 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
Transformers, Contextualism, and Polysemy
Apr 15, 2024
The transformer architecture, introduced by Vaswani et al. (2017), is at the heart of the remarkable recent progress in the development of language models, including famous chatbots such as Chat-gpt and Bard. In this paper, I argue that we an extract from the way the transformer architecture works a picture of the relationship between context and meaning. I call this the transformer picture, and I argue that it is a novel with regard to two related philosophical debates: the contextualism debate regarding the extent of context-sensitivity across natural language, and the polysemy debate regarding how polysemy should be captured within an account of word meaning. Although much of the paper merely tries to position the transformer picture with respect to these two debates, I will also begin to make the case for the transformer picture.
Citation-Enhanced Generation for LLM-based Chatbots
Mar 04, 2024Large language models (LLMs) exhibit powerful general intelligence across diverse scenarios, including their integration into chatbots. However, a vital challenge of LLM-based chatbots is that they may produce hallucinated content in responses, which significantly limits their applicability. Various efforts have been made to alleviate hallucination, such as retrieval augmented generation and reinforcement learning with human feedback, but most of them require additional training and data annotation. In this paper, we propose a novel post-hoc Citation-Enhanced Generation (CEG) approach combined with retrieval argumentation. Unlike previous studies that focus on preventing hallucinations during generation, our method addresses this issue in a post-hoc way. It incorporates a retrieval module to search for supporting documents relevant to the generated content, and employs a natural language inference-based citation generation module. Once the statements in the generated content lack of reference, our model can regenerate responses until all statements are supported by citations. Note that our method is a training-free plug-and-play plugin that is capable of various LLMs. Experiments on various hallucination-related datasets show our framework outperforms state-of-the-art methods in both hallucination detection and response regeneration on three benchmarks. Our codes and dataset will be publicly available.
Book2Dial: Generating Teacher-Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots
Mar 05, 2024
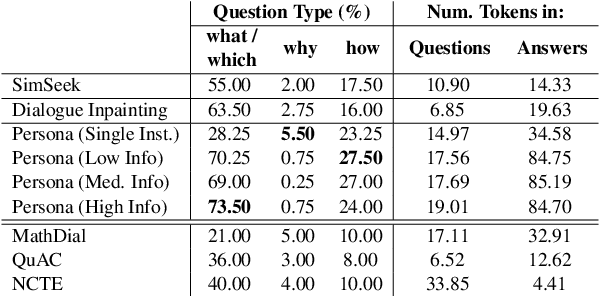
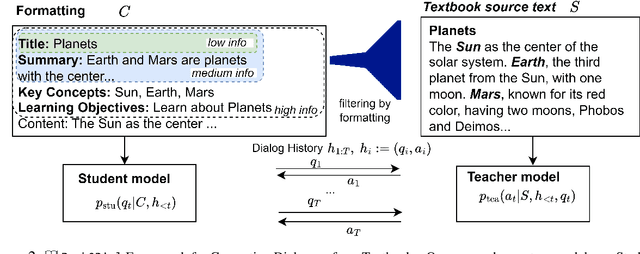
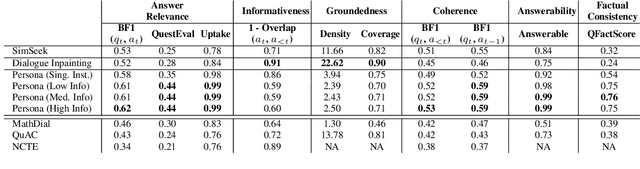
Educational chatbots are a promising tool for assisting student learning. However, the development of effective chatbots in education has been challenging, as high-quality data is seldom available in this domain. In this paper, we propose a framework for generating synthetic teacher-student interactions grounded in a set of textbooks. Our approaches capture one aspect of learning interactions where curious students with partial knowledge interactively ask a teacher questions about the material in the textbook. We highlight various quality criteria that such dialogues should fulfill and compare several approaches relying on either prompting or fine-tuning large language models. We use synthetic dialogues to train educational chatbots and show benefits of further fine-tuning in different educational domains. However, human evaluation shows that our best data synthesis method still suffers from hallucinations and tends to reiterate information from previous conversations. Our findings offer insights for future efforts in synthesizing conversational data that strikes a balance between size and quality. We will open-source our data and code.
iRAG: An Incremental Retrieval Augmented Generation System for Videos
Apr 18, 2024Retrieval augmented generation (RAG) systems combine the strengths of language generation and information retrieval to power many real-world applications like chatbots. Use of RAG for combined understanding of multimodal data such as text, images and videos is appealing but two critical limitations exist: one-time, upfront capture of all content in large multimodal data as text descriptions entails high processing times, and not all information in the rich multimodal data is typically in the text descriptions. Since the user queries are not known apriori, developing a system for multimodal to text conversion and interactive querying of multimodal data is challenging. To address these limitations, we propose iRAG, which augments RAG with a novel incremental workflow to enable interactive querying of large corpus of multimodal data. Unlike traditional RAG, iRAG quickly indexes large repositories of multimodal data, and in the incremental workflow, it uses the index to opportunistically extract more details from select portions of the multimodal data to retrieve context relevant to an interactive user query. Such an incremental workflow avoids long multimodal to text conversion times, overcomes information loss issues by doing on-demand query-specific extraction of details in multimodal data, and ensures high quality of responses to interactive user queries that are often not known apriori. To the best of our knowledge, iRAG is the first system to augment RAG with an incremental workflow to support efficient interactive querying of large, real-world multimodal data. Experimental results on real-world long videos demonstrate 23x to 25x faster video to text ingestion, while ensuring that quality of responses to interactive user queries is comparable to responses from a traditional RAG where all video data is converted to text upfront before any querying.
LAB: Large-Scale Alignment for ChatBots
Mar 06, 2024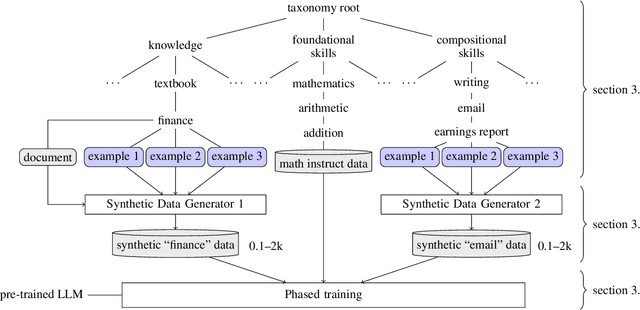
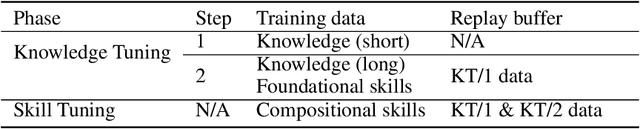
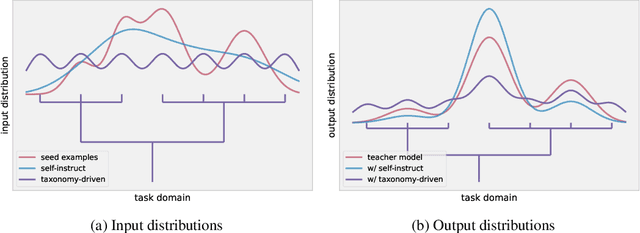
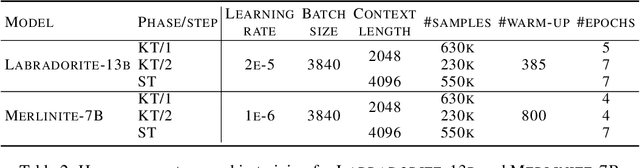
This work introduces LAB (Large-scale Alignment for chatBots), a novel methodology designed to overcome the scalability challenges in the instruction-tuning phase of large language model (LLM) training. Leveraging a taxonomy-guided synthetic data generation process and a multi-phase tuning framework, LAB significantly reduces reliance on expensive human annotations and proprietary models like GPT-4. We demonstrate that LAB-trained models can achieve competitive performance across several benchmarks compared to models trained with traditional human-annotated or GPT-4 generated synthetic data. Thus offering a scalable, cost-effective solution for enhancing LLM capabilities and instruction-following behaviors without the drawbacks of catastrophic forgetting, marking a step forward in the efficient training of LLMs for a wide range of applications.
LMStyle Benchmark: Evaluating Text Style Transfer for Chatbots
Mar 13, 2024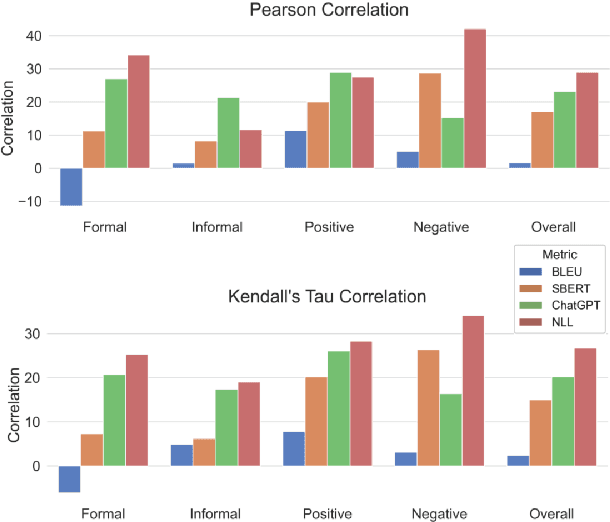
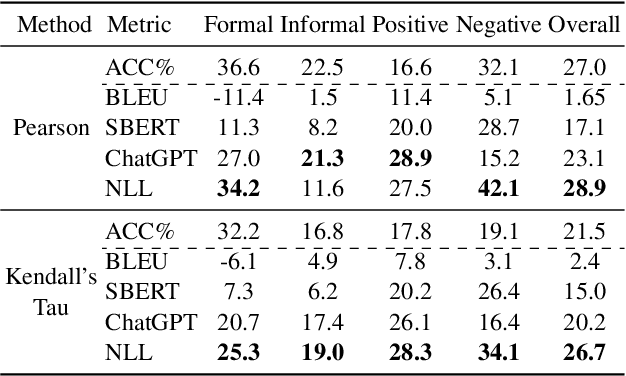
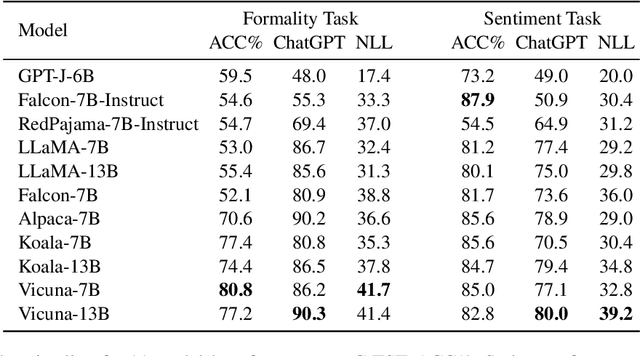

Since the breakthrough of ChatGPT, large language models (LLMs) have garnered significant attention in the research community. With the development of LLMs, the question of text style transfer for conversational models has emerged as a natural extension, where chatbots may possess their own styles or even characters. However, standard evaluation metrics have not yet been established for this new settings. This paper aims to address this issue by proposing the LMStyle Benchmark, a novel evaluation framework applicable to chat-style text style transfer (C-TST), that can measure the quality of style transfer for LLMs in an automated and scalable manner. In addition to conventional style strength metrics, LMStyle Benchmark further considers a novel aspect of metrics called appropriateness, a high-level metrics take account of coherence, fluency and other implicit factors without the aid of reference samples. Our experiments demonstrate that the new evaluation methods introduced by LMStyle Benchmark have a higher correlation with human judgments in terms of appropriateness. Based on LMStyle Benchmark, we present a comprehensive list of evaluation results for popular LLMs, including LLaMA, Alpaca, and Vicuna, reflecting their stylistic properties, such as formality and sentiment strength, along with their appropriateness.
Towards Reliable and Empathetic Depression-Diagnosis-Oriented Chats
Apr 07, 2024Chatbots can serve as a viable tool for preliminary depression diagnosis via interactive conversations with potential patients. Nevertheless, the blend of task-oriented and chit-chat in diagnosis-related dialogues necessitates professional expertise and empathy. Such unique requirements challenge traditional dialogue frameworks geared towards single optimization goals. To address this, we propose an innovative ontology definition and generation framework tailored explicitly for depression diagnosis dialogues, combining the reliability of task-oriented conversations with the appeal of empathy-related chit-chat. We further apply the framework to D$^4$, the only existing public dialogue dataset on depression diagnosis-oriented chats. Exhaustive experimental results indicate significant improvements in task completion and emotional support generation in depression diagnosis, fostering a more comprehensive approach to task-oriented chat dialogue system development and its applications in digital mental health.
A Piece of Theatre: Investigating How Teachers Design LLM Chatbots to Assist Adolescent Cyberbullying Education
Feb 27, 2024Cyberbullying harms teenagers' mental health, and teaching them upstanding intervention is crucial. Wizard-of-Oz studies show chatbots can scale up personalized and interactive cyberbullying education, but implementing such chatbots is a challenging and delicate task. We created a no-code chatbot design tool for K-12 teachers. Using large language models and prompt chaining, our tool allows teachers to prototype bespoke dialogue flows and chatbot utterances. In offering this tool, we explore teachers' distinctive needs when designing chatbots to assist their teaching, and how chatbot design tools might better support them. Our findings reveal that teachers welcome the tool enthusiastically. Moreover, they see themselves as playwrights guiding both the students' and the chatbot's behaviors, while allowing for some improvisation. Their goal is to enable students to rehearse both desirable and undesirable reactions to cyberbullying in a safe environment. We discuss the design opportunities LLM-Chains offer for empowering teachers and the research opportunities this work opens up.
To Recommend or Not: Recommendability Identification in Conversations with Pre-trained Language Models
Apr 08, 2024Most current recommender systems primarily focus on what to recommend, assuming users always require personalized recommendations. However, with the widely spread of ChatGPT and other chatbots, a more crucial problem in the context of conversational systems is how to minimize user disruption when we provide recommendation services for users. While previous research has extensively explored different user intents in dialogue systems, fewer efforts are made to investigate whether recommendations should be provided. In this paper, we formally define the recommendability identification problem, which aims to determine whether recommendations are necessary in a specific scenario. First, we propose and define the recommendability identification task, which investigates the need for recommendations in the current conversational context. A new dataset is constructed. Subsequently, we discuss and evaluate the feasibility of leveraging pre-trained language models (PLMs) for recommendability identification. Finally, through comparative experiments, we demonstrate that directly employing PLMs with zero-shot results falls short of meeting the task requirements. Besides, fine-tuning or utilizing soft prompt techniques yields comparable results to traditional classification methods. Our work is the first to study recommendability before recommendation and provides preliminary ways to make it a fundamental component of the future recommendation system.
Increased LLM Vulnerabilities from Fine-tuning and Quantization
Apr 05, 2024Large Language Models (LLMs) have become very popular and have found use cases in many domains, such as chatbots, auto-task completion agents, and much more. However, LLMs are vulnerable to different types of attacks, such as jailbreaking, prompt injection attacks, and privacy leakage attacks. Foundational LLMs undergo adversarial and alignment training to learn not to generate malicious and toxic content. For specialized use cases, these foundational LLMs are subjected to fine-tuning or quantization for better performance and efficiency. We examine the impact of downstream tasks such as fine-tuning and quantization on LLM vulnerability. We test foundation models like Mistral, Llama, MosaicML, and their fine-tuned versions. Our research shows that fine-tuning and quantization reduces jailbreak resistance significantly, leading to increased LLM vulnerabilities. Finally, we demonstrate the utility of external guardrails in reducing LLM vulnerabilities.