 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Qi": models, code, and papers
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates
Feb 28, 2024
Public LLMs such as the Llama 2-Chat have driven huge activity in LLM research. These models underwent alignment training and were considered safe. Recently Qi et al. (2023) reported that even benign fine-tuning (e.g., on seemingly safe datasets) can give rise to unsafe behaviors in the models. The current paper is about methods and best practices to mitigate such loss of alignment. Through extensive experiments on several chat models (Meta's Llama 2-Chat, Mistral AI's Mistral 7B Instruct v0.2, and OpenAI's GPT-3.5 Turbo), this paper uncovers that the prompt templates used during fine-tuning and inference play a crucial role in preserving safety alignment, and proposes the "Pure Tuning, Safe Testing" (PTST) principle -- fine-tune models without a safety prompt, but include it at test time. Fine-tuning experiments on GSM8K, ChatDoctor, and OpenOrca show that PTST significantly reduces the rise of unsafe behaviors, and even almost eliminates them in some cases.
Counterfactual Generation with Identifiability Guarantees
Feb 23, 2024Counterfactual generation lies at the core of various machine learning tasks, including image translation and controllable text generation. This generation process usually requires the identification of the disentangled latent representations, such as content and style, that underlie the observed data. However, it becomes more challenging when faced with a scarcity of paired data and labeling information. Existing disentangled methods crucially rely on oversimplified assumptions, such as assuming independent content and style variables, to identify the latent variables, even though such assumptions may not hold for complex data distributions. For instance, food reviews tend to involve words like tasty, whereas movie reviews commonly contain words such as thrilling for the same positive sentiment. This problem is exacerbated when data are sampled from multiple domains since the dependence between content and style may vary significantly over domains. In this work, we tackle the domain-varying dependence between the content and the style variables inherent in the counterfactual generation task. We provide identification guarantees for such latent-variable models by leveraging the relative sparsity of the influences from different latent variables. Our theoretical insights enable the development of a doMain AdapTive counTerfactual gEneration model, called (MATTE). Our theoretically grounded framework achieves state-of-the-art performance in unsupervised style transfer tasks, where neither paired data nor style labels are utilized, across four large-scale datasets. Code is available at https://github.com/hanqi-qi/Matte.git
VoltSchemer: Use Voltage Noise to Manipulate Your Wireless Charger
Feb 18, 2024Wireless charging is becoming an increasingly popular charging solution in portable electronic products for a more convenient and safer charging experience than conventional wired charging. However, our research identified new vulnerabilities in wireless charging systems, making them susceptible to intentional electromagnetic interference. These vulnerabilities facilitate a set of novel attack vectors, enabling adversaries to manipulate the charger and perform a series of attacks. In this paper, we propose VoltSchemer, a set of innovative attacks that grant attackers control over commercial-off-the-shelf wireless chargers merely by modulating the voltage from the power supply. These attacks represent the first of its kind, exploiting voltage noises from the power supply to manipulate wireless chargers without necessitating any malicious modifications to the chargers themselves. The significant threats imposed by VoltSchemer are substantiated by three practical attacks, where a charger can be manipulated to: control voice assistants via inaudible voice commands, damage devices being charged through overcharging or overheating, and bypass Qi-standard specified foreign-object-detection mechanism to damage valuable items exposed to intense magnetic fields. We demonstrate the effectiveness and practicality of the VoltSchemer attacks with successful attacks on 9 top-selling COTS wireless chargers. Furthermore, we discuss the security implications of our findings and suggest possible countermeasures to mitigate potential threats.
QI-TTS: Questioning Intonation Control for Emotional Speech Synthesis
Mar 14, 2023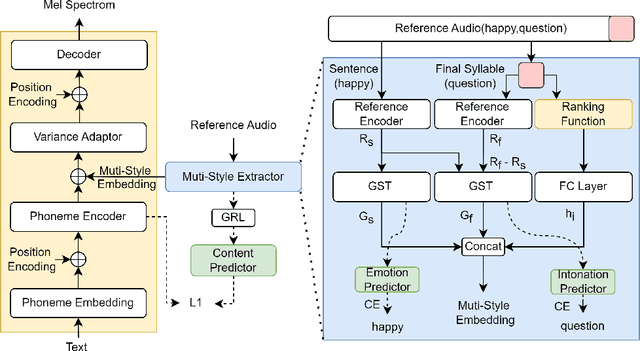


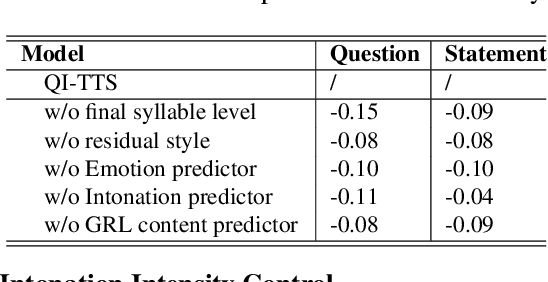
Recent expressive text to speech (TTS) models focus on synthesizing emotional speech, but some fine-grained styles such as intonation are neglected. In this paper, we propose QI-TTS which aims to better transfer and control intonation to further deliver the speaker's questioning intention while transferring emotion from reference speech. We propose a multi-style extractor to extract style embedding from two different levels. While the sentence level represents emotion, the final syllable level represents intonation. For fine-grained intonation control, we use relative attributes to represent intonation intensity at the syllable level.Experiments have validated the effectiveness of QI-TTS for improving intonation expressiveness in emotional speech synthesis.
Ammonia-Net: A Multi-task Joint Learning Model for Multi-class Segmentation and Classification in Tooth-marked Tongue Diagnosis
Oct 05, 2023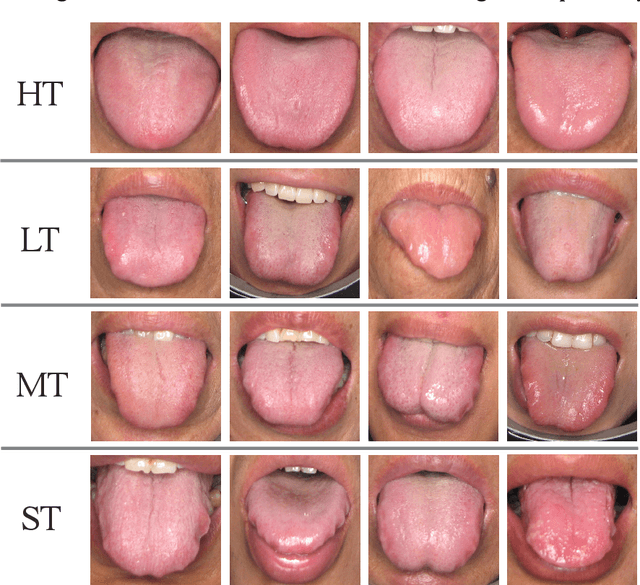

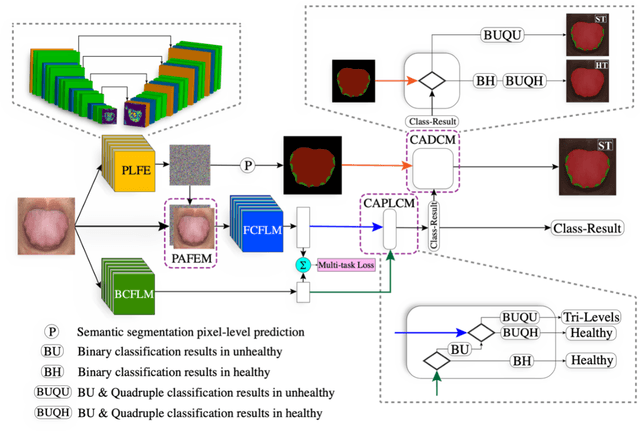
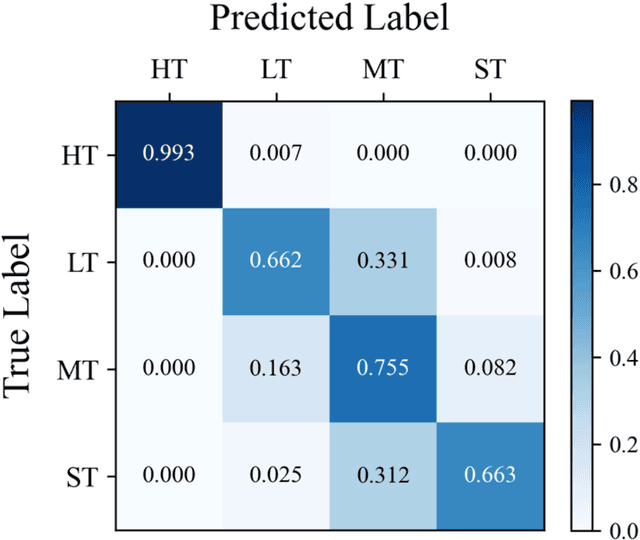
In Traditional Chinese Medicine, the tooth marks on the tongue, stemming from prolonged dental pressure, serve as a crucial indicator for assessing qi (yang) deficiency, which is intrinsically linked to visceral health. Manual diagnosis of tooth-marked tongue solely relies on experience. Nonetheless, the diversity in shape, color, and type of tooth marks poses a challenge to diagnostic accuracy and consistency. To address these problems, herein we propose a multi-task joint learning model named Ammonia-Net. This model employs a convolutional neural network-based architecture, specifically designed for multi-class segmentation and classification of tongue images. Ammonia-Net performs semantic segmentation of tongue images to identify tongue and tooth marks. With the assistance of segmentation output, it classifies the images into the desired number of classes: healthy tongue, light tongue, moderate tongue, and severe tongue. As far as we know, this is the first attempt to apply the semantic segmentation results of tooth marks for tooth-marked tongue classification. To train Ammonia-Net, we collect 856 tongue images from 856 subjects. After a number of extensive experiments, the experimental results show that the proposed model achieves 99.06% accuracy in the two-class classification task of tooth-marked tongue identification and 80.02%. As for the segmentation task, mIoU for tongue and tooth marks amounts to 71.65%.
JSMNet Improving Indoor Point Cloud Semantic and Instance Segmentation through Self-Attention and Multiscale
Sep 25, 2023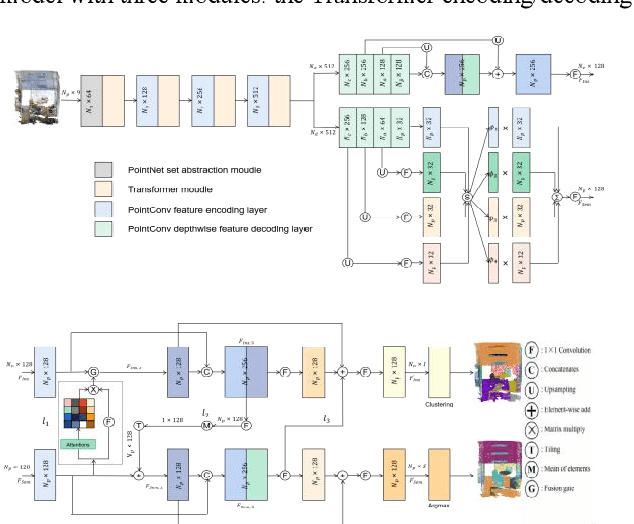
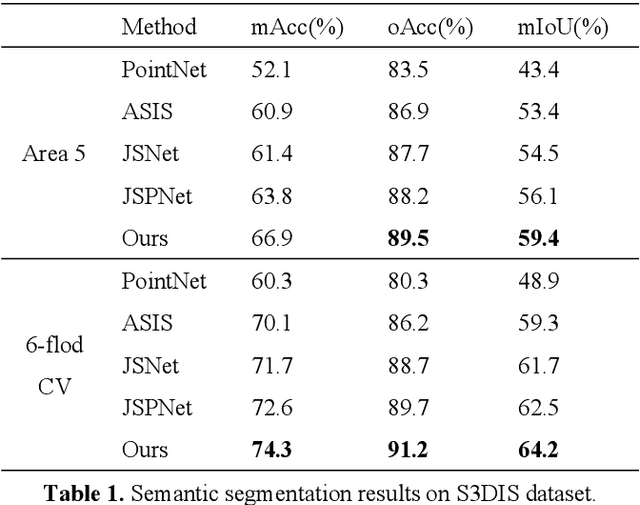
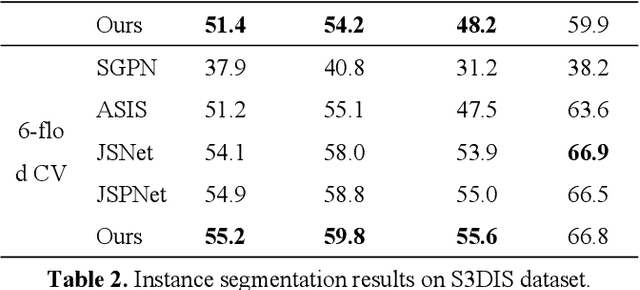
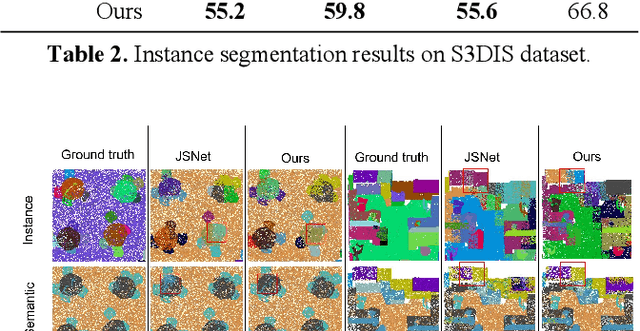
The semantic understanding of indoor 3D point cloud data is crucial for a range of subsequent applications, including indoor service robots, navigation systems, and digital twin engineering. Global features are crucial for achieving high-quality semantic and instance segmentation of indoor point clouds, as they provide essential long-range context information. To this end, we propose JSMNet, which combines a multi-layer network with a global feature self-attention module to jointly segment three-dimensional point cloud semantics and instances. To better express the characteristics of indoor targets, we have designed a multi-resolution feature adaptive fusion module that takes into account the differences in point cloud density caused by varying scanner distances from the target. Additionally, we propose a framework for joint semantic and instance segmentation by integrating semantic and instance features to achieve superior results. We conduct experiments on S3DIS, which is a large three-dimensional indoor point cloud dataset. Our proposed method is compared against other methods, and the results show that it outperforms existing methods in semantic and instance segmentation and provides better results in target local area segmentation. Specifically, our proposed method outperforms PointNet (Qi et al., 2017a) by 16.0% and 26.3% in terms of semantic segmentation mIoU in S3DIS (Area 5) and instance segmentation mPre, respectively. Additionally, it surpasses ASIS (Wang et al., 2019) by 6.0% and 4.6%, respectively, as well as JSPNet (Chen et al., 2022) by a margin of 3.3% for semantic segmentation mIoU and a slight improvement of 0.3% for instance segmentation mPre.
Improving Text Matching in E-Commerce Search with A Rationalizable, Intervenable and Fast Entity-Based Relevance Model
Jul 01, 2023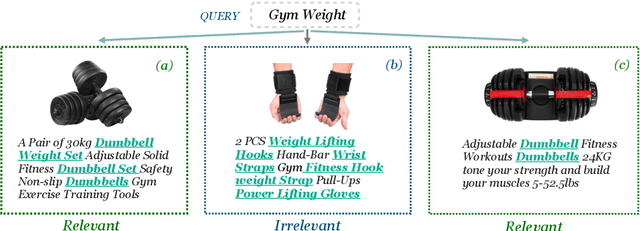

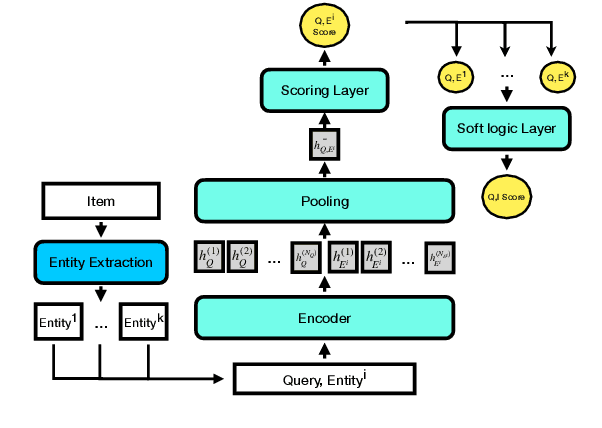
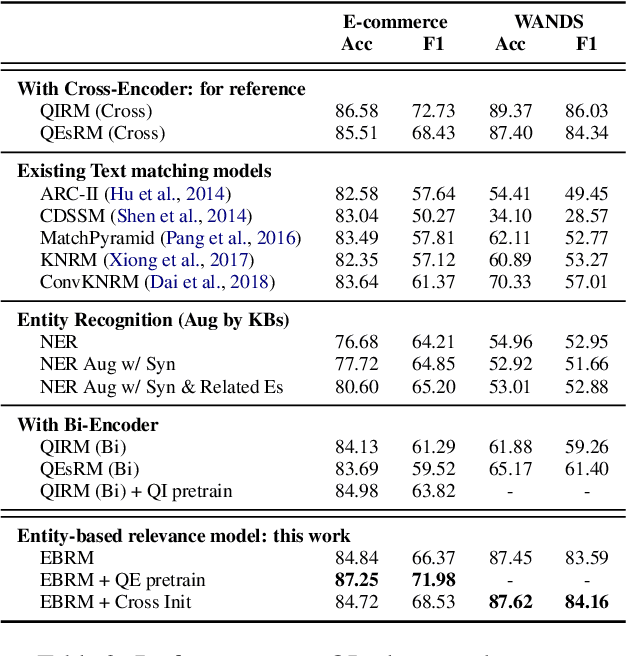
Discovering the intended items of user queries from a massive repository of items is one of the main goals of an e-commerce search system. Relevance prediction is essential to the search system since it helps improve performance. When online serving a relevance model, the model is required to perform fast and accurate inference. Currently, the widely used models such as Bi-encoder and Cross-encoder have their limitations in accuracy or inference speed respectively. In this work, we propose a novel model called the Entity-Based Relevance Model (EBRM). We identify the entities contained in an item and decompose the QI (query-item) relevance problem into multiple QE (query-entity) relevance problems; we then aggregate their results to form the QI prediction using a soft logic formulation. The decomposition allows us to use a Cross-encoder QE relevance module for high accuracy as well as cache QE predictions for fast online inference. Utilizing soft logic makes the prediction procedure interpretable and intervenable. We also show that pretraining the QE module with auto-generated QE data from user logs can further improve the overall performance. The proposed method is evaluated on labeled data from e-commerce websites. Empirical results show that it achieves promising improvements with computation efficiency.
Balanced Classification: A Unified Framework for Long-Tailed Object Detection
Aug 04, 2023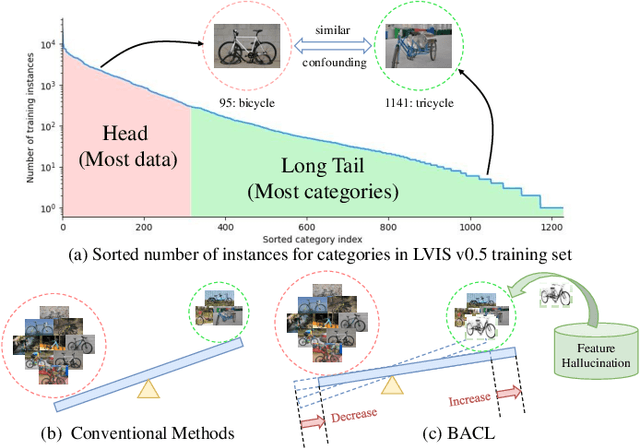
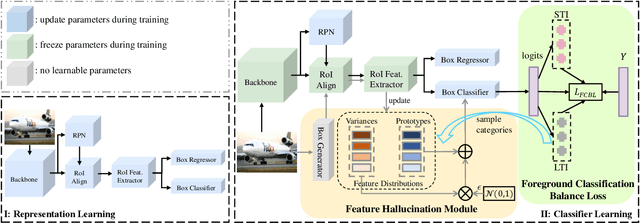
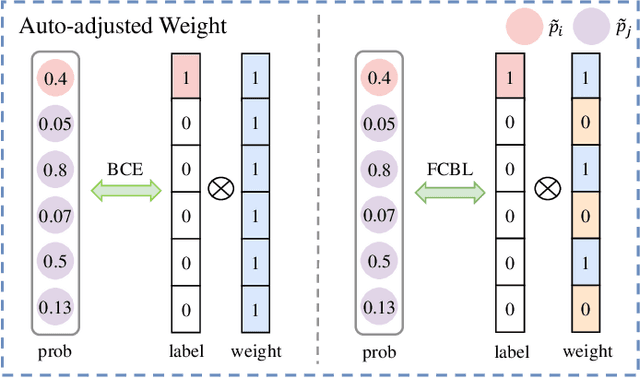
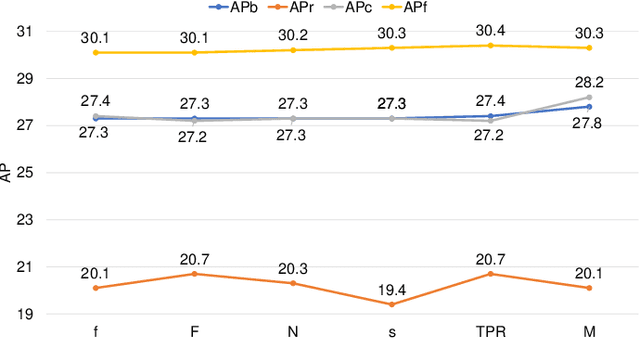
Conventional detectors suffer from performance degradation when dealing with long-tailed data due to a classification bias towards the majority head categories. In this paper, we contend that the learning bias originates from two factors: 1) the unequal competition arising from the imbalanced distribution of foreground categories, and 2) the lack of sample diversity in tail categories. To tackle these issues, we introduce a unified framework called BAlanced CLassification (BACL), which enables adaptive rectification of inequalities caused by disparities in category distribution and dynamic intensification of sample diversities in a synchronized manner. Specifically, a novel foreground classification balance loss (FCBL) is developed to ameliorate the domination of head categories and shift attention to difficult-to-differentiate categories by introducing pairwise class-aware margins and auto-adjusted weight terms, respectively. This loss prevents the over-suppression of tail categories in the context of unequal competition. Moreover, we propose a dynamic feature hallucination module (FHM), which enhances the representation of tail categories in the feature space by synthesizing hallucinated samples to introduce additional data variances. In this divide-and-conquer approach, BACL sets a new state-of-the-art on the challenging LVIS benchmark with a decoupled training pipeline, surpassing vanilla Faster R-CNN with ResNet-50-FPN by 5.8% AP and 16.1% AP for overall and tail categories. Extensive experiments demonstrate that BACL consistently achieves performance improvements across various datasets with different backbones and architectures. Code and models are available at https://github.com/Tianhao-Qi/BACL.
Rapid Phase Ambiguity Elimination Methods for DOA Estimator via Hybrid Massive MIMO Receive Array
Apr 27, 2022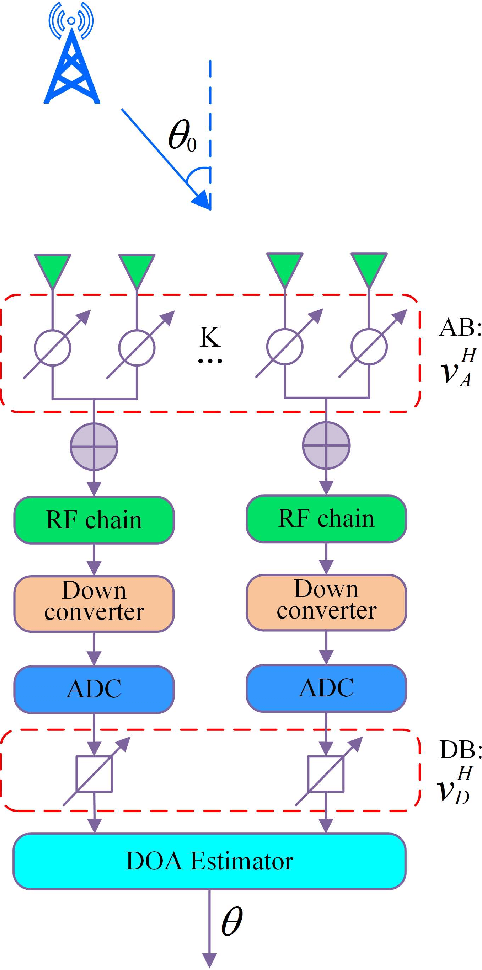
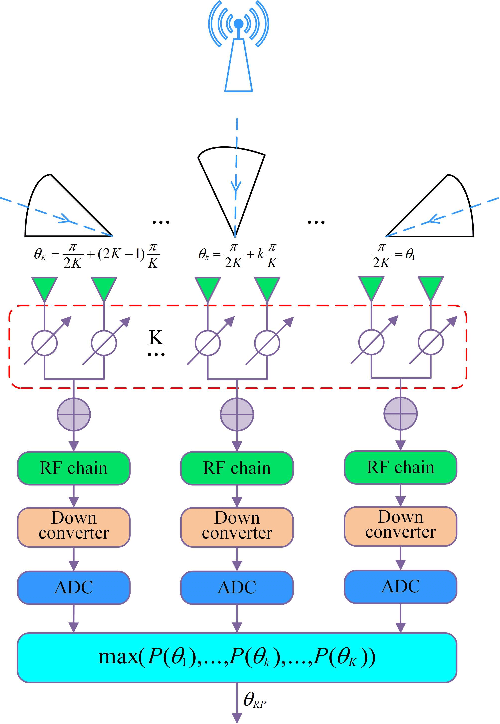
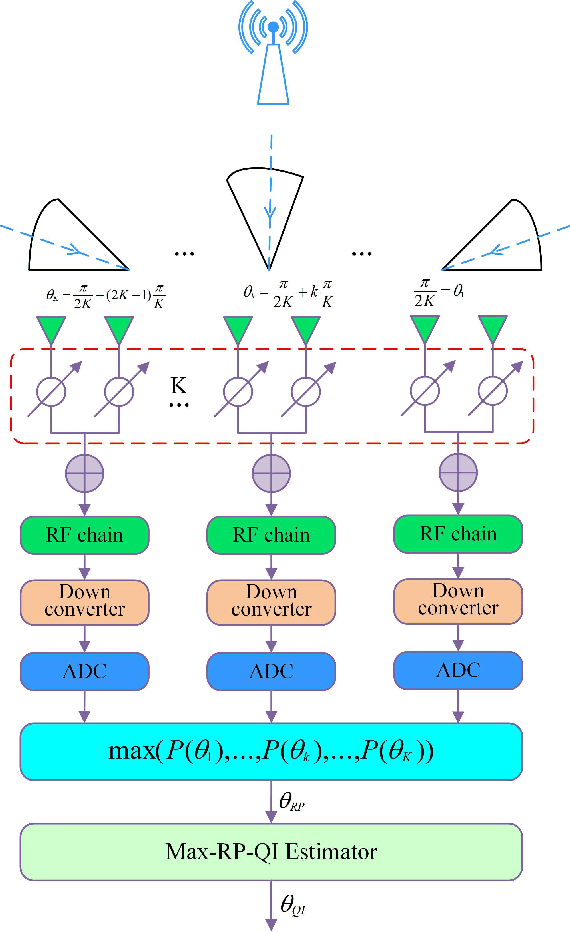
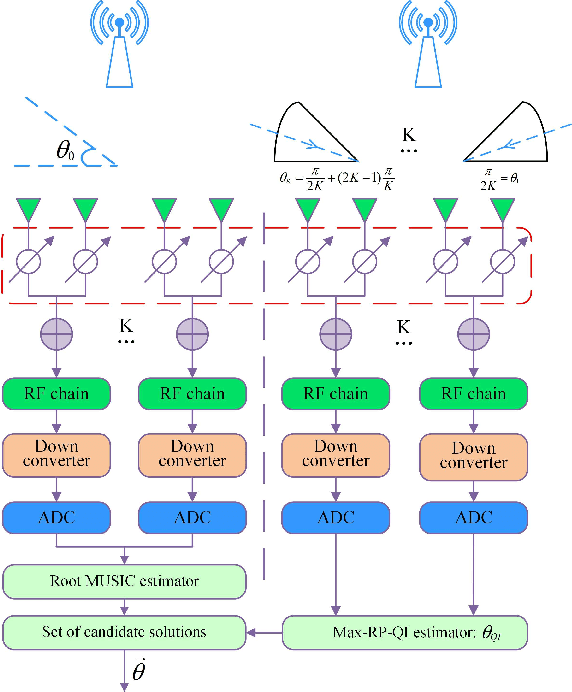
For a sub-connected hybrid multiple-input multiple-output (MIMO) receiver with $K$ subarrays and $N$ antennas, there exists a challenging problem of how to rapidly remove phase ambiguity in only single time-slot. First, a DOA estimator of maximizing received power (Max-RP) is proposed to find the maximum value of $K$-subarray output powers, where each subarray is in charge of one sector, and the center angle of the sector corresponding to the maximum output is the estimated true DOA. To make an enhancement on precision, Max-RP plus quadratic interpolation (Max-RP-QI) method is designed. In the proposed Max-RP-QI, a quadratic interpolation scheme is adopted to interpolate the three DOA values corresponding to the largest three receive powers of Max-RP. Finally, to achieve the CRLB, a Root-MUSIC plus Max-RP-QI scheme is developed. Simulation results show that the proposed three methods eliminate the phase ambiguity during one time-slot and also show low-computational-complexities. In particular, the proposed Root-MUSIC plus Max-RP-QI scheme can reach the CRLB, and the proposed Max-RP and Max-RP-QI are still some performance losses $2dB\thicksim4dB$ compared to the CRLB.