 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Ye": models, code, and papers
ToolSword: Unveiling Safety Issues of Large Language Models in Tool Learning Across Three Stages
Feb 16, 2024
Tool learning is widely acknowledged as a foundational approach or deploying large language models (LLMs) in real-world scenarios. While current research primarily emphasizes leveraging tools to augment LLMs, it frequently neglects emerging safety considerations tied to their application. To fill this gap, we present $ToolSword$, a comprehensive framework dedicated to meticulously investigating safety issues linked to LLMs in tool learning. Specifically, ToolSword delineates six safety scenarios for LLMs in tool learning, encompassing $malicious$ $queries$ and $jailbreak$ $attacks$ in the input stage, $noisy$ $misdirection$ and $risky$ $cues$ in the execution stage, and $harmful$ $feedback$ and $error$ $conflicts$ in the output stage. Experiments conducted on 11 open-source and closed-source LLMs reveal enduring safety challenges in tool learning, such as handling harmful queries, employing risky tools, and delivering detrimental feedback, which even GPT-4 is susceptible to. Moreover, we conduct further studies with the aim of fostering research on tool learning safety. The data is released in https://github.com/Junjie-Ye/ToolSword.
OpenFedLLM: Training Large Language Models on Decentralized Private Data via Federated Learning
Feb 10, 2024Trained on massive publicly available data, large language models (LLMs) have demonstrated tremendous success across various fields. While more data contributes to better performance, a disconcerting reality is that high-quality public data will be exhausted in a few years. In this paper, we offer a potential next step for contemporary LLMs: collaborative and privacy-preserving LLM training on the underutilized distributed private data via federated learning (FL), where multiple data owners collaboratively train a shared model without transmitting raw data. To achieve this, we build a concise, integrated, and research-friendly framework/codebase, named OpenFedLLM. It covers federated instruction tuning for enhancing instruction-following capability, federated value alignment for aligning with human values, and 7 representative FL algorithms. Besides, OpenFedLLM supports training on diverse domains, where we cover 8 training datasets; and provides comprehensive evaluations, where we cover 30+ evaluation metrics. Through extensive experiments, we observe that all FL algorithms outperform local training on training LLMs, demonstrating a clear performance improvement across a variety of settings. Notably, in a financial benchmark, Llama2-7B fine-tuned by applying any FL algorithm can outperform GPT-4 by a significant margin while the model obtained through individual training cannot, demonstrating strong motivation for clients to participate in FL. The code is available at https://github.com/rui-ye/OpenFedLLM.
RoTBench: A Multi-Level Benchmark for Evaluating the Robustness of Large Language Models in Tool Learning
Jan 19, 2024Tool learning has generated widespread interest as a vital means of interaction between Large Language Models (LLMs) and the physical world. Current research predominantly emphasizes LLMs' capacity to utilize tools in well-structured environments while overlooking their stability when confronted with the inevitable noise of the real world. To bridge this gap, we introduce RoTBench, a multi-level benchmark for evaluating the robustness of LLMs in tool learning. Specifically, we establish five external environments, each featuring varying levels of noise (i.e., Clean, Slight, Medium, Heavy, and Union), providing an in-depth analysis of the model's resilience across three critical phases: tool selection, parameter identification, and content filling. Experiments involving six widely-used models underscore the urgent necessity for enhancing the robustness of LLMs in tool learning. For instance, the performance of GPT-4 even drops significantly from 80.00 to 58.10 when there is no substantial change in manual accuracy. More surprisingly, the noise correction capability inherent in the GPT family paradoxically impedes its adaptability in the face of mild noise. In light of these findings, we propose RoTTuning, a strategy that enriches the diversity of training environments to bolster the robustness of LLMs in tool learning. The code and data are available at https://github.com/Junjie-Ye/RoTBench.
ToolEyes: Fine-Grained Evaluation for Tool Learning Capabilities of Large Language Models in Real-world Scenarios
Jan 14, 2024Existing evaluations of tool learning primarily focus on validating the alignment of selected tools for large language models (LLMs) with expected outcomes. However, these approaches rely on a limited set of scenarios where answers can be pre-determined, diverging from genuine needs. Furthermore, a sole emphasis on outcomes disregards the intricate capabilities essential for LLMs to effectively utilize tools. To tackle this issue, we propose ToolEyes, a fine-grained system tailored for the evaluation of the LLMs' tool learning capabilities in authentic scenarios. The system meticulously examines seven real-world scenarios, analyzing five dimensions crucial to LLMs in tool learning: format alignment, intent comprehension, behavior planning, tool selection, and answer organization. Additionally, ToolEyes incorporates a tool library boasting approximately 600 tools, serving as an intermediary between LLMs and the physical world. Evaluations involving ten LLMs across three categories reveal a preference for specific scenarios and limited cognitive abilities in tool learning. Intriguingly, expanding the model size even exacerbates the hindrance to tool learning. These findings offer instructive insights aimed at advancing the field of tool learning. The data is available att https://github.com/Junjie-Ye/ToolEyes.
RethinkingTMSC: An Empirical Study for Target-Oriented Multimodal Sentiment Classification
Oct 14, 2023
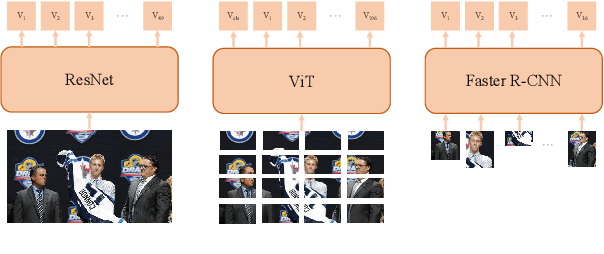
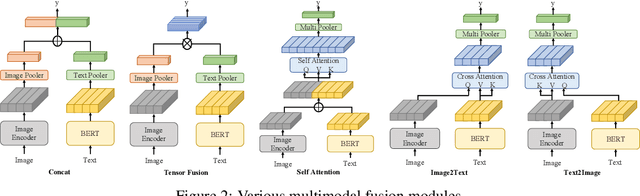
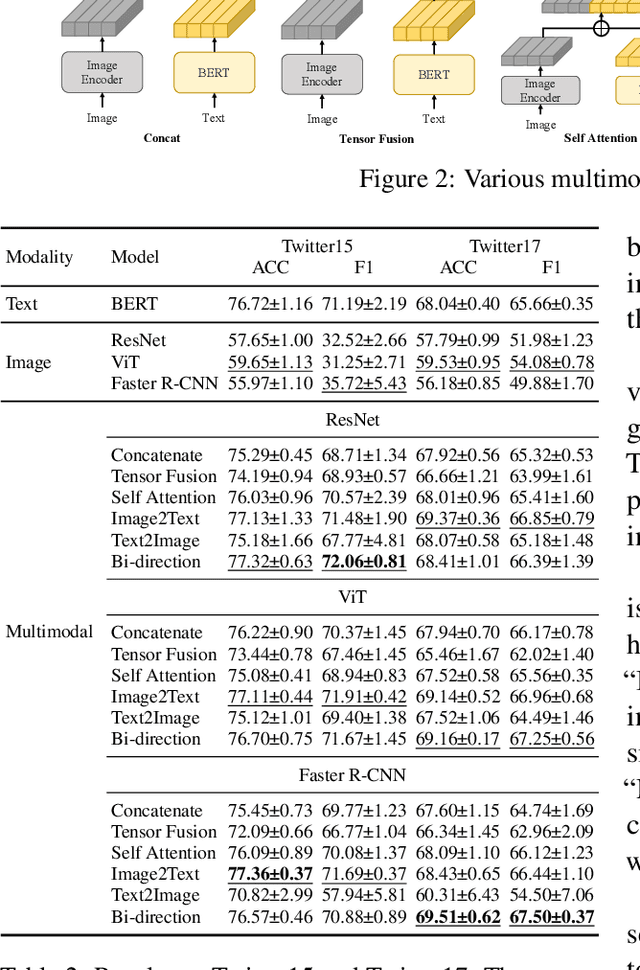
Recently, Target-oriented Multimodal Sentiment Classification (TMSC) has gained significant attention among scholars. However, current multimodal models have reached a performance bottleneck. To investigate the causes of this problem, we perform extensive empirical evaluation and in-depth analysis of the datasets to answer the following questions: Q1: Are the modalities equally important for TMSC? Q2: Which multimodal fusion modules are more effective? Q3: Do existing datasets adequately support the research? Our experiments and analyses reveal that the current TMSC systems primarily rely on the textual modality, as most of targets' sentiments can be determined solely by text. Consequently, we point out several directions to work on for the TMSC task in terms of model design and dataset construction. The code and data can be found in https://github.com/Junjie-Ye/RethinkingTMSC.
Emo-DNA: Emotion Decoupling and Alignment Learning for Cross-Corpus Speech Emotion Recognition
Aug 04, 2023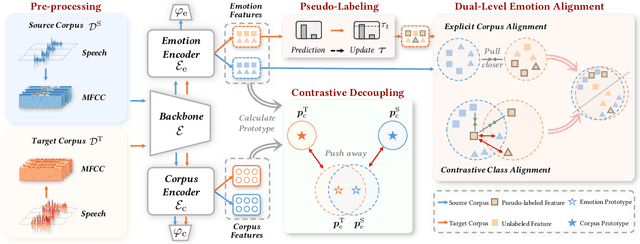
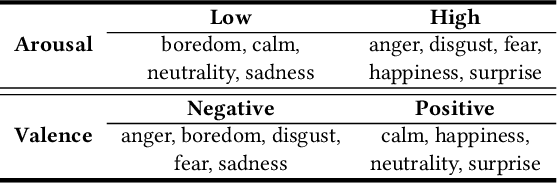
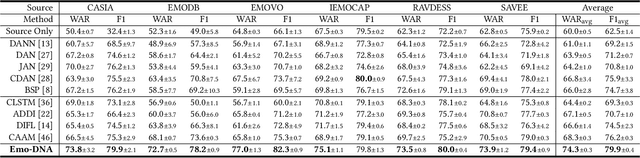
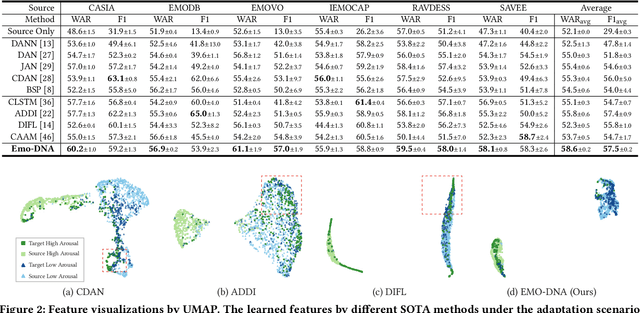
Cross-corpus speech emotion recognition (SER) seeks to generalize the ability of inferring speech emotion from a well-labeled corpus to an unlabeled one, which is a rather challenging task due to the significant discrepancy between two corpora. Existing methods, typically based on unsupervised domain adaptation (UDA), struggle to learn corpus-invariant features by global distribution alignment, but unfortunately, the resulting features are mixed with corpus-specific features or not class-discriminative. To tackle these challenges, we propose a novel Emotion Decoupling aNd Alignment learning framework (EMO-DNA) for cross-corpus SER, a novel UDA method to learn emotion-relevant corpus-invariant features. The novelties of EMO-DNA are two-fold: contrastive emotion decoupling and dual-level emotion alignment. On one hand, our contrastive emotion decoupling achieves decoupling learning via a contrastive decoupling loss to strengthen the separability of emotion-relevant features from corpus-specific ones. On the other hand, our dual-level emotion alignment introduces an adaptive threshold pseudo-labeling to select confident target samples for class-level alignment, and performs corpus-level alignment to jointly guide model for learning class-discriminative corpus-invariant features across corpora. Extensive experimental results demonstrate the superior performance of EMO-DNA over the state-of-the-art methods in several cross-corpus scenarios. Source code is available at https://github.com/Jiaxin-Ye/Emo-DNA.
A Nearly-Linear Time Algorithm for Structured Support Vector Machines
Jul 15, 2023Quadratic programming is a fundamental problem in the field of convex optimization. Many practical tasks can be formulated as quadratic programming, for example, the support vector machine (SVM). Linear SVM is one of the most popular tools over the last three decades in machine learning before deep learning method dominating. In general, a quadratic program has input size $\Theta(n^2)$ (where $n$ is the number of variables), thus takes $\Omega(n^2)$ time to solve. Nevertheless, quadratic programs coming from SVMs has input size $O(n)$, allowing the possibility of designing nearly-linear time algorithms. Two important classes of SVMs are programs admitting low-rank kernel factorizations and low-treewidth programs. Low-treewidth convex optimization has gained increasing interest in the past few years (e.g.~linear programming [Dong, Lee and Ye 2021] and semidefinite programming [Gu and Song 2022]). Therefore, an important open question is whether there exist nearly-linear time algorithms for quadratic programs with these nice structures. In this work, we provide the first nearly-linear time algorithm for solving quadratic programming with low-rank factorization or low-treewidth, and a small number of linear constraints. Our results imply nearly-linear time algorithms for low-treewidth or low-rank SVMs.
Neural Multigrid Memory For Computational Fluid Dynamics
Jun 24, 2023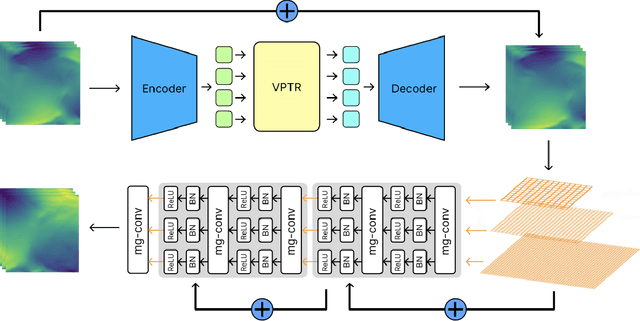
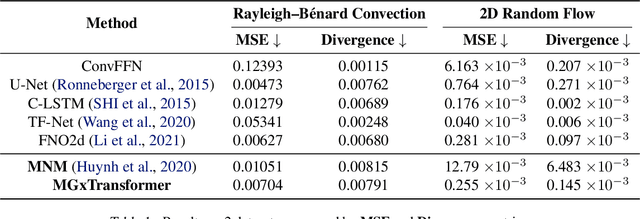
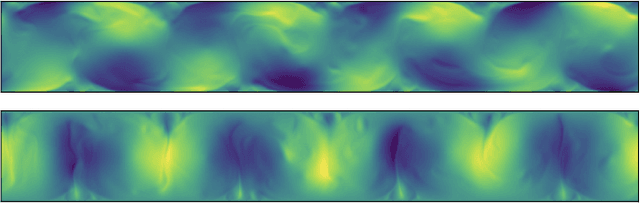
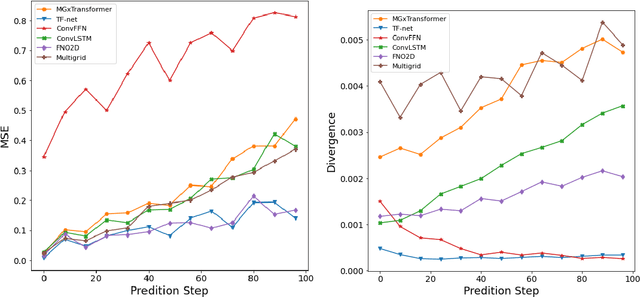
Turbulent flow simulation plays a crucial role in various applications, including aircraft and ship design, industrial process optimization, and weather prediction. In this paper, we propose an advanced data-driven method for simulating turbulent flow, representing a significant improvement over existing approaches. Our methodology combines the strengths of Video Prediction Transformer (VPTR) (Ye & Bilodeau, 2022) and Multigrid Architecture (MgConv, MgResnet) (Ke et al., 2017). VPTR excels in capturing complex spatiotemporal dependencies and handling large input data, making it a promising choice for turbulent flow prediction. Meanwhile, Multigrid Architecture utilizes multiple grids with different resolutions to capture the multiscale nature of turbulent flows, resulting in more accurate and efficient simulations. Through our experiments, we demonstrate the effectiveness of our proposed approach, named MGxTransformer, in accurately predicting velocity, temperature, and turbulence intensity for incompressible turbulent flows across various geometries and flow conditions. Our results exhibit superior accuracy compared to other baselines, while maintaining computational efficiency. Our implementation in PyTorch is available publicly at https://github.com/Combi2k2/MG-Turbulent-Flow