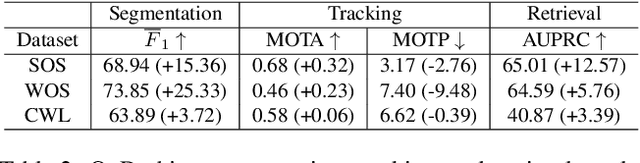
In the life cycle of highly automated systems operating in an open and dynamic environment, the ability to adjust to emerging challenges is crucial. For systems integrating data-driven AI-based components, rapid responses to deployment issues require fast access to related data for testing and reconfiguration. In the context of automated driving, this especially applies to road obstacles that were not included in the training data, commonly referred to as out-of-distribution (OoD) road obstacles. Given the availability of large uncurated recordings of driving scenes, a pragmatic approach is to query a database to retrieve similar scenarios featuring the same safety concerns due to OoD road obstacles. In this work, we extend beyond identifying OoD road obstacles in video streams and offer a comprehensive approach to extract sequences of OoD road obstacles using text queries, thereby proposing a way of curating a collection of OoD data for subsequent analysis. Our proposed method leverages the recent advances in OoD segmentation and multi-modal foundation models to identify and efficiently extract safety-relevant scenes from unlabeled videos. We present a first approach for the novel task of text-based OoD object retrieval, which addresses the question ''Have we ever encountered this before?''.
ADAPT: Efficient Multi-Agent Trajectory Prediction with Adaptation
Jul 26, 2023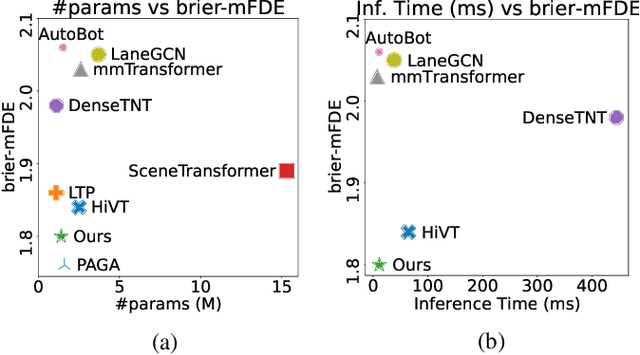
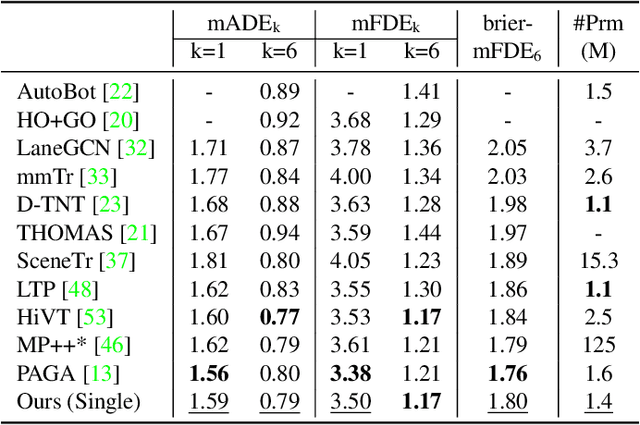
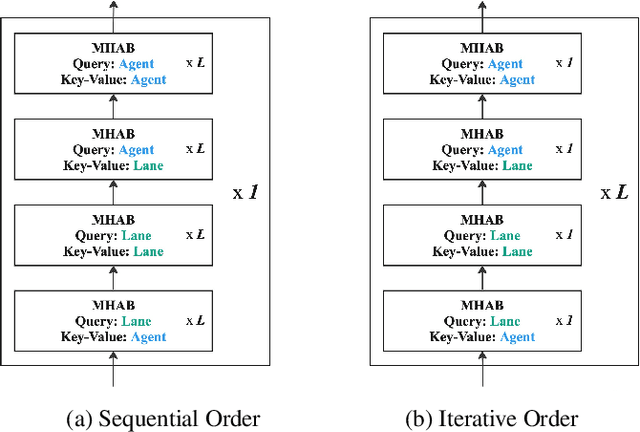

Forecasting future trajectories of agents in complex traffic scenes requires reliable and efficient predictions for all agents in the scene. However, existing methods for trajectory prediction are either inefficient or sacrifice accuracy. To address this challenge, we propose ADAPT, a novel approach for jointly predicting the trajectories of all agents in the scene with dynamic weight learning. Our approach outperforms state-of-the-art methods in both single-agent and multi-agent settings on the Argoverse and Interaction datasets, with a fraction of their computational overhead. We attribute the improvement in our performance: first, to the adaptive head augmenting the model capacity without increasing the model size; second, to our design choices in the endpoint-conditioned prediction, reinforced by gradient stopping. Our analyses show that ADAPT can focus on each agent with adaptive prediction, allowing for accurate predictions efficiently. https://KUIS-AI.github.io/adapt
Multi-Object Discovery by Low-Dimensional Object Motion
Jul 16, 2023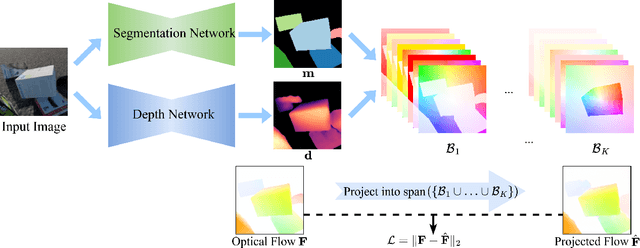
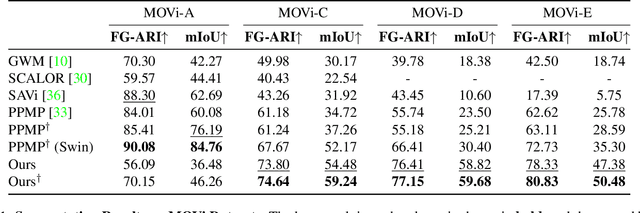

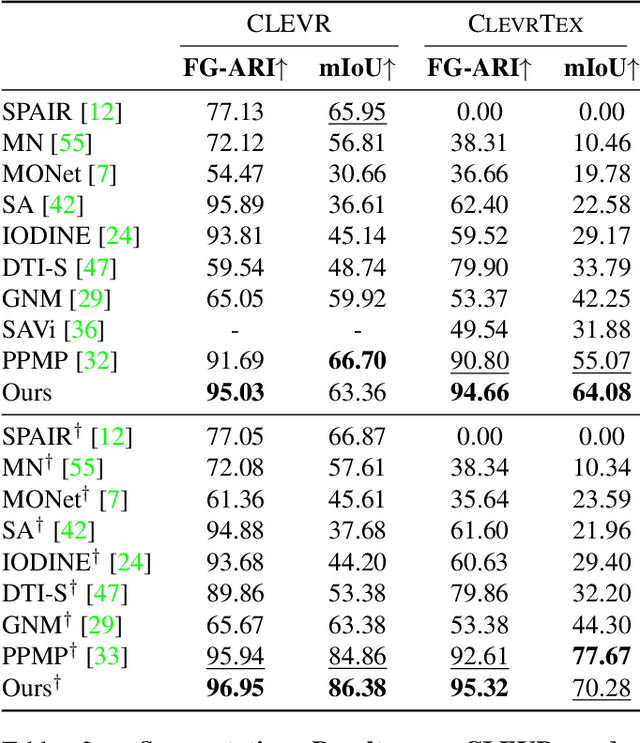
Recent work in unsupervised multi-object segmentation shows impressive results by predicting motion from a single image despite the inherent ambiguity in predicting motion without the next image. On the other hand, the set of possible motions for an image can be constrained to a low-dimensional space by considering the scene structure and moving objects in it. We propose to model pixel-wise geometry and object motion to remove ambiguity in reconstructing flow from a single image. Specifically, we divide the image into coherently moving regions and use depth to construct flow bases that best explain the observed flow in each region. We achieve state-of-the-art results in unsupervised multi-object segmentation on synthetic and real-world datasets by modeling the scene structure and object motion. Our evaluation of the predicted depth maps shows reliable performance in monocular depth estimation.
DepthP+P: Metric Accurate Monocular Depth Estimation using Planar and Parallax
Jan 05, 2023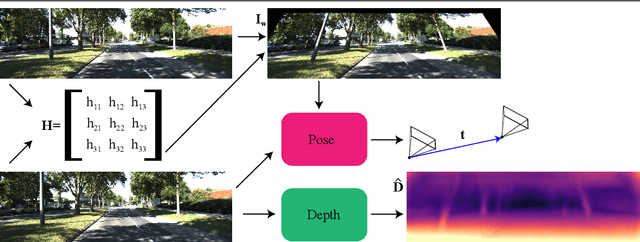
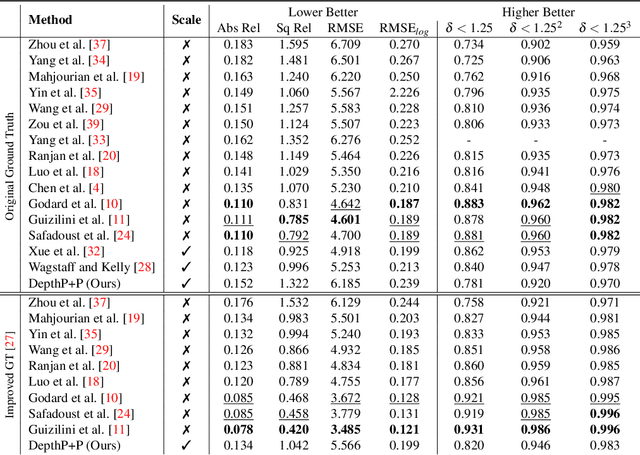
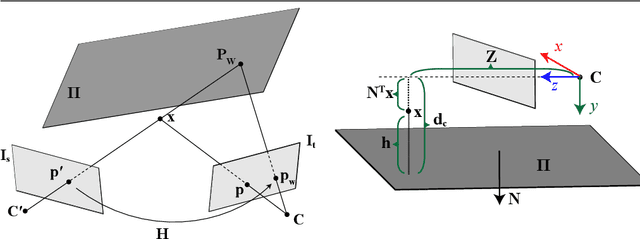
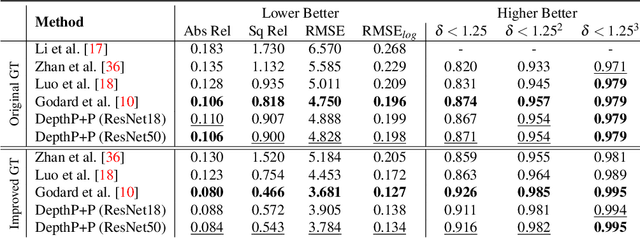
Current self-supervised monocular depth estimation methods are mostly based on estimating a rigid-body motion representing camera motion. These methods suffer from the well-known scale ambiguity problem in their predictions. We propose DepthP+P, a method that learns to estimate outputs in metric scale by following the traditional planar parallax paradigm. We first align the two frames using a common ground plane which removes the effect of the rotation component in the camera motion. With two neural networks, we predict the depth and the camera translation, which is easier to predict alone compared to predicting it together with rotation. By assuming a known camera height, we can then calculate the induced 2D image motion of a 3D point and use it for reconstructing the target image in a self-supervised monocular approach. We perform experiments on the KITTI driving dataset and show that the planar parallax approach, which only needs to predict camera translation, can be a metrically accurate alternative to the current methods that rely on estimating 6DoF camera motion.
Pixels Together Strong: Segmenting Unknown Regions Rejected by All
Nov 25, 2022
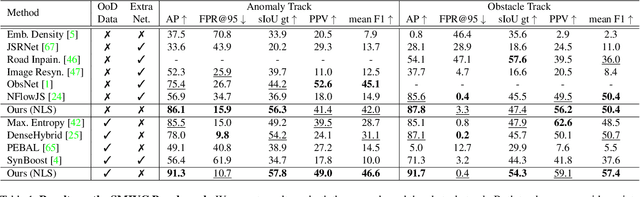
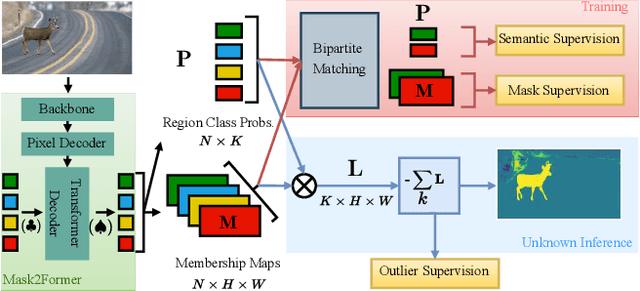
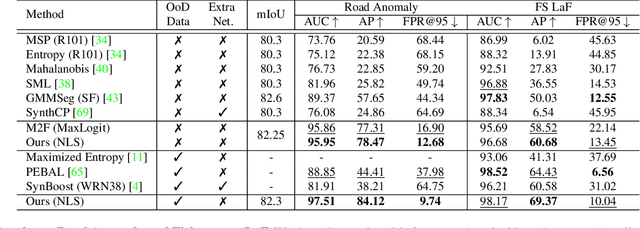
Semantic segmentation methods typically perform per-pixel classification by assuming a fixed set of semantic categories. While they perform well on the known set, the network fails to learn the concept of objectness, which is necessary for identifying unknown objects. In this paper, we explore the potential of query-based mask classification for unknown object segmentation. We discover that object queries specialize in predicting a certain class and behave like one vs. all classifiers, allowing us to detect unknowns by finding regions that are ignored by all the queries. Based on a detailed analysis of the model's behavior, we propose a novel anomaly scoring function. We demonstrate that mask classification helps to preserve the objectness and the proposed scoring function eliminates irrelevant sources of uncertainty. Our method achieves consistent improvements in multiple benchmarks, even under high domain shift, without retraining or using outlier data. With modest supervision for outliers, we show that further improvements can be achieved without affecting the closed-set performance.
Two-Level Temporal Relation Model for Online Video Instance Segmentation
Oct 30, 2022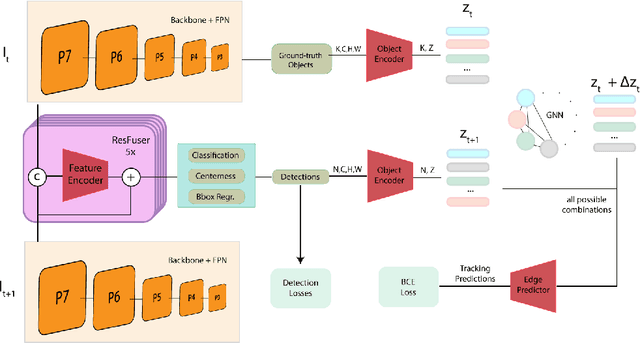
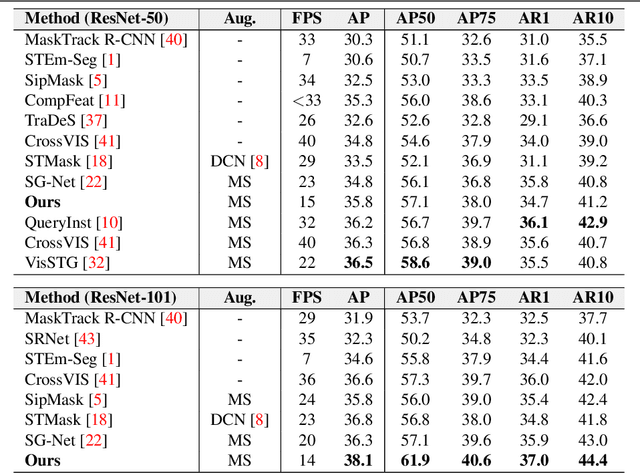
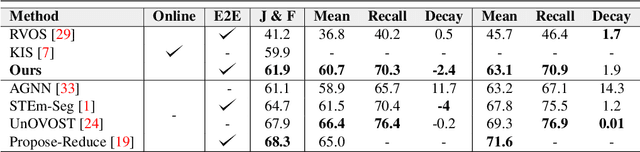

In Video Instance Segmentation (VIS), current approaches either focus on the quality of the results, by taking the whole video as input and processing it offline; or on speed, by handling it frame by frame at the cost of competitive performance. In this work, we propose an online method that is on par with the performance of the offline counterparts. We introduce a message-passing graph neural network that encodes objects and relates them through time. We additionally propose a novel module to fuse features from the feature pyramid network with residual connections. Our model, trained end-to-end, achieves state-of-the-art performance on the YouTube-VIS dataset within the online methods. Further experiments on DAVIS demonstrate the generalization capability of our model to the video object segmentation task. Code is available at: \url{https://github.com/caganselim/TLTM}
Trajectory Forecasting on Temporal Graphs
Jul 01, 2022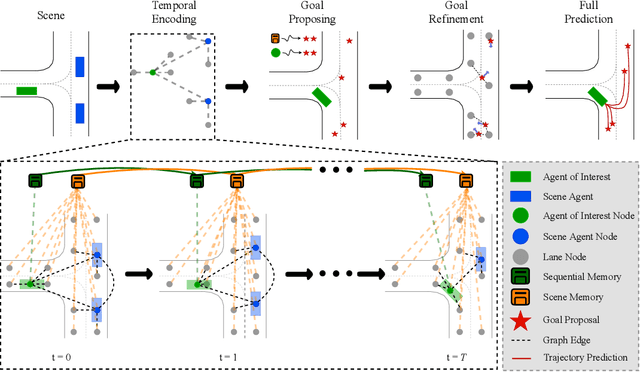
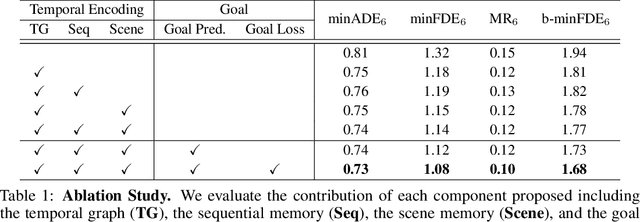
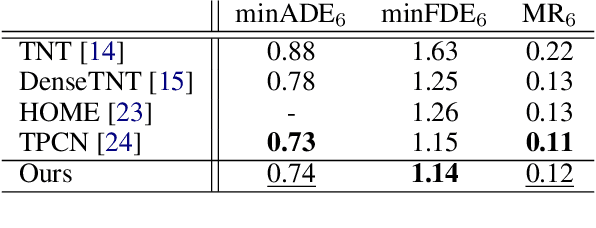
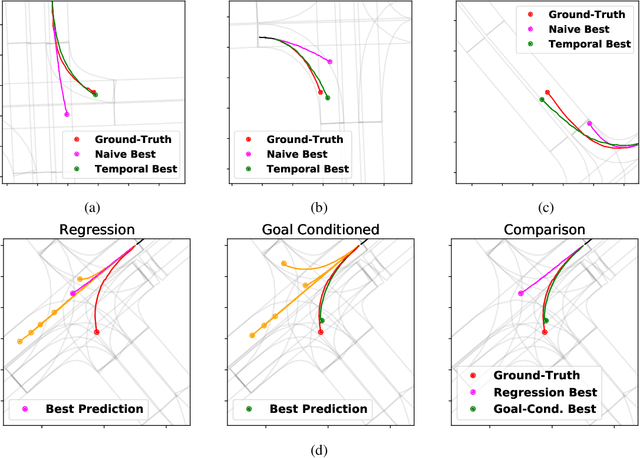
Predicting future locations of agents in the scene is an important problem in self-driving. In recent years, there has been a significant progress in representing the scene and the agents in it. The interactions of agents with the scene and with each other are typically modeled with a Graph Neural Network. However, the graph structure is mostly static and fails to represent the temporal changes in highly dynamic scenes. In this work, we propose a temporal graph representation to better capture the dynamics in traffic scenes. We complement our representation with two types of memory modules; one focusing on the agent of interest and the other on the entire scene. This allows us to learn temporally-aware representations that can achieve good results even with simple regression of multiple futures. When combined with goal-conditioned prediction, we show better results that can reach the state-of-the-art performance on the Argoverse benchmark.
StretchBEV: Stretching Future Instance Prediction Spatially and Temporally
Mar 25, 2022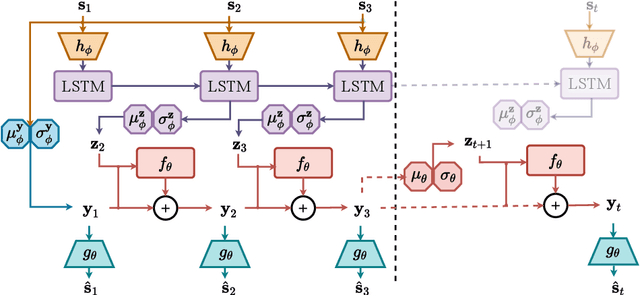
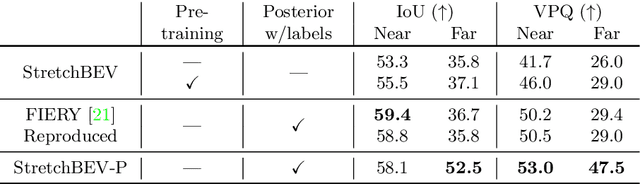
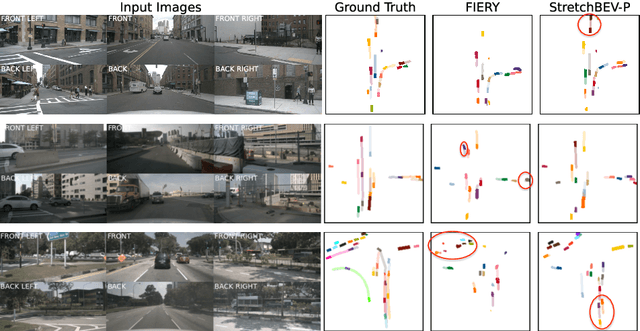

In self-driving, predicting future in terms of location and motion of all the agents around the vehicle is a crucial requirement for planning. Recently, a new joint formulation of perception and prediction has emerged by fusing rich sensory information perceived from multiple cameras into a compact bird's-eye view representation to perform prediction. However, the quality of future predictions degrades over time while extending to longer time horizons due to multiple plausible predictions. In this work, we address this inherent uncertainty in future predictions with a stochastic temporal model. Our model learns temporal dynamics in a latent space through stochastic residual updates at each time step. By sampling from a learned distribution at each time step, we obtain more diverse future predictions that are also more accurate compared to previous work, especially stretching both spatially further regions in the scene and temporally over longer time horizons. Despite separate processing of each time step, our model is still efficient through decoupling of the learning of dynamics and the generation of future predictions.