 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Pang": models, code, and papers
Pattern Mining for Anomaly Detection in Graphs: Application to Fraud in Public Procurement
Jun 19, 2023



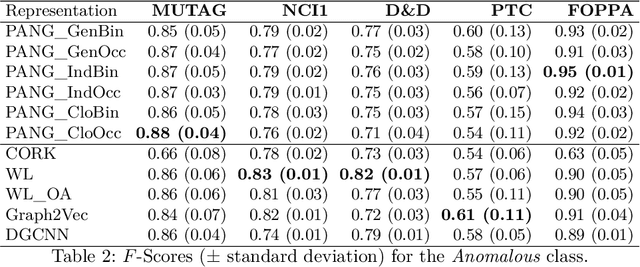
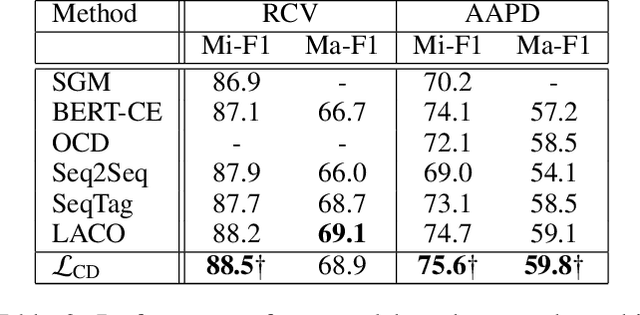
In the context of public procurement, several indicators called red flags are used to estimate fraud risk. They are computed according to certain contract attributes and are therefore dependent on the proper filling of the contract and award notices. However, these attributes are very often missing in practice, which prohibits red flags computation. Traditional fraud detection approaches focus on tabular data only, considering each contract separately, and are therefore very sensitive to this issue. In this work, we adopt a graph-based method allowing leveraging relations between contracts, to compensate for the missing attributes. We propose PANG (Pattern-Based Anomaly Detection in Graphs), a general supervised framework relying on pattern extraction to detect anomalous graphs in a collection of attributed graphs. Notably, it is able to identify induced subgraphs, a type of pattern widely overlooked in the literature. When benchmarked on standard datasets, its predictive performance is on par with state-of-the-art methods, with the additional advantage of being explainable. These experiments also reveal that induced patterns are more discriminative on certain datasets. When applying PANG to public procurement data, the prediction is superior to other methods, and it identifies subgraph patterns that are characteristic of fraud-prone situations, thereby making it possible to better understand fraudulent behavior.
Improving Adversarial Robustness with Hypersphere Embedding and Angular-based Regularizations
Mar 15, 2023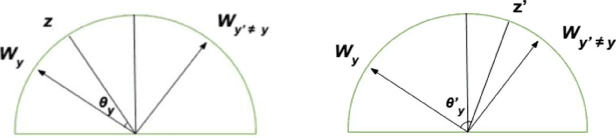



Adversarial training (AT) methods have been found to be effective against adversarial attacks on deep neural networks. Many variants of AT have been proposed to improve its performance. Pang et al. [1] have recently shown that incorporating hypersphere embedding (HE) into the existing AT procedures enhances robustness. We observe that the existing AT procedures are not designed for the HE framework, and thus fail to adequately learn the angular discriminative information available in the HE framework. In this paper, we propose integrating HE into AT with regularization terms that exploit the rich angular information available in the HE framework. Specifically, our method, termed angular-AT, adds regularization terms to AT that explicitly enforce weight-feature compactness and inter-class separation; all expressed in terms of angular features. Experimental results show that angular-AT further improves adversarial robustness.
Implicit Training of Energy Model for Structure Prediction
Nov 21, 2022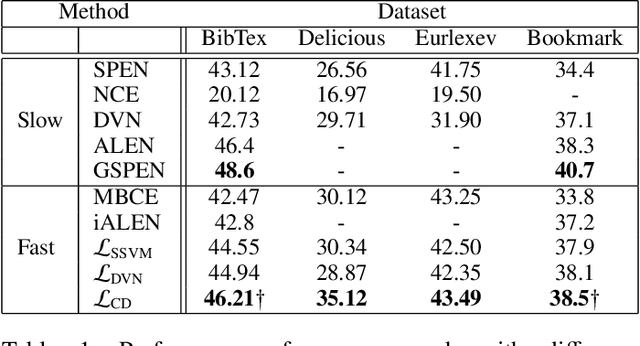
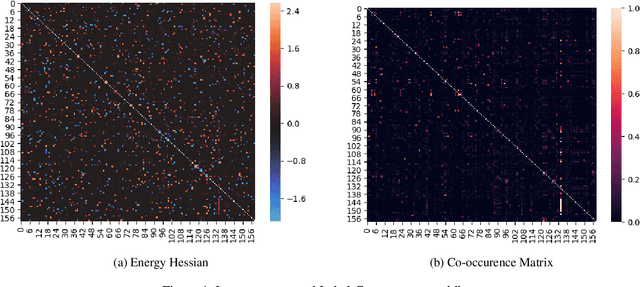
Most deep learning research has focused on developing new model and training procedures. On the other hand the training objective has usually been restricted to combinations of standard losses. When the objective aligns well with the evaluation metric, this is not a major issue. However when dealing with complex structured outputs, the ideal objective can be hard to optimize and the efficacy of usual objectives as a proxy for the true objective can be questionable. In this work, we argue that the existing inference network based structure prediction methods ( Tu and Gimpel 2018; Tu, Pang, and Gimpel 2020) are indirectly learning to optimize a dynamic loss objective parameterized by the energy model. We then explore using implicit-gradient based technique to learn the corresponding dynamic objectives. Our experiments show that implicitly learning a dynamic loss landscape is an effective method for improving model performance in structure prediction.
SQuALITY: Building a Long-Document Summarization Dataset the Hard Way
May 23, 2022

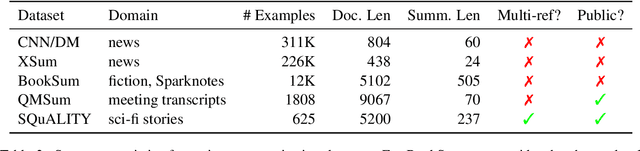

Summarization datasets are often assembled either by scraping naturally occurring public-domain summaries -- which are nearly always in difficult-to-work-with technical domains -- or by using approximate heuristics to extract them from everyday text -- which frequently yields unfaithful summaries. In this work, we turn to a slower but more straightforward approach to developing summarization benchmark data: We hire highly-qualified contractors to read stories and write original summaries from scratch. To amortize reading time, we collect five summaries per document, with the first giving an overview and the subsequent four addressing specific questions. We use this protocol to collect SQuALITY, a dataset of question-focused summaries built on the same public-domain short stories as the multiple-choice dataset QuALITY (Pang et al., 2021). Experiments with state-of-the-art summarization systems show that our dataset is challenging and that existing automatic evaluation metrics are weak indicators of quality.
MAg: a simple learning-based patient-level aggregation method for detecting microsatellite instability from whole-slide images
Jan 13, 2022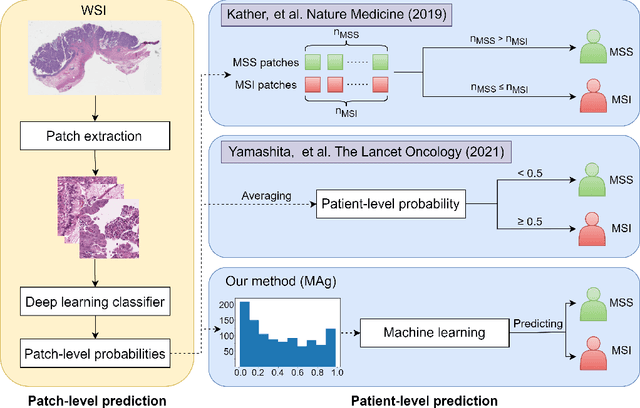
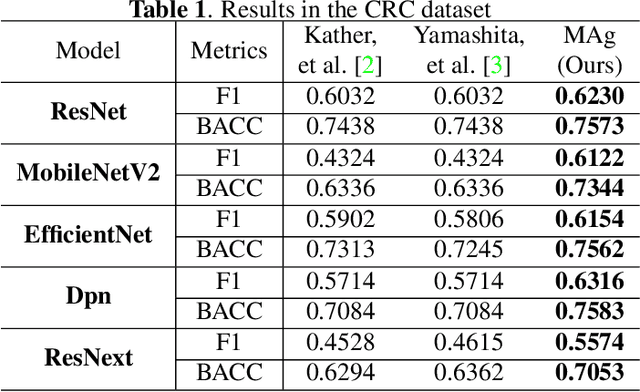
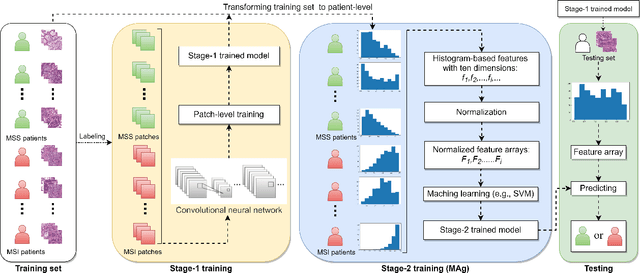
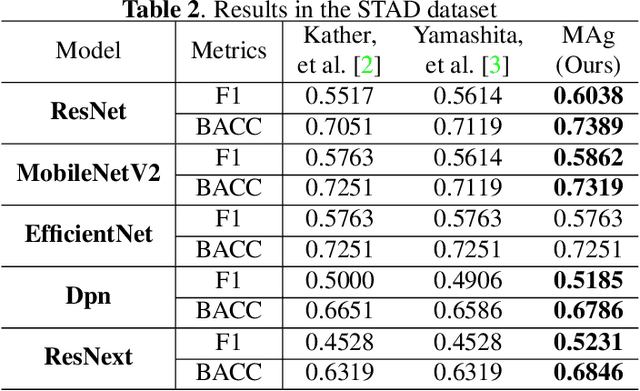
The prediction of microsatellite instability (MSI) and microsatellite stability (MSS) is essential in predicting both the treatment response and prognosis of gastrointestinal cancer. In clinical practice, a universal MSI testing is recommended, but the accessibility of such a test is limited. Thus, a more cost-efficient and broadly accessible tool is desired to cover the traditionally untested patients. In the past few years, deep-learning-based algorithms have been proposed to predict MSI directly from haematoxylin and eosin (H&E)-stained whole-slide images (WSIs). Such algorithms can be summarized as (1) patch-level MSI/MSS prediction, and (2) patient-level aggregation. Compared with the advanced deep learning approaches that have been employed for the first stage, only the na\"ive first-order statistics (e.g., averaging and counting) were employed in the second stage. In this paper, we propose a simple yet broadly generalizable patient-level MSI aggregation (MAg) method to effectively integrate the precious patch-level information. Briefly, the entire probabilistic distribution in the first stage is modeled as histogram-based features to be fused as the final outcome with machine learning (e.g., SVM). The proposed MAg method can be easily used in a plug-and-play manner, which has been evaluated upon five broadly used deep neural networks: ResNet, MobileNetV2, EfficientNet, Dpn and ResNext. From the results, the proposed MAg method consistently improves the accuracy of patient-level aggregation for two publicly available datasets. It is our hope that the proposed method could potentially leverage the low-cost H&E based MSI detection method. The code of our work has been made publicly available at https://github.com/Calvin-Pang/MAg.
Proceedings of the 2017 ICML Workshop on Human Interpretability in Machine Learning (WHI 2017)
Aug 08, 2017This is the Proceedings of the 2017 ICML Workshop on Human Interpretability in Machine Learning (WHI 2017), which was held in Sydney, Australia, August 10, 2017. Invited speakers were Tony Jebara, Pang Wei Koh, and David Sontag.
The Daunting Task of Real-World Textual Style Transfer Auto-Evaluation
Oct 10, 2019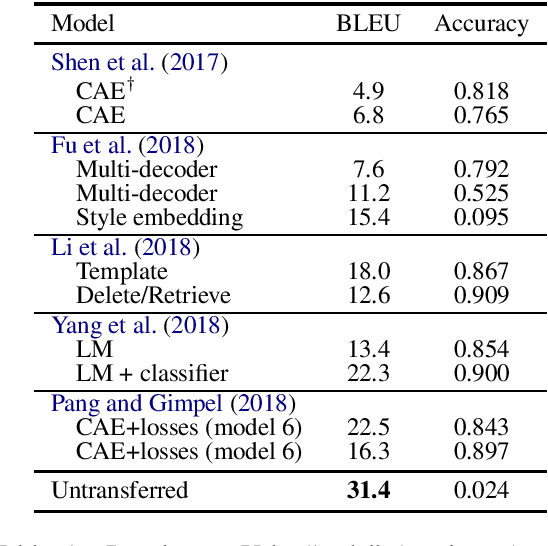
The difficulty of textual style transfer lies in the lack of parallel corpora. Numerous advances have been proposed for the unsupervised generation. However, significant problems remain with the auto-evaluation of style transfer tasks. Based on the summary of Pang and Gimpel (2018) and Mir et al. (2019), style transfer evaluations rely on three criteria: style accuracy of transferred sentences, content similarity between original and transferred sentences, and fluency of transferred sentences. We elucidate the problematic current state of style transfer research. Given that current tasks do not represent real use cases of style transfer, current auto-evaluation approach is flawed. This discussion aims to bring researchers to think about the future of style transfer and style transfer evaluation research.
An Adaptive Weighted Deep Forest Classifier
Jan 04, 2019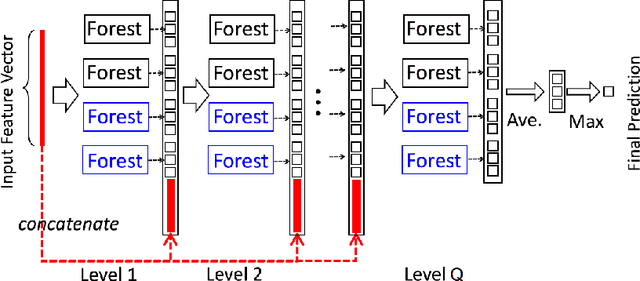
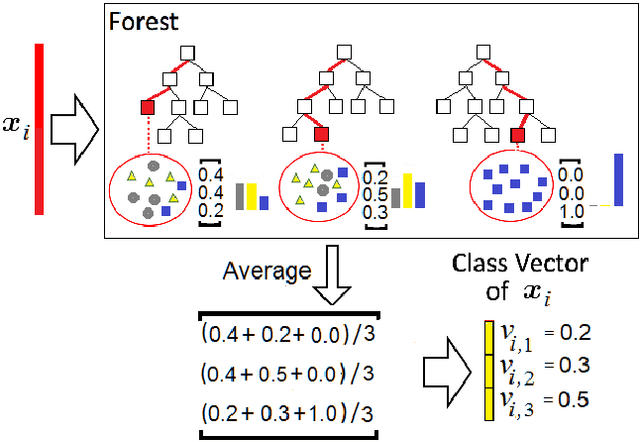
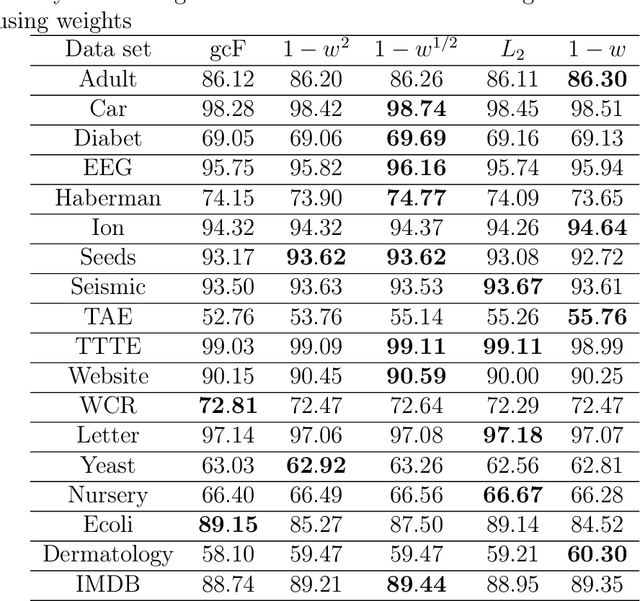
A modification of the confidence screening mechanism based on adaptive weighing of every training instance at each cascade level of the Deep Forest is proposed. The idea underlying the modification is very simple and stems from the confidence screening mechanism idea proposed by Pang et al. to simplify the Deep Forest classifier by means of updating the training set at each level in accordance with the classification accuracy of every training instance. However, if the confidence screening mechanism just removes instances from training and testing processes, then the proposed modification is more flexible and assigns weights by taking into account the classification accuracy. The modification is similar to the AdaBoost to some extent. Numerical experiments illustrate good performance of the proposed modification in comparison with the original Deep Forest proposed by Zhou and Feng.
Datasheets for Datasets
Jul 09, 2018


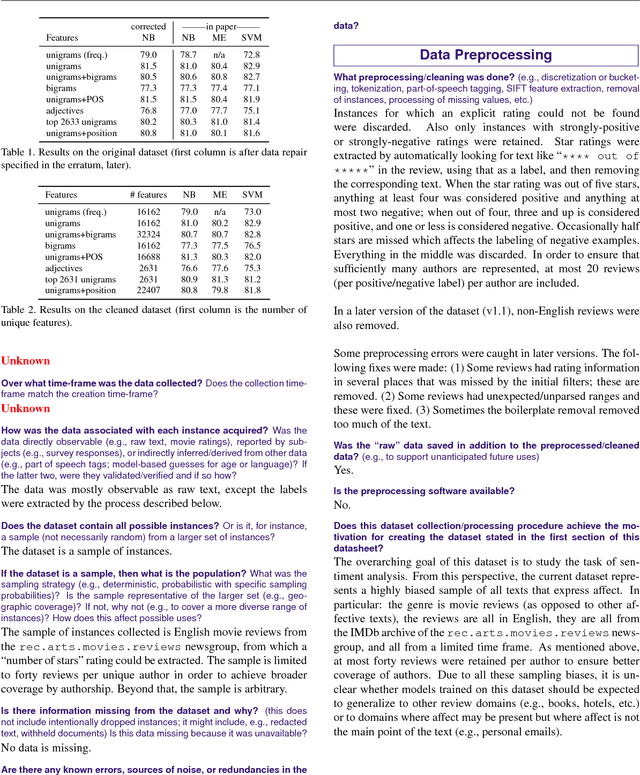
Currently there is no standard way to identify how a dataset was created, and what characteristics, motivations, and potential skews it represents. To begin to address this issue, we propose the concept of a datasheet for datasets, a short document to accompany public datasets, commercial APIs, and pretrained models. The goal of this proposal is to enable better communication between dataset creators and users, and help the AI community move toward greater transparency and accountability. By analogy, in computer hardware, it has become industry standard to accompany everything from the simplest components (e.g., resistors), to the most complex microprocessor chips, with datasheets detailing standard operating characteristics, test results, recommended usage, and other information. We outline some of the questions a datasheet for datasets should answer. These questions focus on when, where, and how the training data was gathered, its recommended use cases, and, in the case of human-centric datasets, information regarding the subjects' demographics and consent as applicable. We develop prototypes of datasheets for two well-known datasets: Labeled Faces in The Wild and the Pang \& Lee Polarity Dataset.