 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Yi": models, code, and papers
Yi: Open Foundation Models by 01.AI
Mar 07, 2024
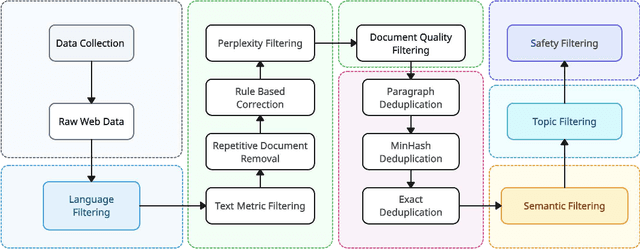

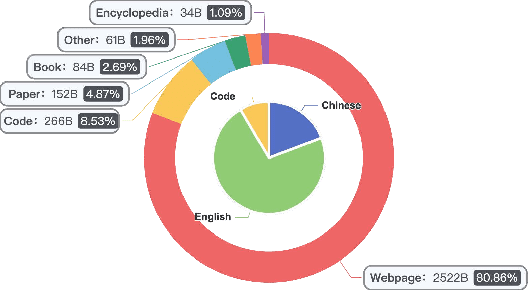
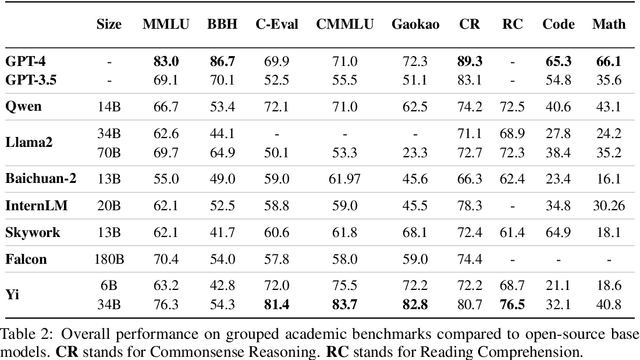
We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
RULER: What's the Real Context Size of Your Long-Context Language Models?
Apr 11, 2024The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the "needle") from long distractor texts (the "haystack"), has been widely adopted to evaluate long-context language models (LMs). However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate ten long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, all models exhibit large performance drops as the context length increases. While these models all claim context sizes of 32K tokens or greater, only four models (GPT-4, Command-R, Yi-34B, and Mixtral) can maintain satisfactory performance at the length of 32K. Our analysis of Yi-34B, which supports context length of 200K, reveals large room for improvement as we increase input length and task complexity. We open source RULER to spur comprehensive evaluation of long-context LMs.
Can LLMs substitute SQL? Comparing Resource Utilization of Querying LLMs versus Traditional Relational Databases
Apr 12, 2024Large Language Models (LLMs) can automate or substitute different types of tasks in the software engineering process. This study evaluates the resource utilization and accuracy of LLM in interpreting and executing natural language queries against traditional SQL within relational database management systems. We empirically examine the resource utilization and accuracy of nine LLMs varying from 7 to 34 Billion parameters, including Llama2 7B, Llama2 13B, Mistral, Mixtral, Optimus-7B, SUS-chat-34B, platypus-yi-34b, NeuralHermes-2.5-Mistral-7B and Starling-LM-7B-alpha, using a small transaction dataset. Our findings indicate that using LLMs for database queries incurs significant energy overhead (even small and quantized models), making it an environmentally unfriendly approach. Therefore, we advise against replacing relational databases with LLMs due to their substantial resource utilization.
High-Dimension Human Value Representation in Large Language Models
Apr 11, 2024The widespread application of Large Language Models (LLMs) across various tasks and fields has necessitated the alignment of these models with human values and preferences. Given various approaches of human value alignment, ranging from Reinforcement Learning with Human Feedback (RLHF), to constitutional learning, etc. there is an urgent need to understand the scope and nature of human values injected into these models before their release. There is also a need for model alignment without a costly large scale human annotation effort. We propose UniVaR, a high-dimensional representation of human value distributions in LLMs, orthogonal to model architecture and training data. Trained from the value-relevant output of eight multilingual LLMs and tested on the output from four multilingual LLMs, namely LlaMA2, ChatGPT, JAIS and Yi, we show that UniVaR is a powerful tool to compare the distribution of human values embedded in different LLMs with different langauge sources. Through UniVaR, we explore how different LLMs prioritize various values in different languages and cultures, shedding light on the complex interplay between human values and language modeling.
Construction of a Syntactic Analysis Map for Yi Shui School through Text Mining and Natural Language Processing Research
Feb 16, 2024Entity and relationship extraction is a crucial component in natural language processing tasks such as knowledge graph construction, question answering system design, and semantic analysis. Most of the information of the Yishui school of traditional Chinese Medicine (TCM) is stored in the form of unstructured classical Chinese text. The key information extraction of TCM texts plays an important role in mining and studying the academic schools of TCM. In order to solve these problems efficiently using artificial intelligence methods, this study constructs a word segmentation and entity relationship extraction model based on conditional random fields under the framework of natural language processing technology to identify and extract the entity relationship of traditional Chinese medicine texts, and uses the common weighting technology of TF-IDF information retrieval and data mining to extract important key entity information in different ancient books. The dependency syntactic parser based on neural network is used to analyze the grammatical relationship between entities in each ancient book article, and it is represented as a tree structure visualization, which lays the foundation for the next construction of the knowledge graph of Yishui school and the use of artificial intelligence methods to carry out the research of TCM academic schools.
LV-Eval: A Balanced Long-Context Benchmark with 5 Length Levels Up to 256K
Feb 06, 2024State-of-the-art large language models (LLMs) are now claiming remarkable supported context lengths of 256k or even more. In contrast, the average context lengths of mainstream benchmarks are insufficient (5k-21k), and they suffer from potential knowledge leakage and inaccurate metrics, resulting in biased evaluation. This paper introduces LV-Eval, a challenging long-context benchmark with five length levels (16k, 32k, 64k, 128k, and 256k) reaching up to 256k words. LV-Eval features two main tasks, single-hop QA and multi-hop QA, comprising 11 bilingual datasets. The design of LV-Eval has incorporated three key techniques, namely confusing facts insertion, keyword and phrase replacement, and keyword-recall-based metric design. The advantages of LV-Eval include controllable evaluation across different context lengths, challenging test instances with confusing facts, mitigated knowledge leakage, and more objective evaluations. We evaluate 10 LLMs on LV-Eval and conduct ablation studies on the techniques used in LV-Eval construction. The results reveal that: (i) Commercial LLMs generally outperform open-source LLMs when evaluated within length levels shorter than their claimed context length. However, their overall performance is surpassed by open-source LLMs with longer context lengths. (ii) Extremely long-context LLMs, such as Yi-6B-200k, exhibit a relatively gentle degradation of performance, but their absolute performances may not necessarily be higher than those of LLMs with shorter context lengths. (iii) LLMs' performances can significantly degrade in the presence of confusing information, especially in the pressure test of "needle in a haystack". (iv) Issues related to knowledge leakage and inaccurate metrics introduce bias in evaluation, and these concerns are alleviated in LV-Eval. All datasets and evaluation codes are released at: https://github.com/infinigence/LVEval.
Kun: Answer Polishment for Chinese Self-Alignment with Instruction Back-Translation
Jan 12, 2024In this paper, we introduce Kun, a novel approach for creating high-quality instruction-tuning datasets for large language models (LLMs) without relying on manual annotations. Adapting a self-training algorithm based on instruction back-translation and answer polishment, Kun leverages unlabelled data from diverse sources such as Wudao, Wanjuan, and SkyPile to generate a substantial dataset of over a million Chinese instructional data points. This approach significantly deviates from traditional methods by using a self-curation process to refine and select the most effective instruction-output pairs. Our experiments with the 6B-parameter Yi model across various benchmarks demonstrate Kun's robustness and scalability. Our method's core contributions lie in its algorithmic advancement, which enhances data retention and clarity, and its innovative data generation approach that substantially reduces the reliance on costly and time-consuming manual annotations. This methodology presents a scalable and efficient solution for improving the instruction-following capabilities of LLMs, with significant implications for their application across diverse fields. The code and dataset can be found at https://github.com/Zheng0428/COIG-Kun
Image encryption for Offshore wind power based on 2D-LCLM and Zhou Yi Eight Trigrams
Jun 02, 2023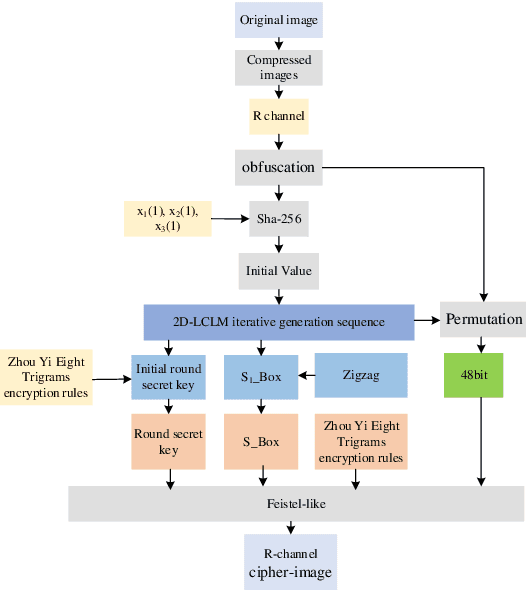
Offshore wind power is an important part of the new power system, due to the complex and changing situation at ocean, its normal operation and maintenance cannot be done without information such as images, therefore, it is especially important to transmit the correct image in the process of information transmission. In this paper, we propose a new encryption algorithm for offshore wind power based on two-dimensional lagged complex logistic mapping (2D-LCLM) and Zhou Yi Eight Trigrams. Firstly, the initial value of the 2D-LCLM is constructed by the Sha-256 to associate the 2D-LCLM with the plaintext. Secondly, a new encryption rule is proposed from the Zhou Yi Eight Trigrams to obfuscate the pixel values and generate the round key. Then, 2D-LCLM is combined with the Zigzag to form an S-box. Finally, the simulation experiment of the algorithm is accomplished. The experimental results demonstrate that the algorithm can resistant common attacks and has prefect encryption performance.
Fast and Interpretable Face Identification for Out-Of-Distribution Data Using Vision Transformers
Nov 06, 2023Most face identification approaches employ a Siamese neural network to compare two images at the image embedding level. Yet, this technique can be subject to occlusion (e.g. faces with masks or sunglasses) and out-of-distribution data. DeepFace-EMD (Phan et al. 2022) reaches state-of-the-art accuracy on out-of-distribution data by first comparing two images at the image level, and then at the patch level. Yet, its later patch-wise re-ranking stage admits a large $O(n^3 \log n)$ time complexity (for $n$ patches in an image) due to the optimal transport optimization. In this paper, we propose a novel, 2-image Vision Transformers (ViTs) that compares two images at the patch level using cross-attention. After training on 2M pairs of images on CASIA Webface (Yi et al. 2014), our model performs at a comparable accuracy as DeepFace-EMD on out-of-distribution data, yet at an inference speed more than twice as fast as DeepFace-EMD (Phan et al. 2022). In addition, via a human study, our model shows promising explainability through the visualization of cross-attention. We believe our work can inspire more explorations in using ViTs for face identification.