 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Singh": models, code, and papers
Acquiring Linguistic Knowledge from Multimodal Input
Feb 27, 2024
In contrast to children, language models (LMs) exhibit considerably inferior data efficiency when acquiring language. In this submission to the BabyLM Challenge (Warstadt et al., 2023), we test the hypothesis that this data efficiency gap is partly caused by a lack of multimodal input and grounding in the learning environment of typical language models. Although previous work looking into this question found that multimodal training can even harm language-only performance, we speculate that these findings can be attributed to catastrophic forgetting of complex language due to fine-tuning on captions data. To test our hypothesis, we perform an ablation study on FLAVA (Singh et al., 2022), a multimodal vision-and-language model, independently varying the volume of text and vision input to quantify how much text data (if any) can be offset by vision at different data scales. We aim to limit catastrophic forgetting through a multitask pretraining regime that includes unimodal text-only tasks and data sampled from WiT, the relatively diverse Wikipedia-based dataset (Srinivasan et al., 2021). Our results are largely negative: Multimodal pretraining does not harm our models' language performance but does not consistently help either. That said, our conclusions are limited by our having been able to conduct only a small number of runs. While we must leave open the possibility that multimodal input explains some of the gap in data efficiency between LMs and humans, positive evidence for this hypothesis will require better architectures and techniques for multimodal training.
Stability and Multigroup Fairness in Ranking with Uncertain Predictions
Feb 14, 2024Rankings are ubiquitous across many applications, from search engines to hiring committees. In practice, many rankings are derived from the output of predictors. However, when predictors trained for classification tasks have intrinsic uncertainty, it is not obvious how this uncertainty should be represented in the derived rankings. Our work considers ranking functions: maps from individual predictions for a classification task to distributions over rankings. We focus on two aspects of ranking functions: stability to perturbations in predictions and fairness towards both individuals and subgroups. Not only is stability an important requirement for its own sake, but -- as we show -- it composes harmoniously with individual fairness in the sense of Dwork et al. (2012). While deterministic ranking functions cannot be stable aside from trivial scenarios, we show that the recently proposed uncertainty aware (UA) ranking functions of Singh et al. (2021) are stable. Our main result is that UA rankings also achieve multigroup fairness through successful composition with multiaccurate or multicalibrated predictors. Our work demonstrates that UA rankings naturally interpolate between group and individual level fairness guarantees, while simultaneously satisfying stability guarantees important whenever machine-learned predictions are used.
WhisBERT: Multimodal Text-Audio Language Modeling on 100M Words
Dec 07, 2023Training on multiple modalities of input can augment the capabilities of a language model. Here, we ask whether such a training regime can improve the quality and efficiency of these systems as well. We focus on text--audio and introduce Whisbert, which is inspired by the text--image approach of FLAVA (Singh et al., 2022). In accordance with Babylm guidelines (Warstadt et al., 2023), we pretrain Whisbert on a dataset comprising only 100 million words plus their corresponding speech from the word-aligned version of the People's Speech dataset (Galvez et al., 2021). To assess the impact of multimodality, we compare versions of the model that are trained on text only and on both audio and text simultaneously. We find that while Whisbert is able to perform well on multimodal masked modeling and surpasses the Babylm baselines in most benchmark tasks, it struggles to optimize its complex objective and outperform its text-only Whisbert baseline.
Assessing the Effectiveness of GPT-3 in Detecting False Political Statements: A Case Study on the LIAR Dataset
Jun 14, 2023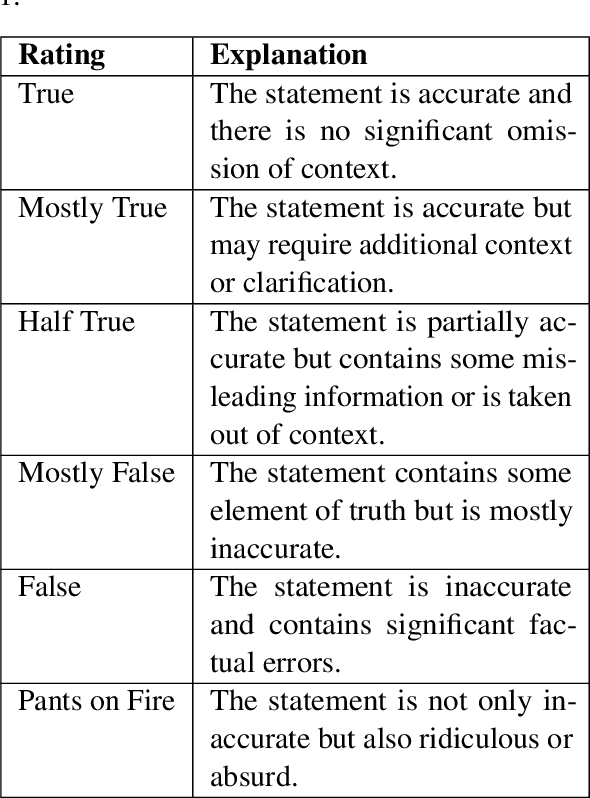


The detection of political fake statements is crucial for maintaining information integrity and preventing the spread of misinformation in society. Historically, state-of-the-art machine learning models employed various methods for detecting deceptive statements. These methods include the use of metadata (W. Wang et al., 2018), n-grams analysis (Singh et al., 2021), and linguistic (Wu et al., 2022) and stylometric (Islam et al., 2020) features. Recent advancements in large language models, such as GPT-3 (Brown et al., 2020) have achieved state-of-the-art performance on a wide range of tasks. In this study, we conducted experiments with GPT-3 on the LIAR dataset (W. Wang et al., 2018) and achieved higher accuracy than state-of-the-art models without using any additional meta or linguistic features. Additionally, we experimented with zero-shot learning using a carefully designed prompt and achieved near state-of-the-art performance. An advantage of this approach is that the model provided evidence for its decision, which adds transparency to the model's decision-making and offers a chance for users to verify the validity of the evidence provided.
A Strong Baseline for Batch Imitation Learning
Feb 06, 2023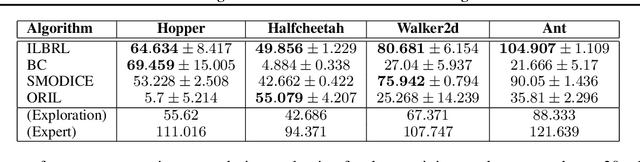
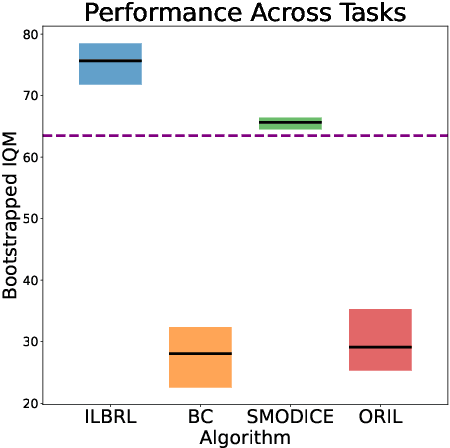
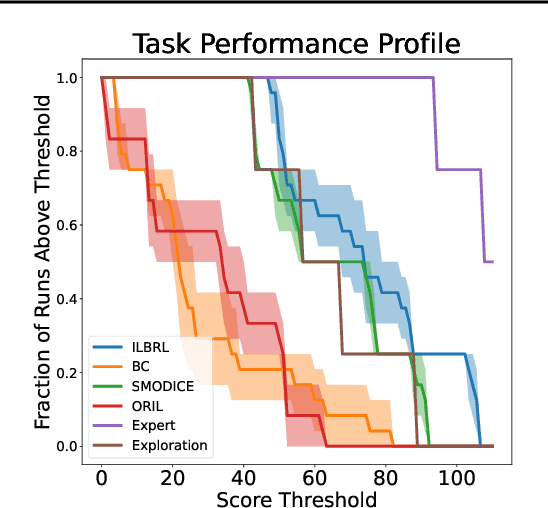

Imitation of expert behaviour is a highly desirable and safe approach to the problem of sequential decision making. We provide an easy-to-implement, novel algorithm for imitation learning under a strict data paradigm, in which the agent must learn solely from data collected a priori. This paradigm allows our algorithm to be used for environments in which safety or cost are of critical concern. Our algorithm requires no additional hyper-parameter tuning beyond any standard batch reinforcement learning (RL) algorithm, making it an ideal baseline for such data-strict regimes. Furthermore, we provide formal sample complexity guarantees for the algorithm in finite Markov Decision Problems. In doing so, we formally demonstrate an unproven claim from Kearns & Singh (1998). On the empirical side, our contribution is twofold. First, we develop a practical, robust and principled evaluation protocol for offline RL methods, making use of only the dataset provided for model selection. This stands in contrast to the vast majority of previous works in offline RL, which tune hyperparameters on the evaluation environment, limiting the practical applicability when deployed in new, cost-critical environments. As such, we establish precedent for the development and fair evaluation of offline RL algorithms. Second, we evaluate our own algorithm on challenging continuous control benchmarks, demonstrating its practical applicability and competitiveness with state-of-the-art performance, despite being a simpler algorithm.
DeepChrome 2.0: Investigating and Improving Architectures, Visualizations, & Experiments
Sep 24, 2022
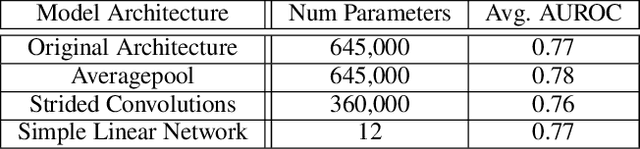
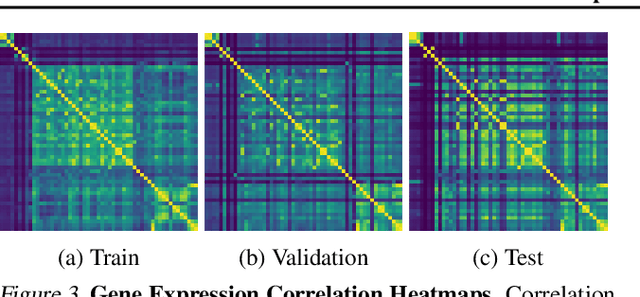
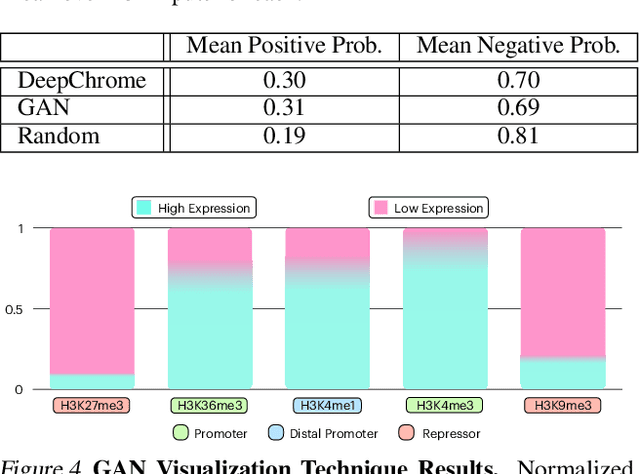
Histone modifications play a critical role in gene regulation. Consequently, predicting gene expression from histone modification signals is a highly motivated problem in epigenetics. We build upon the work of DeepChrome by Singh et al. (2016), who trained classifiers that map histone modification signals to gene expression. We present a novel visualization technique for providing insight into combinatorial relationships among histone modifications for gene regulation that uses a generative adversarial network to generate histone modification signals. We also explore and compare various architectural changes, with results suggesting that the 645k-parameter convolutional neural network from DeepChrome has the same predictive power as a 12-parameter linear network. Results from cross-cell prediction experiments, where the model is trained and tested on datasets of varying sizes, cell-types, and correlations, suggest the relationship between histone modification signals and gene expression is independent of cell type. We release our PyTorch re-implementation of DeepChrome on GitHub \footnote{\url{github.com/ssss1029/gene_expression_294}}.\parfillskip=0pt
Gradient Descent and the Power Method: Exploiting their connection to find the leftmost eigen-pair and escape saddle points
Nov 02, 2022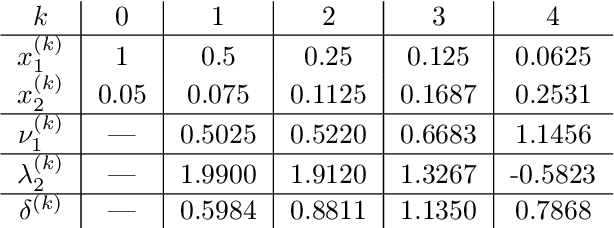
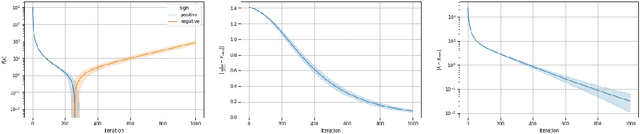
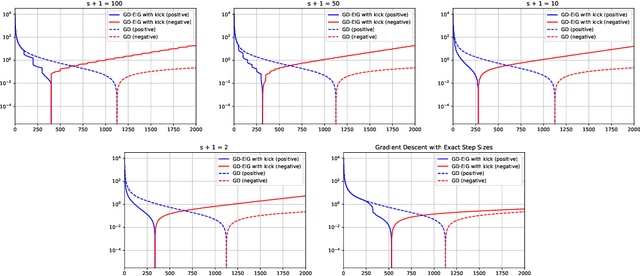
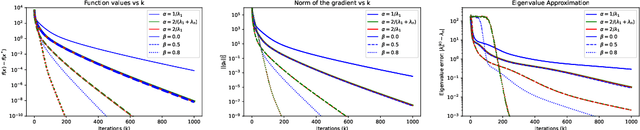
This work shows that applying Gradient Descent (GD) with a fixed step size to minimize a (possibly nonconvex) quadratic function is equivalent to running the Power Method (PM) on the gradients. The connection between GD with a fixed step size and the PM, both with and without fixed momentum, is thus established. Consequently, valuable eigen-information is available via GD. Recent examples show that GD with a fixed step size, applied to locally quadratic nonconvex functions, can take exponential time to escape saddle points (Simon S. Du, Chi Jin, Jason D. Lee, Michael I. Jordan, Aarti Singh, and Barnabas Poczos: "Gradient descent can take exponential time to escape saddle points"; S. Paternain, A. Mokhtari, and A. Ribeiro: "A newton-based method for nonconvex optimization with fast evasion of saddle points"). Here, those examples are revisited and it is shown that eigenvalue information was missing, so that the examples may not provide a complete picture of the potential practical behaviour of GD. Thus, ongoing investigation of the behaviour of GD on nonconvex functions, possibly with an \emph{adaptive} or \emph{variable} step size, is warranted. It is shown that, in the special case of a quadratic in $R^2$, if an eigenvalue is known, then GD with a fixed step size will converge in two iterations, and a complete eigen-decomposition is available. By considering the dynamics of the gradients and iterates, new step size strategies are proposed to improve the practical performance of GD. Several numerical examples are presented, which demonstrate the advantages of exploiting the GD--PM connection.
Reward is not enough: can we liberate AI from the reinforcement learning paradigm?
Feb 08, 2022
I present arguments against the hypothesis put forward by Silver, Singh, Precup, and Sutton ( https://www.sciencedirect.com/science/article/pii/S0004370221000862 ) : reward maximization is not enough to explain many activities associated with natural and artificial intelligence including knowledge, learning, perception, social intelligence, evolution, language, generalisation and imitation. I show such reductio ad lucrum has its intellectual origins in the political economy of Homo economicus and substantially overlaps with the radical version of behaviourism. I show why the reinforcement learning paradigm, despite its demonstrable usefulness in some practical application, is an incomplete framework for intelligence -- natural and artificial. Complexities of intelligent behaviour are not simply second-order complications on top of reward maximisation. This fact has profound implications for the development of practically usable, smart, safe and robust artificially intelligent agents.
Learning Infinite-Horizon Average-Reward Markov Decision Processes with Constraints
Jan 31, 2022We study regret minimization for infinite-horizon average-reward Markov Decision Processes (MDPs) under cost constraints. We start by designing a policy optimization algorithm with carefully designed action-value estimator and bonus term, and show that for ergodic MDPs, our algorithm ensures $\widetilde{O}(\sqrt{T})$ regret and constant constraint violation, where $T$ is the total number of time steps. This strictly improves over the algorithm of (Singh et al., 2020), whose regret and constraint violation are both $\widetilde{O}(T^{2/3})$. Next, we consider the most general class of weakly communicating MDPs. Through a finite-horizon approximation, we develop another algorithm with $\widetilde{O}(T^{2/3})$ regret and constraint violation, which can be further improved to $\widetilde{O}(\sqrt{T})$ via a simple modification, albeit making the algorithm computationally inefficient. As far as we know, these are the first set of provable algorithms for weakly communicating MDPs with cost constraints.
Flexible Option Learning
Dec 06, 2021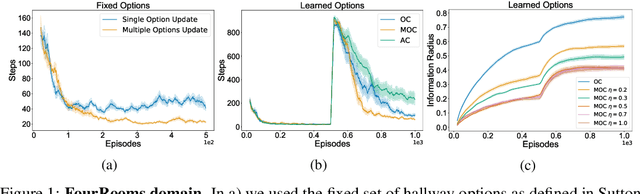
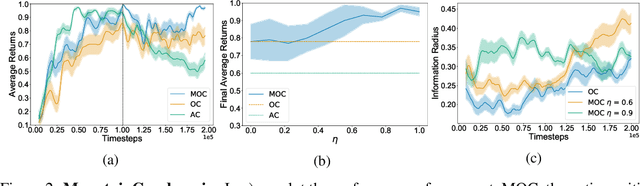

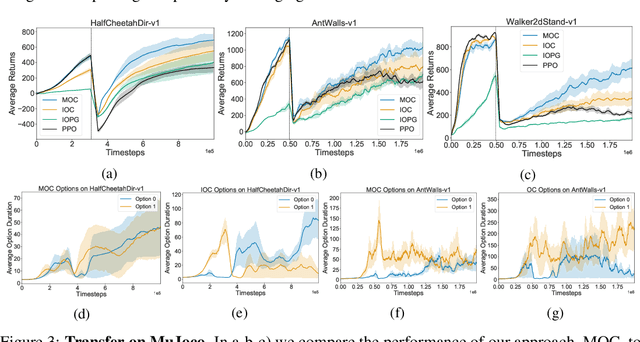
Temporal abstraction in reinforcement learning (RL), offers the promise of improving generalization and knowledge transfer in complex environments, by propagating information more efficiently over time. Although option learning was initially formulated in a way that allows updating many options simultaneously, using off-policy, intra-option learning (Sutton, Precup & Singh, 1999), many of the recent hierarchical reinforcement learning approaches only update a single option at a time: the option currently executing. We revisit and extend intra-option learning in the context of deep reinforcement learning, in order to enable updating all options consistent with current primitive action choices, without introducing any additional estimates. Our method can therefore be naturally adopted in most hierarchical RL frameworks. When we combine our approach with the option-critic algorithm for option discovery, we obtain significant improvements in performance and data-efficiency across a wide variety of domains.