 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Wen": models, code, and papers
Discrete Choice Multi-Armed Bandits
Oct 01, 2023
This paper establishes a connection between a category of discrete choice models and the realms of online learning and multiarmed bandit algorithms. Our contributions can be summarized in two key aspects. Firstly, we furnish sublinear regret bounds for a comprehensive family of algorithms, encompassing the Exp3 algorithm as a particular case. Secondly, we introduce a novel family of adversarial multiarmed bandit algorithms, drawing inspiration from the generalized nested logit models initially introduced by \citet{wen:2001}. These algorithms offer users the flexibility to fine-tune the model extensively, as they can be implemented efficiently due to their closed-form sampling distribution probabilities. To demonstrate the practical implementation of our algorithms, we present numerical experiments, focusing on the stochastic bandit case.
WYWEB: A NLP Evaluation Benchmark For Classical Chinese
May 23, 2023
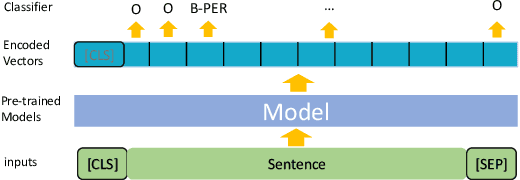
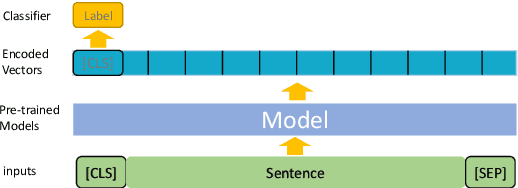
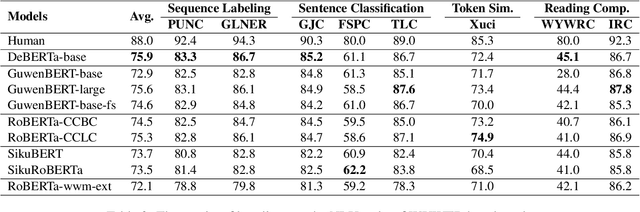
To fully evaluate the overall performance of different NLP models in a given domain, many evaluation benchmarks are proposed, such as GLUE, SuperGLUE and CLUE. The fi eld of natural language understanding has traditionally focused on benchmarks for various tasks in languages such as Chinese, English, and multilingua, however, there has been a lack of attention given to the area of classical Chinese, also known as "wen yan wen", which has a rich history spanning thousands of years and holds signifi cant cultural and academic value. For the prosperity of the NLP community, in this paper, we introduce the WYWEB evaluation benchmark, which consists of nine NLP tasks in classical Chinese, implementing sentence classifi cation, sequence labeling, reading comprehension, and machine translation. We evaluate the existing pre-trained language models, which are all struggling with this benchmark. We also introduce a number of supplementary datasets and additional tools to help facilitate further progress on classical Chinese NLU. The github repository is https://github.com/baudzhou/WYWEB.
Exact identification of nonlinear dynamical systems by Trimmed Lasso
Aug 03, 2023Identification of nonlinear dynamical systems has been popularized by sparse identification of the nonlinear dynamics (SINDy) via the sequentially thresholded least squares (STLS) algorithm. Many extensions SINDy have emerged in the literature to deal with experimental data which are finite in length and noisy. Recently, the computationally intensive method of ensembling bootstrapped SINDy models (E-SINDy) was proposed for model identification, handling finite, highly noisy data. While the extensions of SINDy are numerous, their sparsity-promoting estimators occasionally provide sparse approximations of the dynamics as opposed to exact recovery. Furthermore, these estimators suffer under multicollinearity, e.g. the irrepresentable condition for the Lasso. In this paper, we demonstrate that the Trimmed Lasso for robust identification of models (TRIM) can provide exact recovery under more severe noise, finite data, and multicollinearity as opposed to E-SINDy. Additionally, the computational cost of TRIM is asymptotically equal to STLS since the sparsity parameter of the TRIM can be solved efficiently by convex solvers. We compare these methodologies on challenging nonlinear systems, specifically the Lorenz 63 system, the Bouc Wen oscillator from the nonlinear dynamics benchmark of No\"el and Schoukens, 2016, and a time delay system describing tool cutting dynamics. This study emphasizes the comparisons between STLS, reweighted $\ell_1$ minimization, and Trimmed Lasso in identification with respect to problems faced by practitioners: the problem of finite and noisy data, the performance of the sparse regression of when the library grows in dimension (multicollinearity), and automatic methods for choice of regularization parameters.
Shuo Wen Jie Zi: Rethinking Dictionaries and Glyphs for Chinese Language Pre-training
May 30, 2023
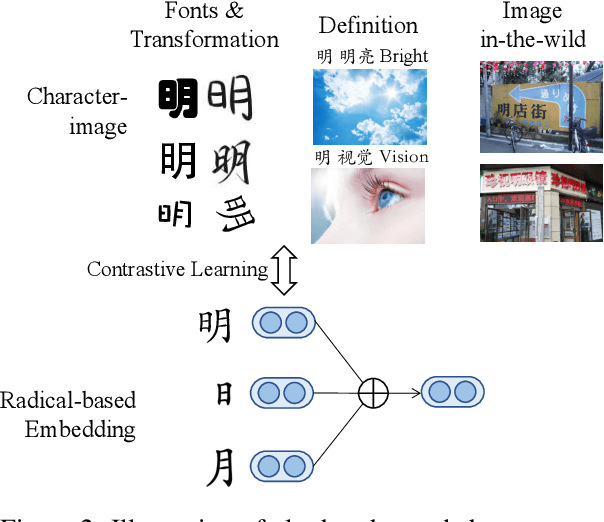
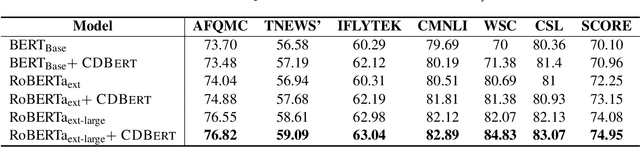
We introduce CDBERT, a new learning paradigm that enhances the semantics understanding ability of the Chinese PLMs with dictionary knowledge and structure of Chinese characters. We name the two core modules of CDBERT as Shuowen and Jiezi, where Shuowen refers to the process of retrieving the most appropriate meaning from Chinese dictionaries and Jiezi refers to the process of enhancing characters' glyph representations with structure understanding. To facilitate dictionary understanding, we propose three pre-training tasks, i.e., Masked Entry Modeling, Contrastive Learning for Synonym and Antonym, and Example Learning. We evaluate our method on both modern Chinese understanding benchmark CLUE and ancient Chinese benchmark CCLUE. Moreover, we propose a new polysemy discrimination task PolyMRC based on the collected dictionary of ancient Chinese. Our paradigm demonstrates consistent improvements on previous Chinese PLMs across all tasks. Moreover, our approach yields significant boosting on few-shot setting of ancient Chinese understanding.
Adversarial Auto-Augment with Label Preservation: A Representation Learning Principle Guided Approach
Nov 02, 2022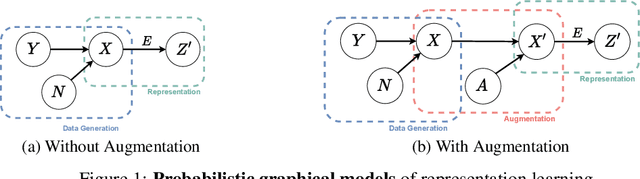

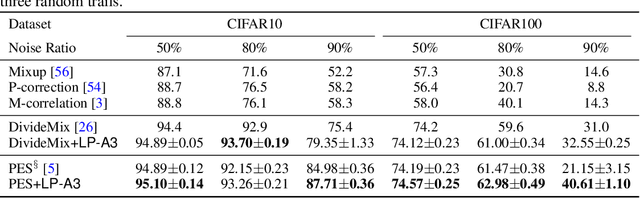

Data augmentation is a critical contributing factor to the success of deep learning but heavily relies on prior domain knowledge which is not always available. Recent works on automatic data augmentation learn a policy to form a sequence of augmentation operations, which are still pre-defined and restricted to limited options. In this paper, we show that a prior-free autonomous data augmentation's objective can be derived from a representation learning principle that aims to preserve the minimum sufficient information of the labels. Given an example, the objective aims at creating a distant "hard positive example" as the augmentation, while still preserving the original label. We then propose a practical surrogate to the objective that can be optimized efficiently and integrated seamlessly into existing methods for a broad class of machine learning tasks, e.g., supervised, semi-supervised, and noisy-label learning. Unlike previous works, our method does not require training an extra generative model but instead leverages the intermediate layer representations of the end-task model for generating data augmentations. In experiments, we show that our method consistently brings non-trivial improvements to the three aforementioned learning tasks from both efficiency and final performance, either or not combined with strong pre-defined augmentations, e.g., on medical images when domain knowledge is unavailable and the existing augmentation techniques perform poorly. Code is available at: https://github.com/kai-wen-yang/LPA3}{https://github.com/kai-wen-yang/LPA3.
A Fractional-Order Normalized Bouc-Wen Model for Piezoelectric Hysteresis Nonlinearity
Mar 10, 2020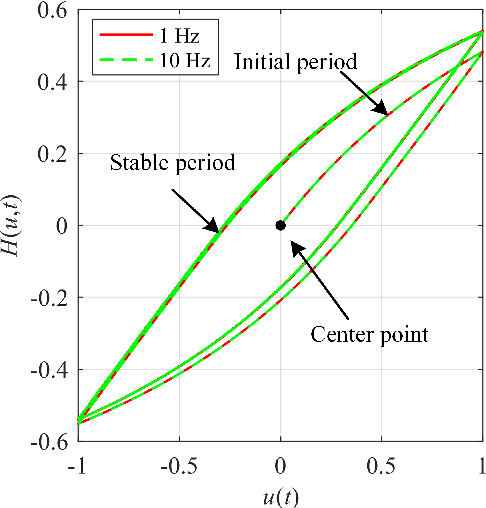
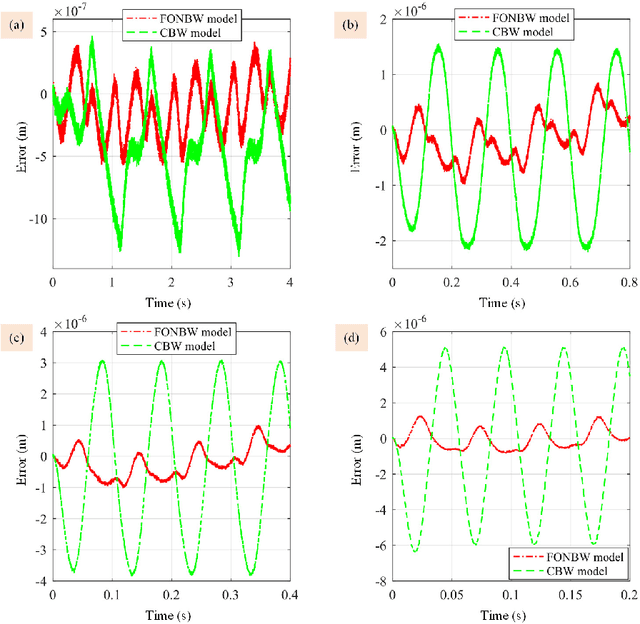
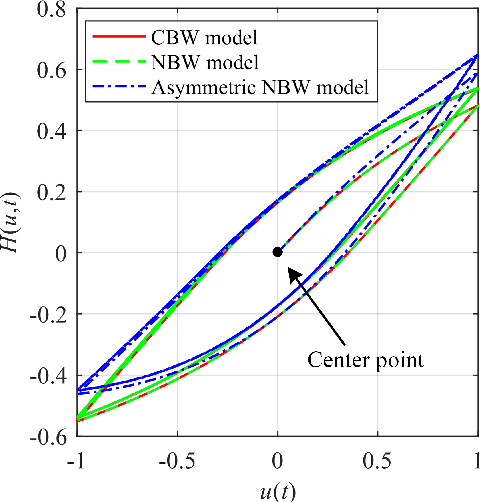
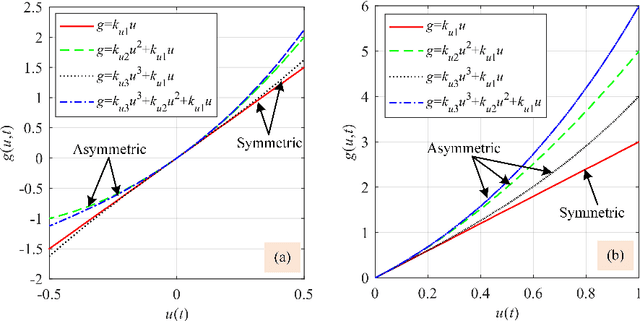
This paper presents a new fractional-order normalized Bouc-Wen (BW) (FONBW) model to describe the asymmetric and rate-dependent hysteresis nonlinearity of piezoelectric actuators (PEAs). In view of the fact that the classical BW (CBW) model is only efficient for the symmetric and rate-independent hysteresis description, the FONBW model is devoted to characterizing the asymmetric and rate-dependent behaviors of the hysteresis in PEAs by adopting a generalized input function and two fractional operators, respectively. Different from the traditional modified BW models, the proposed FONBW model also eliminates the redundancy of parameters in the CBW model via the normalization processing. By this way, the developed FONBW model has a relative simple mathematic expression with fewer parameters to simultaneously characterize the asymmetric and rate-dependent hysteresis behaviors of PEAs. Model parameters are identified by the self-adaptive differential evolution algorithm. To validate the effectiveness of the proposed model, a series of experimental studies are carried out on a PEA system. Results show that the proposed model is superior to the CBW model in accuracy.
Marginal and Joint Cross-Entropies & Predictives for Online Bayesian Inference, Active Learning, and Active Sampling
May 18, 2022
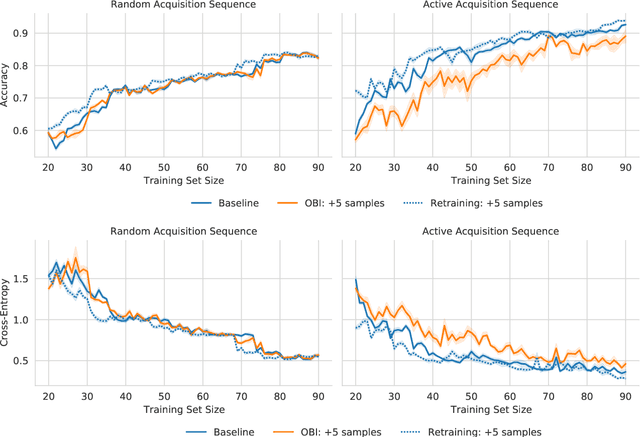
Principled Bayesian deep learning (BDL) does not live up to its potential when we only focus on marginal predictive distributions (marginal predictives). Recent works have highlighted the importance of joint predictives for (Bayesian) sequential decision making from a theoretical and synthetic perspective. We provide additional practical arguments grounded in real-world applications for focusing on joint predictives: we discuss online Bayesian inference, which would allow us to make predictions while taking into account additional data without retraining, and we propose new challenging evaluation settings using active learning and active sampling. These settings are motivated by an examination of marginal and joint predictives, their respective cross-entropies, and their place in offline and online learning. They are more realistic than previously suggested ones, building on work by Wen et al. (2021) and Osband et al. (2022), and focus on evaluating the performance of approximate BNNs in an online supervised setting. Initial experiments, however, raise questions on the feasibility of these ideas in high-dimensional parameter spaces with current BDL inference techniques, and we suggest experiments that might help shed further light on the practicality of current research for these problems. Importantly, our work highlights previously unidentified gaps in current research and the need for better approximate joint predictives.
Sequential adaptive elastic net approach for single-snapshot source localization
May 19, 2018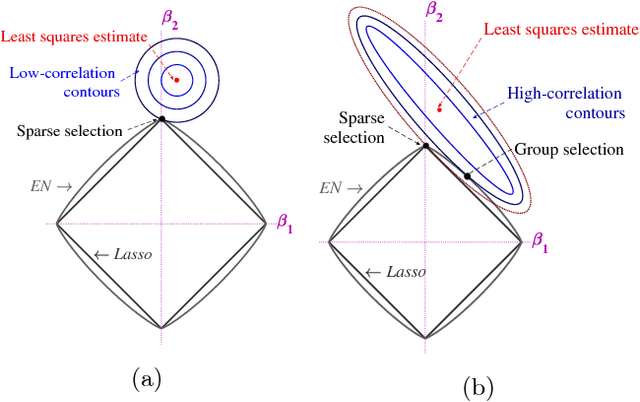
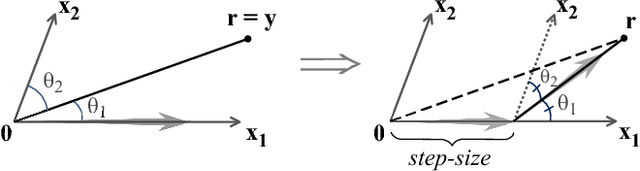
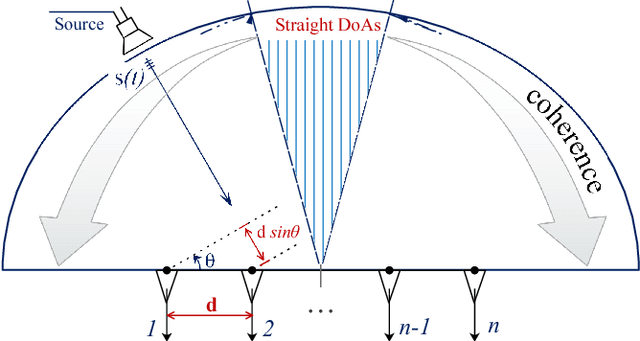
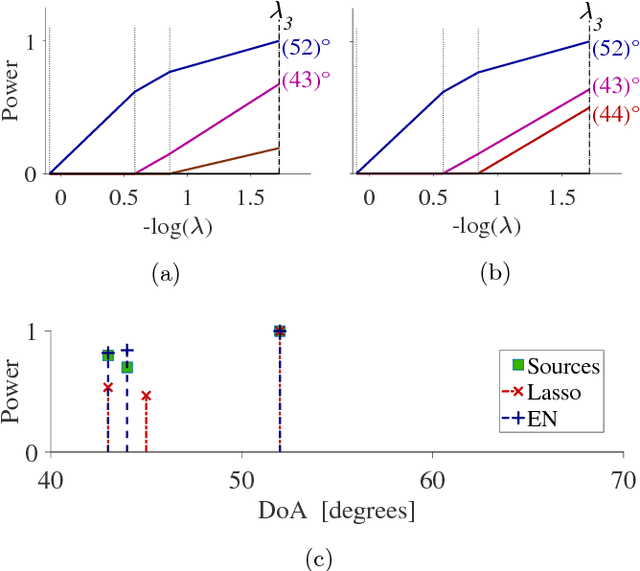
This paper proposes efficient algorithms for accurate recovery of direction-of-arrival (DoA) of sources from single-snapshot measurements using compressed beamforming (CBF). In CBF, the conventional sensor array signal model is cast as an underdetermined complex-valued linear regression model and sparse signal recovery methods are used for solving the DoA finding problem. We develop a complex-valued pathwise weighted elastic net (c-PW-WEN) algorithm that finds solutions at knots of penalty parameter values over a path (or grid) of EN tuning parameter values. c-PW-WEN also computes Lasso or weighted Lasso in its path. We then propose a sequential adaptive EN (SAEN) method that is based on c-PW-WEN algorithm with adaptive weights that depend on the previous solution. Extensive simulation studies illustrate that SAEN improves the probability of exact recovery of true support compared to conventional sparse signal recovery approaches such as Lasso, elastic net or orthogonal matching pursuit in several challenging multiple target scenarios. The effectiveness of SAEN is more pronounced in the presence of high mutual coherence.
Agnostic Q-learning with Function Approximation in Deterministic Systems: Tight Bounds on Approximation Error and Sample Complexity
Feb 17, 2020The current paper studies the problem of agnostic $Q$-learning with function approximation in deterministic systems where the optimal $Q$-function is approximable by a function in the class $\mathcal{F}$ with approximation error $\delta \ge 0$. We propose a novel recursion-based algorithm and show that if $\delta = O\left(\rho/\sqrt{\dim_E}\right)$, then one can find the optimal policy using $O\left(\dim_E\right)$ trajectories, where $\rho$ is the gap between the optimal $Q$-value of the best actions and that of the second-best actions and $\dim_E$ is the Eluder dimension of $\mathcal{F}$. Our result has two implications: 1) In conjunction with the lower bound in [Du et al., ICLR 2020], our upper bound suggests that the condition $\delta = \widetilde{\Theta}\left(\rho/\sqrt{\mathrm{dim}_E}\right)$ is necessary and sufficient for algorithms with polynomial sample complexity. 2) In conjunction with the lower bound in [Wen and Van Roy, NIPS 2013], our upper bound suggests that the sample complexity $\widetilde{\Theta}\left(\mathrm{dim}_E\right)$ is tight even in the agnostic setting. Therefore, we settle the open problem on agnostic $Q$-learning proposed in [Wen and Van Roy, NIPS 2013]. We further extend our algorithm to the stochastic reward setting and obtain similar results.
Dynamic Control of Pneumatic Muscle Actuators
Nov 12, 2018
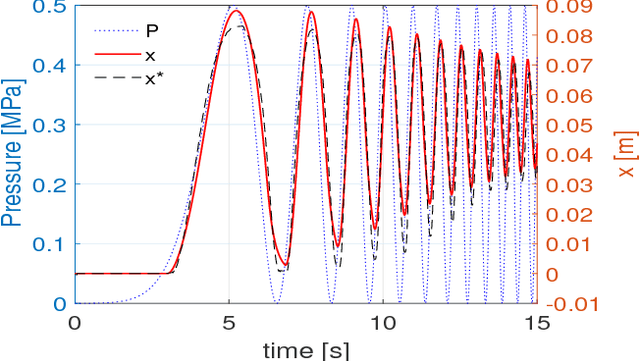
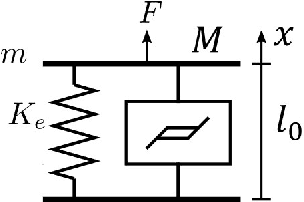
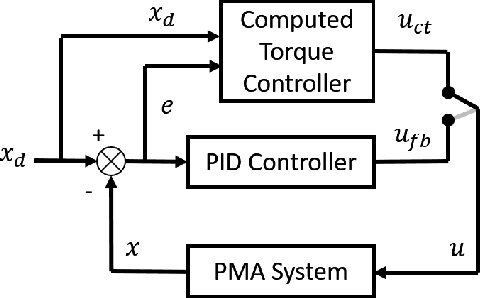
Pneumatic muscle actuators (PMA) are easy-to-fabricate, lightweight, compliant, and have high power-to-weight ratio, thus making them the ideal actuation choice for many soft and continuum robots. But so far, limited work has been carried out in dynamic control of PMAs. One reason is that PMAs are highly hysteretic. Coupled with their high compliance and response lag, PMAs are challenging to control, particularly when subjected to external loads. The hysteresis models proposed to-date rely on many physical and mechanical parameters that are difficult to measure reliably and therefore of limited use for implementing dynamic control. In this work, we employ a Bouc-Wen hysteresis modeling approach to account for the hysteresis of PMAs and use the model for implementing dynamic control. The controller is then compared to PID feedback control for a number of dynamic position tracking tests. The dynamic control based on the Bouc-Wen hysteresis model shows significantly better tracking performance. This work lays the foundation towards implementing dynamic control for PMA-powered high degrees of freedom soft and continuum robots.