 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Peters": models, code, and papers
Invariant Causal Prediction with Locally Linear Models
Jan 10, 2024
We consider the task of identifying the causal parents of a target variable among a set of candidate variables from observational data. Our main assumption is that the candidate variables are observed in different environments which may, for example, correspond to different settings of a machine or different time intervals in a dynamical process. Under certain assumptions different environments can be regarded as interventions on the observed system. We assume a linear relationship between target and covariates, which can be different in each environment with the only restriction that the causal structure is invariant across environments. This is an extension of the ICP ($\textbf{I}$nvariant $\textbf{C}$ausal $\textbf{P}$rediction) principle by Peters et al. [2016], who assumed a fixed linear relationship across all environments. Within our proposed setting we provide sufficient conditions for identifiability of the causal parents and introduce a practical method called LoLICaP ($\textbf{Lo}$cally $\textbf{L}$inear $\textbf{I}$nvariant $\textbf{Ca}$usal $\textbf{P}$rediction), which is based on a hypothesis test for parent identification using a ratio of minimum and maximum statistics. We then show in a simplified setting that the statistical power of LoLICaP converges exponentially fast in the sample size, and finally we analyze the behavior of LoLICaP experimentally in more general settings.
Where exactly does contextualization in a PLM happen?
Dec 11, 2023Pre-trained Language Models (PLMs) have shown to be consistently successful in a plethora of NLP tasks due to their ability to learn contextualized representations of words (Ethayarajh, 2019). BERT (Devlin et al., 2018), ELMo (Peters et al., 2018) and other PLMs encode word meaning via textual context, as opposed to static word embeddings, which encode all meanings of a word in a single vector representation. In this work, we present a study that aims to localize where exactly in a PLM word contextualization happens. In order to find the location of this word meaning transformation, we investigate representations of polysemous words in the basic BERT uncased 12 layer architecture (Devlin et al., 2018), a masked language model trained on an additional sentence adjacency objective, using qualitative and quantitative measures.
Proportional Fairness in Clustering: A Social Choice Perspective
Oct 27, 2023We study the proportional clustering problem of Chen et al. [ICML'19] and relate it to the area of multiwinner voting in computational social choice. We show that any clustering satisfying a weak proportionality notion of Brill and Peters [EC'23] simultaneously obtains the best known approximations to the proportional fairness notion of Chen et al. [ICML'19], but also to individual fairness [Jung et al., FORC'20] and the "core" [Li et al. ICML'21]. In fact, we show that any approximation to proportional fairness is also an approximation to individual fairness and vice versa. Finally, we also study stronger notions of proportional representation, in which deviations do not only happen to single, but multiple candidate centers, and show that stronger proportionality notions of Brill and Peters [EC'23] imply approximations to these stronger guarantees.
Activation Addition: Steering Language Models Without Optimization
Aug 20, 2023Reliably controlling the behavior of large language models (LLMs) is a pressing open problem. Existing methods include supervised finetuning, reinforcement learning from human feedback (RLHF), prompt engineering and guided decoding. We instead investigate activation engineering: modifying activations at inference time to predictably alter model behavior. In particular, we bias the forward pass with an added 'steering vector' implicitly specified through natural language. Unlike past work which learned these steering vectors (Subramani, Suresh, and Peters 2022; Hernandez, Li, and Andreas 2023), our Activation Addition (ActAdd) method computes them by taking the activation differences that result from pairs of prompts. We demonstrate ActAdd on GPT-2 on OpenWebText and ConceptNet. Our inference-time approach yields control over high-level properties of output and preserves off-target model performance. It involves far less compute and implementation effort compared to finetuning or RLHF, allows users to provide natural language specifications, and its overhead scales naturally with model size.
Model-based causal feature selection for general response types
Sep 22, 2023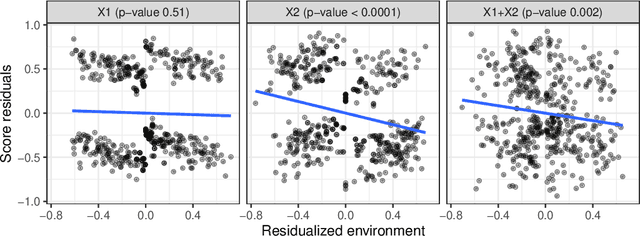


Discovering causal relationships from observational data is a fundamental yet challenging task. In some applications, it may suffice to learn the causal features of a given response variable, instead of learning the entire underlying causal structure. Invariant causal prediction (ICP, Peters et al., 2016) is a method for causal feature selection which requires data from heterogeneous settings. ICP assumes that the mechanism for generating the response from its direct causes is the same in all settings and exploits this invariance to output a subset of the causal features. The framework of ICP has been extended to general additive noise models and to nonparametric settings using conditional independence testing. However, nonparametric conditional independence testing often suffers from low power (or poor type I error control) and the aforementioned parametric models are not suitable for applications in which the response is not measured on a continuous scale, but rather reflects categories or counts. To bridge this gap, we develop ICP in the context of transformation models (TRAMs), allowing for continuous, categorical, count-type, and uninformatively censored responses (we show that, in general, these model classes do not allow for identifiability when there is no exogenous heterogeneity). We propose TRAM-GCM, a test for invariance of a subset of covariates, based on the expected conditional covariance between environments and score residuals which satisfies uniform asymptotic level guarantees. For the special case of linear shift TRAMs, we propose an additional invariance test, TRAM-Wald, based on the Wald statistic. We implement both proposed methods in the open-source R package "tramicp" and show in simulations that under the correct model specification, our approach empirically yields higher power than nonparametric ICP based on conditional independence testing.
Differentially Private Conditional Independence Testing
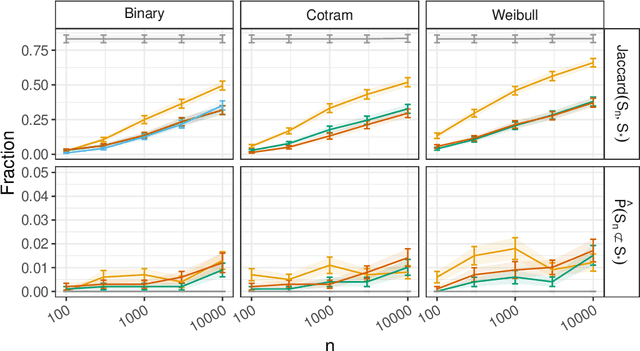
Jun 11, 2023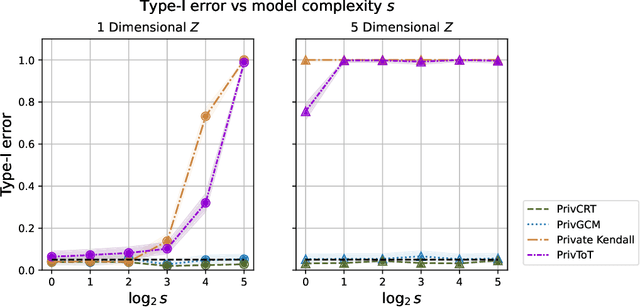
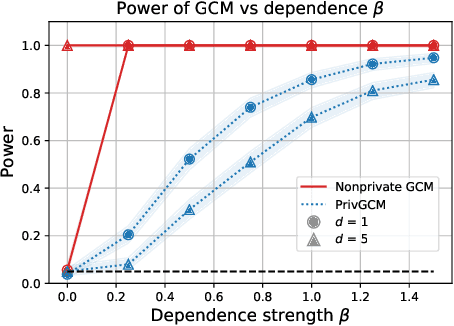
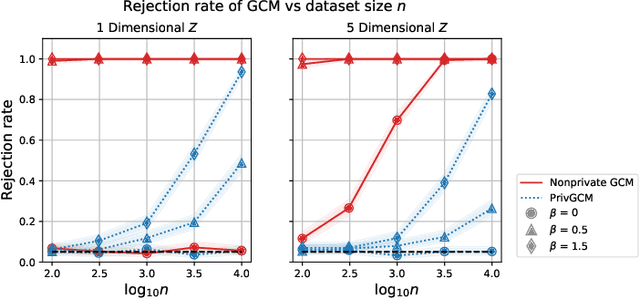
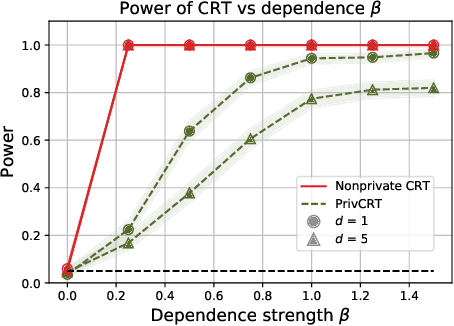
Conditional independence (CI) tests are widely used in statistical data analysis, e.g., they are the building block of many algorithms for causal graph discovery. The goal of a CI test is to accept or reject the null hypothesis that $X \perp \!\!\! \perp Y \mid Z$, where $X \in \mathbb{R}, Y \in \mathbb{R}, Z \in \mathbb{R}^d$. In this work, we investigate conditional independence testing under the constraint of differential privacy. We design two private CI testing procedures: one based on the generalized covariance measure of Shah and Peters (2020) and another based on the conditional randomization test of Cand\`es et al. (2016) (under the model-X assumption). We provide theoretical guarantees on the performance of our tests and validate them empirically. These are the first private CI tests that work for the general case when $Z$ is continuous.
Capacity Studies for a Differential Growing Neural Gas
Dec 23, 2022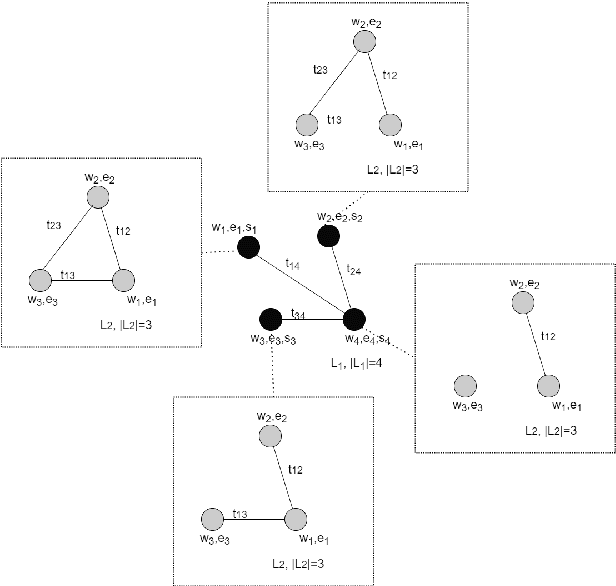
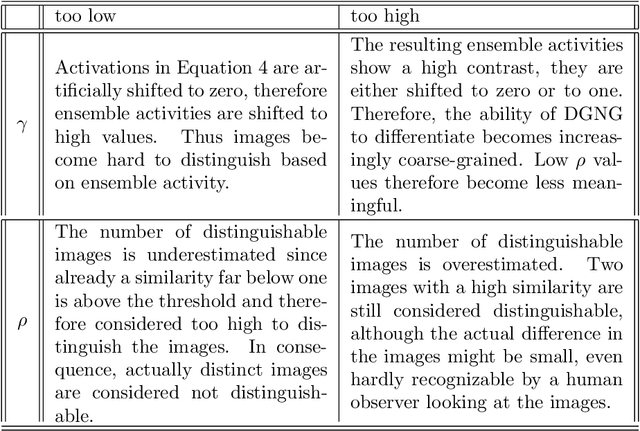

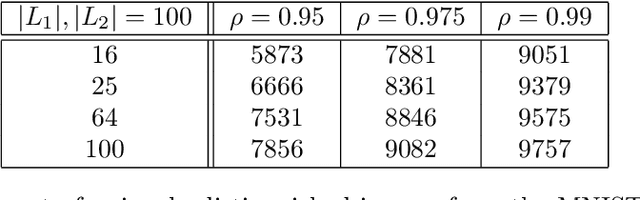
In 2019 Kerdels and Peters proposed a grid cell model (GCM) based on a Differential Growing Neural Gas (DGNG) network architecture as a computationally efficient way to model an Autoassociative Memory Cell (AMC) \cite{Kerdels_Peters_2019}. An important feature of the DGNG architecture with respect to possible applications in the field of computational neuroscience is its \textit{capacity} refering to its capability to process and uniquely distinguish input signals and therefore obtain a valid representation of the input space. This study evaluates the capacity of a two layered DGNG grid cell model on the Fashion-MNIST dataset. The focus on the study lies on the variation of layer sizes to improve the understanding of capacity properties in relation to network parameters as well as its scaling properties. Additionally, parameter discussions and a plausability check with a pixel/segment variation method are provided. It is concluded, that the DGNG model is able to obtain a meaningful and plausible representation of the input space and to cope with the complexity of the Fashion-MNIST dataset even at moderate layer sizes.
Reasoning About Causal Models With Infinitely Many Variables
Dec 21, 2021Generalized structural equations models (GSEMs) [Peters and Halpern 2021], are, as the name suggests, a generalization of structural equations models (SEMs). They can deal with (among other things) infinitely many variables with infinite ranges, which is critical for capturing dynamical systems. We provide a sound and complete axiomatization of causal reasoning in GSEMs that is an extension of the sound and complete axiomatization provided by Halpern [2000] for SEMs. Considering GSEMs helps clarify what properties Halpern's axioms capture.
Speeding Up Entmax
Nov 15, 2021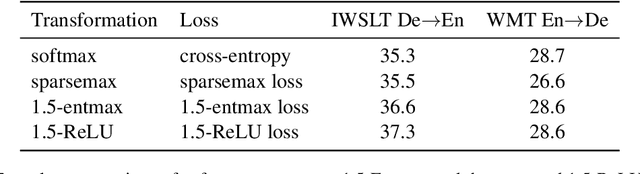
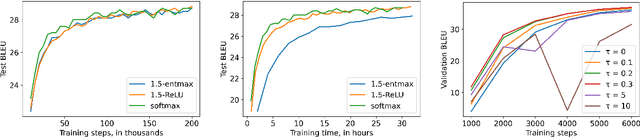
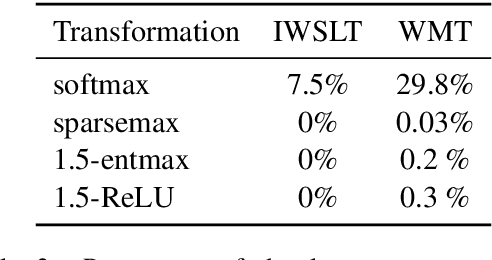
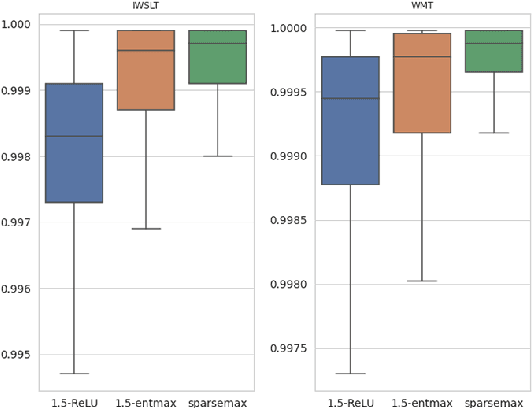
Softmax is the de facto standard in modern neural networks for language processing when it comes to normalizing logits. However, by producing a dense probability distribution each token in the vocabulary has a nonzero chance of being selected at each generation step, leading to a variety of reported problems in text generation. $\alpha$-entmax of Peters et al. (2019, arXiv:1905.05702) solves this problem, but is considerably slower than softmax. In this paper, we propose an alternative to $\alpha$-entmax, which keeps its virtuous characteristics, but is as fast as optimized softmax and achieves on par or better performance in machine translation task.
Variance Minimization in the Wasserstein Space for Invariant Causal Prediction
Oct 13, 2021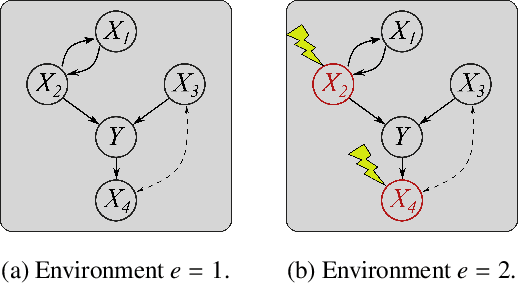
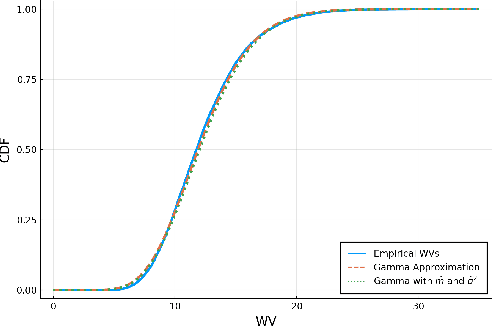
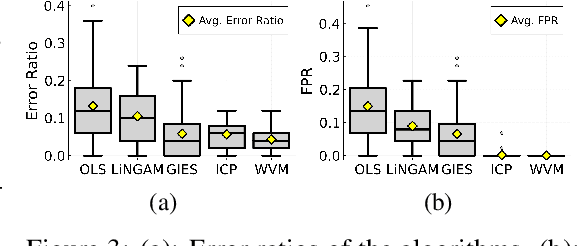
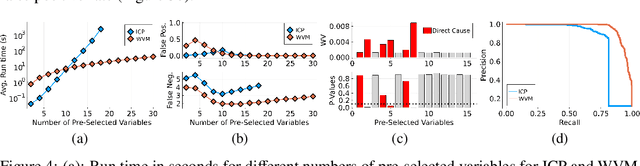
Selecting powerful predictors for an outcome is a cornerstone task for machine learning. However, some types of questions can only be answered by identifying the predictors that causally affect the outcome. A recent approach to this causal inference problem leverages the invariance property of a causal mechanism across differing experimental environments (Peters et al., 2016; Heinze-Deml et al., 2018). This method, invariant causal prediction (ICP), has a substantial computational defect -- the runtime scales exponentially with the number of possible causal variables. In this work, we show that the approach taken in ICP may be reformulated as a series of nonparametric tests that scales linearly in the number of predictors. Each of these tests relies on the minimization of a novel loss function -- the Wasserstein variance -- that is derived from tools in optimal transport theory and is used to quantify distributional variability across environments. We prove under mild assumptions that our method is able to recover the set of identifiable direct causes, and we demonstrate in our experiments that it is competitive with other benchmark causal discovery algorithms.