 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Liu": models, code, and papers
Comment on "Machine learning conservation laws from differential equations"
Apr 03, 2024
In lieu of abstract, first paragraph reads: Six months after the author derived a constant of motion for a 1D damped harmonic oscillator [1], a similar result appeared by Liu, Madhavan, and Tegmark [2, 3], without citing the author. However, their derivation contained six serious errors, causing both their method and result to be incorrect. In this Comment, those errors are reviewed.
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Apr 11, 2024Our goal is to build embodied agents that can learn inductively generalizable spatial concepts in a continual manner, e.g, constructing a tower of a given height. Existing work suffers from certain limitations (a) (Liang et al., 2023) and their multi-modal extensions, rely heavily on prior knowledge and are not grounded in the demonstrations (b) (Liu et al., 2023) lack the ability to generalize due to their purely neural approach. A key challenge is to achieve a fine balance between symbolic representations which have the capability to generalize, and neural representations that are physically grounded. In response, we propose a neuro-symbolic approach by expressing inductive concepts as symbolic compositions over grounded neural concepts. Our key insight is to decompose the concept learning problem into the following steps 1) Sketch: Getting a programmatic representation for the given instruction 2) Plan: Perform Model-Based RL over the sequence of grounded neural action concepts to learn a grounded plan 3) Generalize: Abstract out a generic (lifted) Python program to facilitate generalizability. Continual learning is achieved by interspersing learning of grounded neural concepts with higher level symbolic constructs. Our experiments demonstrate that our approach significantly outperforms existing baselines in terms of its ability to learn novel concepts and generalize inductively.
Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs
Apr 01, 2024The advent of Large Language Models (LLMs) has significantly transformed the AI landscape, enhancing machine learning and AI capabilities. Factuality issue is a critical concern for LLMs, as they may generate factually incorrect responses. In this paper, we propose GraphEval to evaluate an LLM's performance using a substantially large test dataset. Specifically, the test dataset is retrieved from a large knowledge graph with more than 10 million facts without expensive human efforts. Unlike conventional methods that evaluate LLMs based on generated responses, GraphEval streamlines the evaluation process by creating a judge model to estimate the correctness of the answers given by the LLM. Our experiments demonstrate that the judge model's factuality assessment aligns closely with the correctness of the LLM's generated outputs, while also substantially reducing evaluation costs. Besides, our findings offer valuable insights into LLM performance across different metrics and highlight the potential for future improvements in ensuring the factual integrity of LLM outputs. The code is publicly available at https://github.com/xz-liu/GraphEval.
Change-Agent: Towards Interactive Comprehensive Remote Sensing Change Interpretation and Analysis
Apr 01, 2024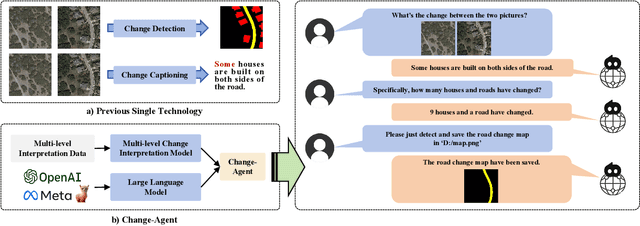
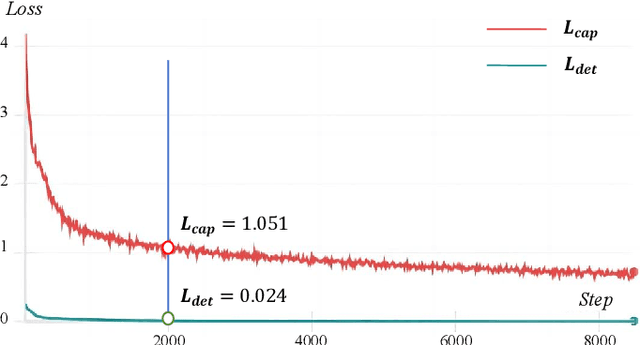
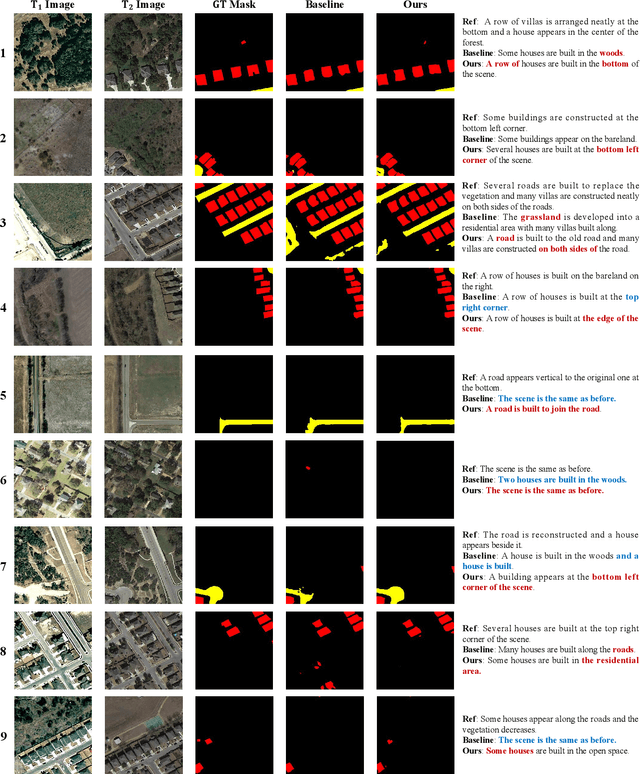
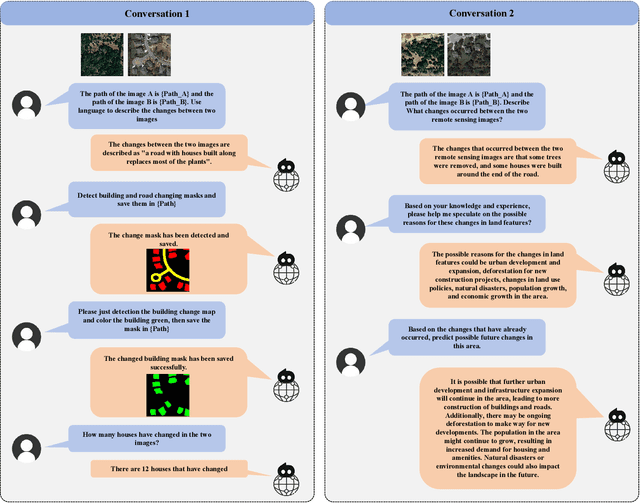
Monitoring changes in the Earth's surface is crucial for understanding natural processes and human impacts, necessitating precise and comprehensive interpretation methodologies. Remote sensing satellite imagery offers a unique perspective for monitoring these changes, leading to the emergence of remote sensing image change interpretation (RSICI) as a significant research focus. Current RSICI technology encompasses change detection and change captioning, each with its limitations in providing comprehensive interpretation. To address this, we propose an interactive Change-Agent, which can follow user instructions to achieve comprehensive change interpretation and insightful analysis according to user instructions, such as change detection and change captioning, change object counting, change cause analysis, etc. The Change-Agent integrates a multi-level change interpretation (MCI) model as the eyes and a large language model (LLM) as the brain. The MCI model contains two branches of pixel-level change detection and semantic-level change captioning, in which multiple BI-temporal Iterative Interaction (BI3) layers utilize Local Perception Enhancement (LPE) and the Global Difference Fusion Attention (GDFA) modules to enhance the model's discriminative feature representation capabilities. To support the training of the MCI model, we build the LEVIR-MCI dataset with a large number of change masks and captions of changes. Extensive experiments demonstrate the effectiveness of the proposed MCI model and highlight the promising potential of our Change-Agent in facilitating comprehensive and intelligent interpretation of surface changes. To facilitate future research, we will make our dataset and codebase of the MCI model and Change-Agent publicly available at https://github.com/Chen-Yang-Liu/Change-Agent
Benchmarking the Robustness of UAV Tracking Against Common Corruptions
Mar 18, 2024


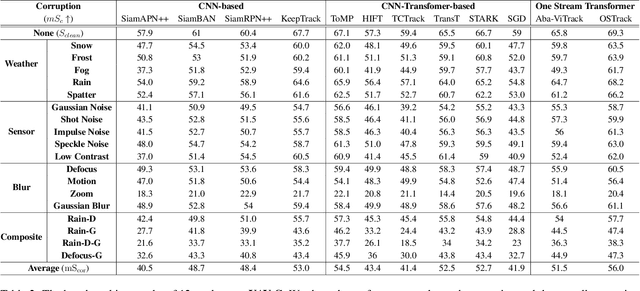
The robustness of unmanned aerial vehicle (UAV) tracking is crucial in many tasks like surveillance and robotics. Despite its importance, little attention is paid to the performance of UAV trackers under common corruptions due to lack of a dedicated platform. Addressing this, we propose UAV-C, a large-scale benchmark for assessing robustness of UAV trackers under common corruptions. Specifically, UAV-C is built upon two popular UAV datasets by introducing 18 common corruptions from 4 representative categories including adversarial, sensor, blur, and composite corruptions in different levels. Finally, UAV-C contains more than 10K sequences. To understand the robustness of existing UAV trackers against corruptions, we extensively evaluate 12 representative algorithms on UAV-C. Our study reveals several key findings: 1) Current trackers are vulnerable to corruptions, indicating more attention needed in enhancing the robustness of UAV trackers; 2) When accompanying together, composite corruptions result in more severe degradation to trackers; and 3) While each tracker has its unique performance profile, some trackers may be more sensitive to specific corruptions. By releasing UAV-C, we hope it, along with comprehensive analysis, serves as a valuable resource for advancing the robustness of UAV tracking against corruption. Our UAV-C will be available at https://github.com/Xiaoqiong-Liu/UAV-C.
TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
Mar 15, 2024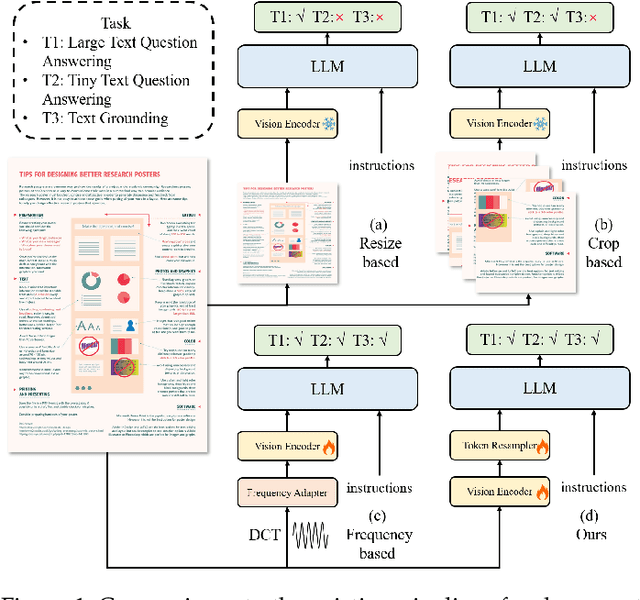
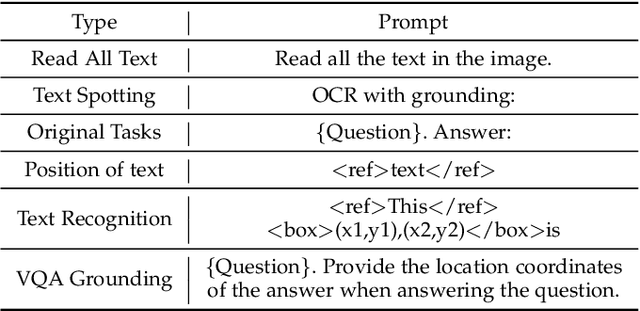
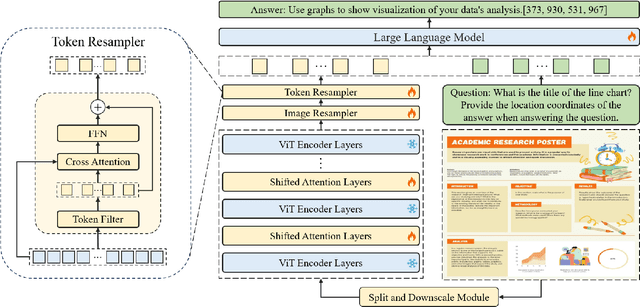
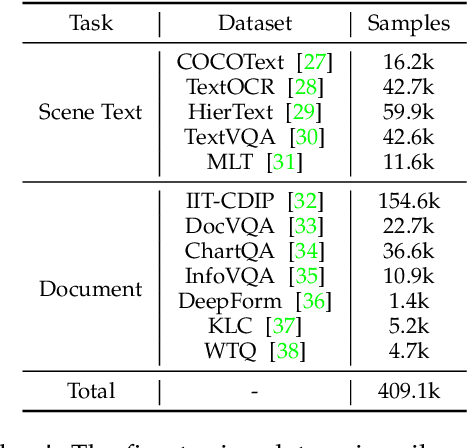
We present TextMonkey, a large multimodal model (LMM) tailored for text-centric tasks. Our approach introduces enhancement across several dimensions: By adopting Shifted Window Attention with zero-initialization, we achieve cross-window connectivity at higher input resolutions and stabilize early training; We hypothesize that images may contain redundant tokens, and by using similarity to filter out significant tokens, we can not only streamline the token length but also enhance the model's performance. Moreover, by expanding our model's capabilities to encompass text spotting and grounding, and incorporating positional information into responses, we enhance interpretability. It also learns to perform screenshot tasks through finetuning. Evaluation on 12 benchmarks shows notable improvements: 5.2% in Scene Text-Centric tasks (including STVQA, TextVQA, and OCRVQA), 6.9% in Document-Oriented tasks (such as DocVQA, InfoVQA, ChartVQA, DeepForm, Kleister Charity, and WikiTableQuestions), and 2.8% in Key Information Extraction tasks (comprising FUNSD, SROIE, and POIE). It outperforms in scene text spotting with a 10.9\% increase and sets a new standard on OCRBench, a comprehensive benchmark consisting of 29 OCR-related assessments, with a score of 561, surpassing previous open-sourced large multimodal models for document understanding. Code will be released at https://github.com/Yuliang-Liu/Monkey.
All in One: Multi-Task Prompting for Graph Neural Networks (Extended Abstract)
Mar 11, 2024
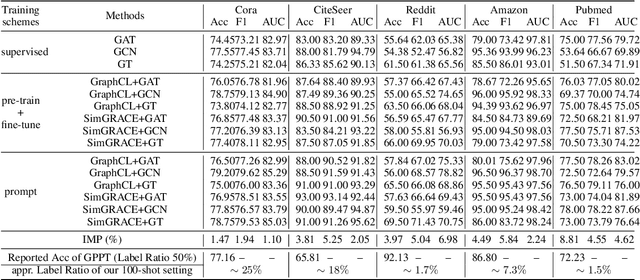
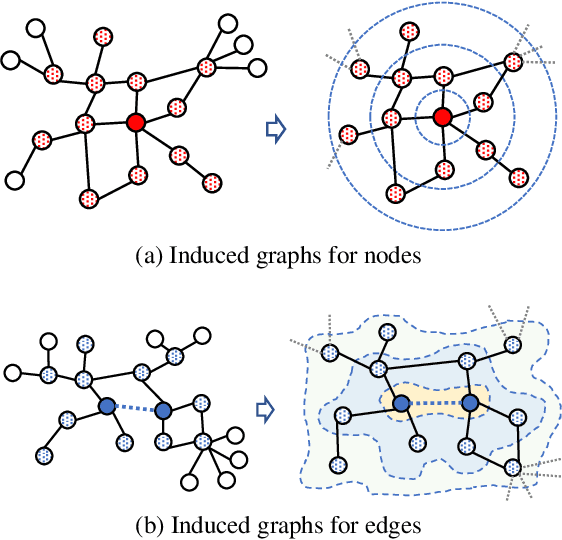
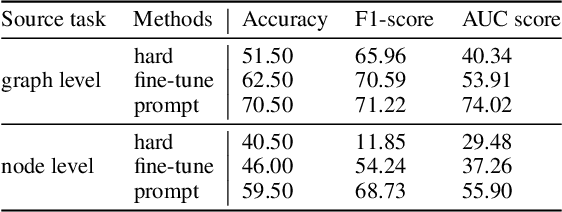
This paper is an extended abstract of our original work published in KDD23, where we won the best research paper award (Xiangguo Sun, Hong Cheng, Jia Li, Bo Liu, and Jihong Guan. All in one: Multi-task prompting for graph neural networks. KDD 23) The paper introduces a novel approach to bridging the gap between pre-trained graph models and the diverse tasks they're applied to, inspired by the success of prompt learning in NLP. Recognizing the challenge of aligning pre-trained models with varied graph tasks (node level, edge level, and graph level), which can lead to negative transfer and poor performance, we propose a multi-task prompting method for graphs. This method involves unifying graph and language prompt formats, enabling NLP's prompting strategies to be adapted for graph tasks. By analyzing the task space of graph applications, we reformulate problems to fit graph-level tasks and apply meta-learning to improve prompt initialization for multiple tasks. Experiments show our method's effectiveness in enhancing model performance across different graph tasks. Beyond the original work, in this extended abstract, we further discuss the graph prompt from a bigger picture and provide some of the latest work toward this area.
SM4Depth: Seamless Monocular Metric Depth Estimation across Multiple Cameras and Scenes by One Model
Mar 13, 2024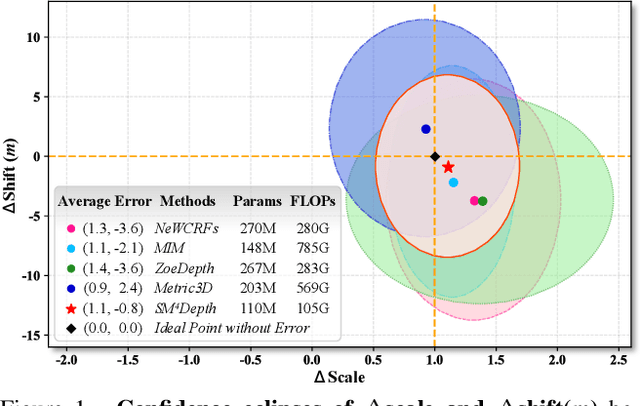
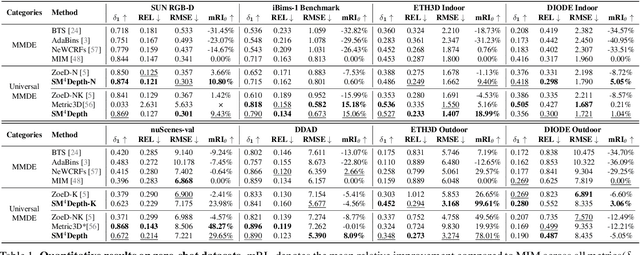

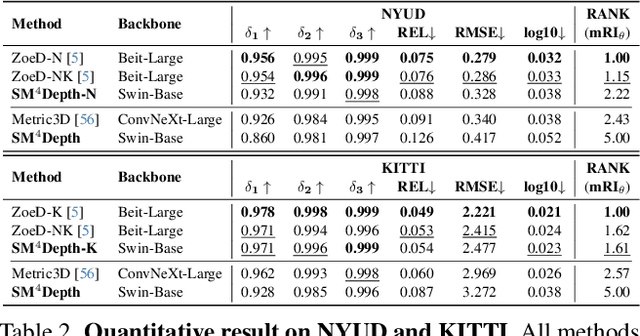
The generalization of monocular metric depth estimation (MMDE) has been a longstanding challenge. Recent methods made progress by combining relative and metric depth or aligning input image focal length. However, they are still beset by challenges in camera, scene, and data levels: (1) Sensitivity to different cameras; (2) Inconsistent accuracy across scenes; (3) Reliance on massive training data. This paper proposes SM4Depth, a seamless MMDE method, to address all the issues above within a single network. First, we reveal that a consistent field of view (FOV) is the key to resolve ``metric ambiguity'' across cameras, which guides us to propose a more straightforward preprocessing unit. Second, to achieve consistently high accuracy across scenes, we explicitly model the metric scale determination as discretizing the depth interval into bins and propose variation-based unnormalized depth bins. This method bridges the depth gap of diverse scenes by reducing the ambiguity of the conventional metric bin. Third, to reduce the reliance on massive training data, we propose a ``divide and conquer" solution. Instead of estimating directly from the vast solution space, the correct metric bins are estimated from multiple solution sub-spaces for complexity reduction. Finally, with just 150K RGB-D pairs and a consumer-grade GPU for training, SM4Depth achieves state-of-the-art performance on most previously unseen datasets, especially surpassing ZoeDepth and Metric3D on mRI$_\theta$. The code can be found at https://github.com/1hao-Liu/SM4Depth.
FedFMS: Exploring Federated Foundation Models for Medical Image Segmentation
Mar 08, 2024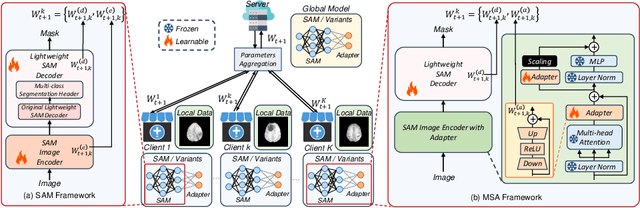
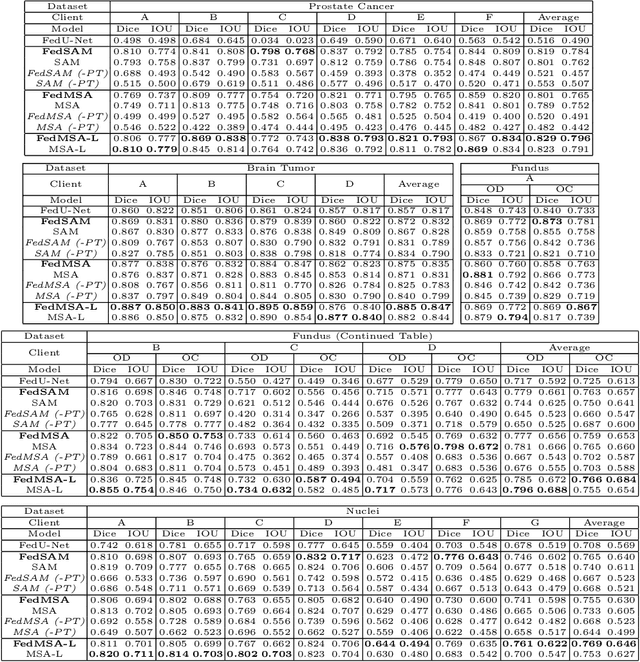
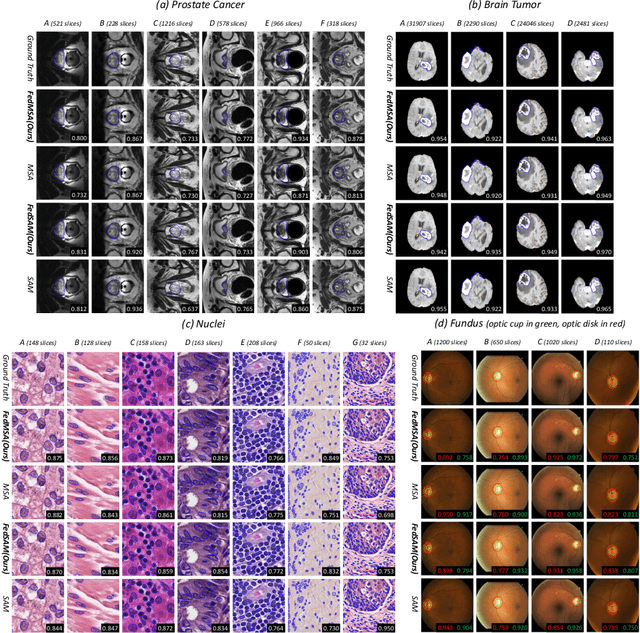

Medical image segmentation is crucial for clinical diagnosis. The Segmentation Anything Model (SAM) serves as a powerful foundation model for visual segmentation and can be adapted for medical image segmentation. However, medical imaging data typically contain privacy-sensitive information, making it challenging to train foundation models with centralized storage and sharing. To date, there are few foundation models tailored for medical image deployment within the federated learning framework, and the segmentation performance, as well as the efficiency of communication and training, remain unexplored. In response to these issues, we developed Federated Foundation models for Medical image Segmentation (FedFMS), which includes the Federated SAM (FedSAM) and a communication and training-efficient Federated SAM with Medical SAM Adapter (FedMSA). Comprehensive experiments on diverse datasets are conducted to investigate the performance disparities between centralized training and federated learning across various configurations of FedFMS. The experiments revealed that FedFMS could achieve performance comparable to models trained via centralized training methods while maintaining privacy. Furthermore, FedMSA demonstrated the potential to enhance communication and training efficiency. Our model implementation codes are available at https://github.com/LIU-YUXI/FedFMS.