 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Weighted Boxes Fusion: ensembling boxes for object detection models
Oct 29, 2019
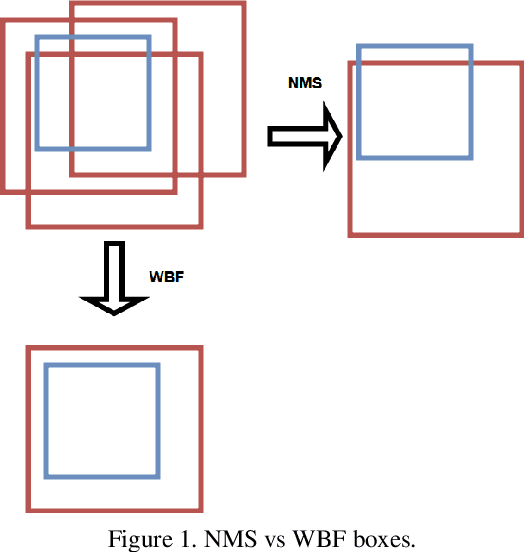


In this work, we introduce a novel Weighted Box Fusion (WBF) ensembling algorithm that boosts the performance by ensembling predictions from different object detection models. Method was tested on predictions of different models trained on large Open Images Dataset. The source code for our approach is publicly available at https://github.com/ZFTurbo/Weighted-Boxes-Fusion
Wasserstein Distance Based Domain Adaptation for Object Detection
Sep 18, 2019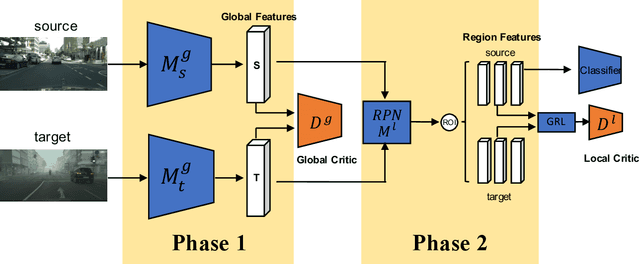
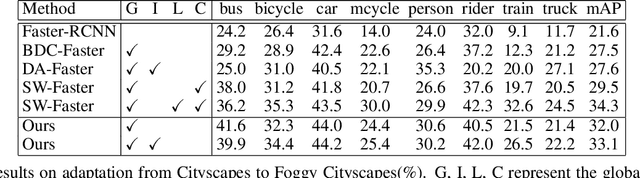


In this paper, we present an adversarial unsupervised domain adaptation framework for object detection. Prior approaches utilize adversarial training based on cross entropy between the source and target domain distributions to learn a shared feature mapping that minimizes the domain gap. Here, we minimize the Wasserstein distance between the two distributions instead of cross entropy or Jensen-Shannon divergence to improve the stability of domain adaptation in high-dimensional feature spaces that are inherent to object detection task. Additionally, we remove the exact consistency constraint of the shared feature mapping between the source and target domains, so that the target feature mapping can be optimized independently, which is necessary in the case of significant domain gap. We empirically show that the proposed framework can mitigate domain shift in different scenarios, and provide improved target domain object detection performance.
Towards Object Detection from Motion
Sep 17, 2019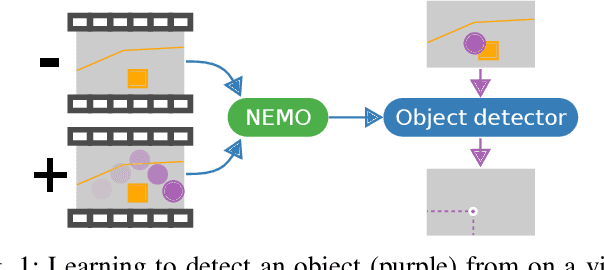
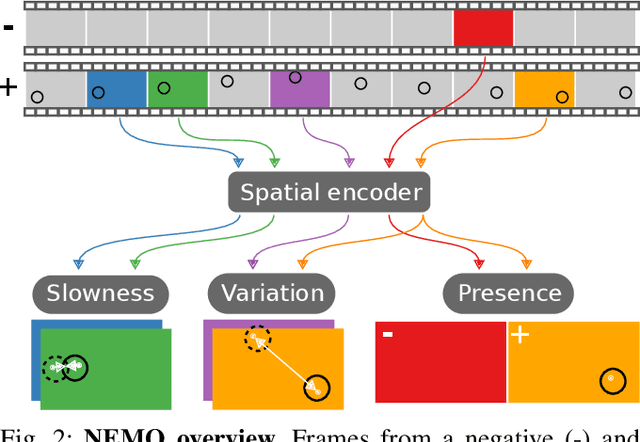

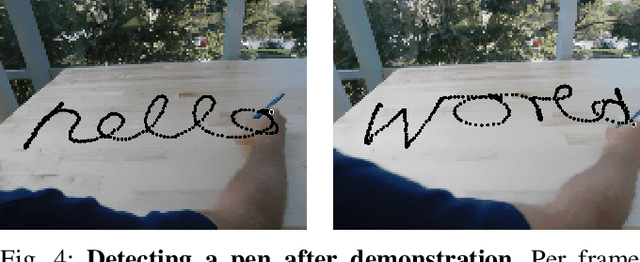
We present a novel approach to weakly supervised object detection. Instead of annotated images, our method only requires two short videos to learn to detect a new object: 1) a video of a moving object and 2) one or more "negative" videos of the scene without the object. The key idea of our algorithm is to train the object detector to produce physically plausible object motion when applied to the first video and to not detect anything in the second video. With this approach, our method learns to locate objects without any object location annotations. Once the model is trained, it performs object detection on single images. We evaluate our method in three robotics settings that afford learning objects from motion: observing moving objects, watching demonstrations of object manipulation, and physically interacting with objects (see a video summary at https://youtu.be/BH0Hv3zZG_4).
YOLO Nano: a Highly Compact You Only Look Once Convolutional Neural Network for Object Detection
Oct 03, 2019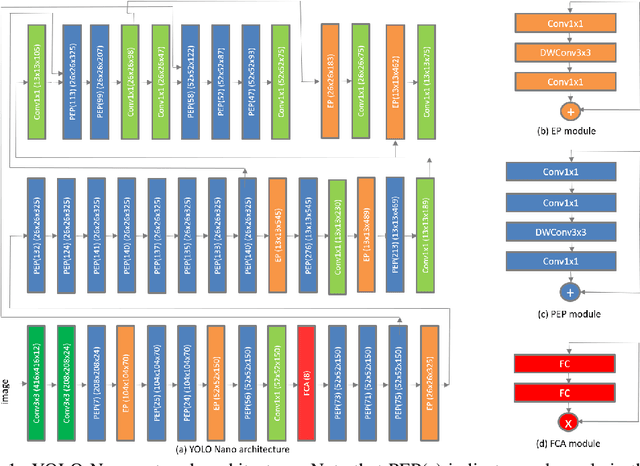
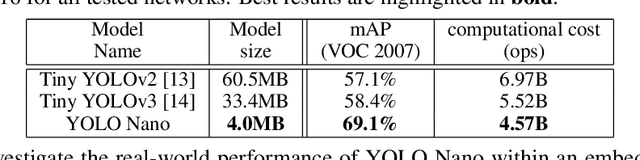
Object detection remains an active area of research in the field of computer vision, and considerable advances and successes has been achieved in this area through the design of deep convolutional neural networks for tackling object detection. Despite these successes, one of the biggest challenges to widespread deployment of such object detection networks on edge and mobile scenarios is the high computational and memory requirements. As such, there has been growing research interest in the design of efficient deep neural network architectures catered for edge and mobile usage. In this study, we introduce YOLO Nano, a highly compact deep convolutional neural network for the task of object detection. A human-machine collaborative design strategy is leveraged to create YOLO Nano, where principled network design prototyping, based on design principles from the YOLO family of single-shot object detection network architectures, is coupled with machine-driven design exploration to create a compact network with highly customized module-level macroarchitecture and microarchitecture designs tailored for the task of embedded object detection. The proposed YOLO Nano possesses a model size of ~4.0MB (>15.1x and >8.3x smaller than Tiny YOLOv2 and Tiny YOLOv3, respectively) and requires 4.57B operations for inference (>34% and ~17% lower than Tiny YOLOv2 and Tiny YOLOv3, respectively) while still achieving an mAP of ~69.1% on the VOC 2007 dataset (~12% and ~10.7% higher than Tiny YOLOv2 and Tiny YOLOv3, respectively). Experiments on inference speed and power efficiency on a Jetson AGX Xavier embedded module at different power budgets further demonstrate the efficacy of YOLO Nano for embedded scenarios.
Enhancing Object Detection in Adverse Conditions using Thermal Imaging
Sep 30, 2019
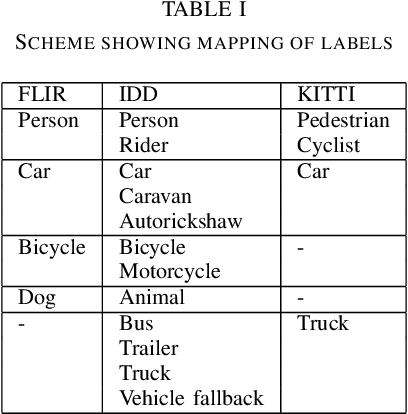
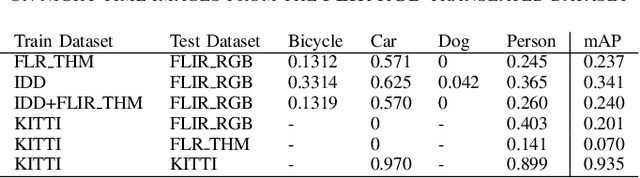
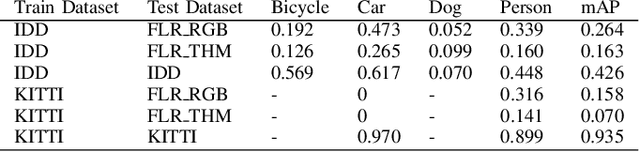
Autonomous driving relies on deriving understanding of objects and scenes through images. These images are often captured by sensors in the visible spectrum. For improved detection capabilities we propose the use of thermal sensors to augment the vision capabilities of an autonomous vehicle. In this paper, we present our investigations on the fusion of visible and thermal spectrum images using a publicly available dataset, and use it to analyze the performance of object recognition on other known driving datasets. We present an comparison of object detection in night time imagery and qualitatively demonstrate that thermal images significantly improve detection accuracy.
Team PFDet's Methods for Open Images Challenge 2019
Oct 25, 2019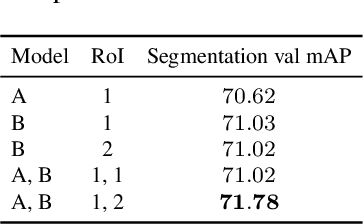

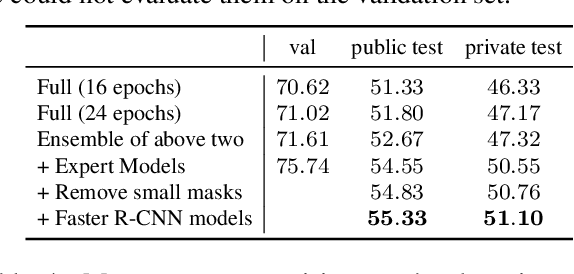
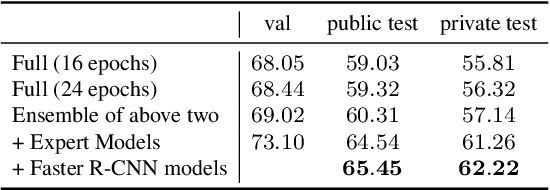
We present the instance segmentation and the object detection method used by team PFDet for Open Images Challenge 2019. We tackle a massive dataset size, huge class imbalance and federated annotations. Using this method, the team PFDet achieved 3rd and 4th place in the instance segmentation and the object detection track, respectively.
RoIMix: Proposal-Fusion among Multiple Images for Underwater Object Detection
Nov 08, 2019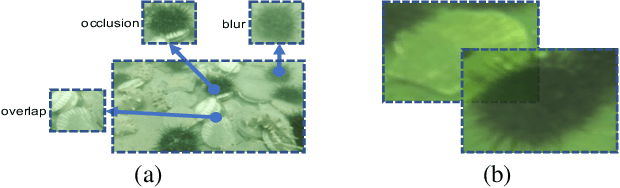

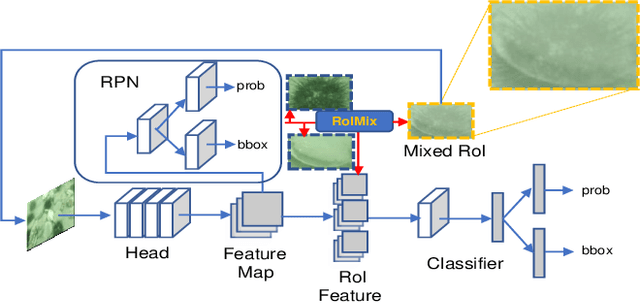

Generic object detection algorithms have proven their excellent performance in recent years. However, object detection on underwater datasets is still less explored. In contrast to generic datasets, underwater images usually have color shift and low contrast; sediment would cause blurring in underwater images. In addition, underwater creatures often appear closely to each other on images due to their living habits. To address these issues, our work investigates augmentation policies to simulate overlapping, occluded and blurred objects, and we construct a model capable of achieving better generalization. We propose an augmentation method called RoIMix, which characterizes interactions among images. Proposals extracted from different images are mixed together. Previous data augmentation methods operate on a single image while we apply RoIMix to multiple images to create enhanced samples as training data. Experiments show that our proposed method improves the performance of region-based object detectors on both Pascal VOC and URPC datasets.
Guided Attention Network for Object Detection and Counting on Drones
Sep 25, 2019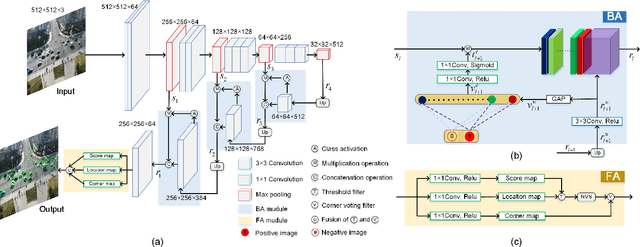
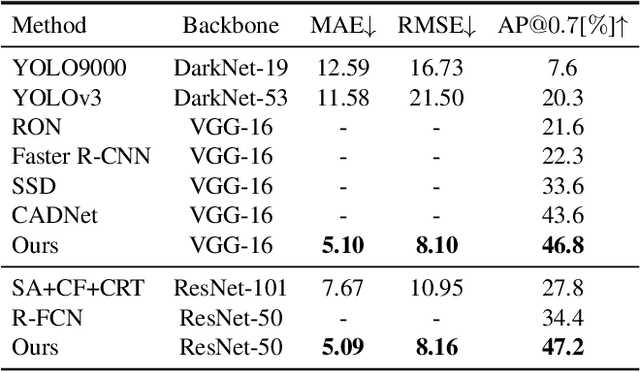
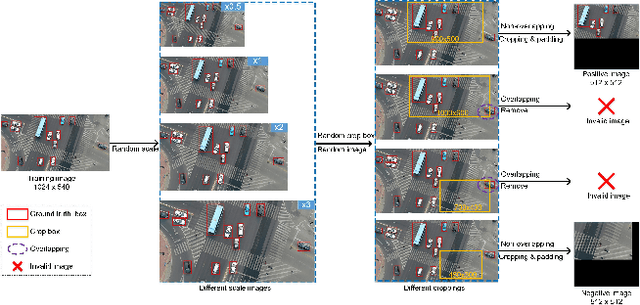
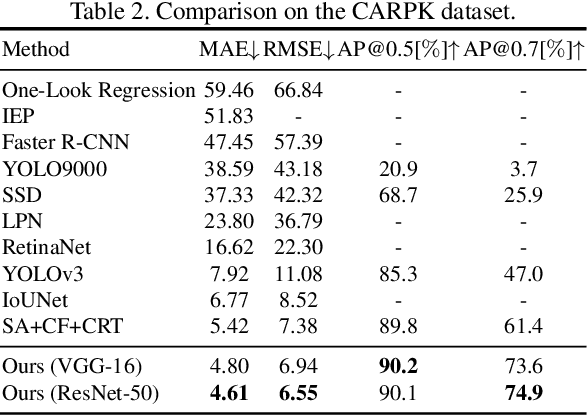
Object detection and counting are related but challenging problems, especially for drone based scenes with small objects and cluttered background. In this paper, we propose a new Guided Attention Network (GANet) to deal with both object detection and counting tasks based on the feature pyramid. Different from the previous methods relying on unsupervised attention modules, we fuse different scales of feature maps by using the proposed weakly-supervised Background Attention (BA) between the background and objects for more semantic feature representation. Then, the Foreground Attention (FA) module is developed to consider both global and local appearance of the object to facilitate accurate localization. Moreover, the new data argumentation strategy is designed to train a robust model in various complex scenes. Extensive experiments on three challenging benchmarks (i.e., UAVDT, CARPK and PUCPR+) show the state-of-the-art detection and counting performance of the proposed method compared with existing methods.
Adversarial Patches Exploiting Contextual Reasoning in Object Detection
Sep 30, 2019


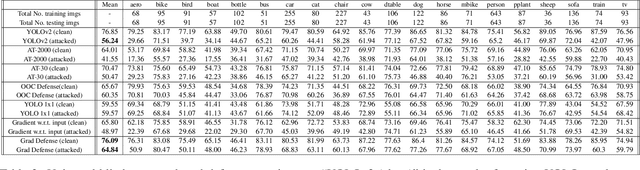
The usefulness of spatial context in most fast object detection algorithms that do a single forward pass per image is well known where they utilize context to improve their accuracy. In fact, they must do it to increase the inference speed by processing the image just once. We show that an adversary can attack the model by exploiting contextual reasoning. We develop adversarial attack algorithms that make an object detector blind to a particular category chosen by the adversary even though the patch does not overlap with the missed detections. We also show that limiting the use of contextual reasoning in learning the object detector acts as a form of defense that improves the accuracy of the detector after an attack. We believe defending against our practical adversarial attack algorithms is not easy and needs attention from the research community.
Range Adaptation for 3D Object Detection in LiDAR
Sep 26, 2019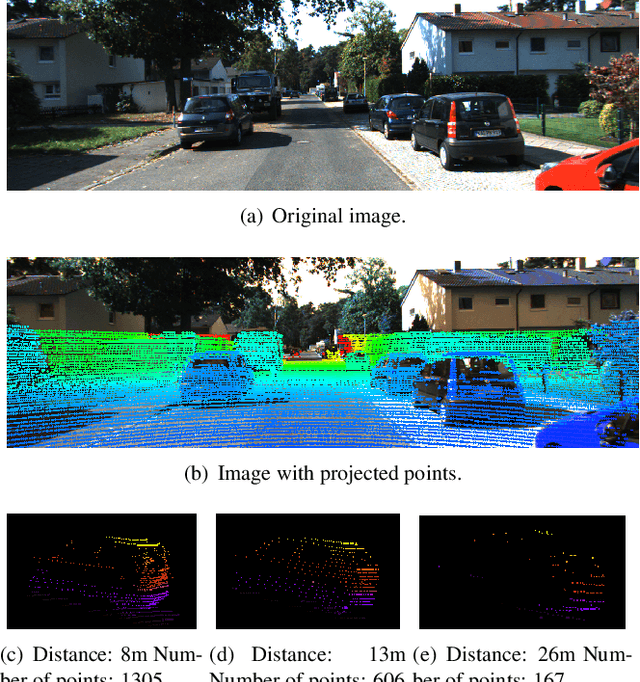
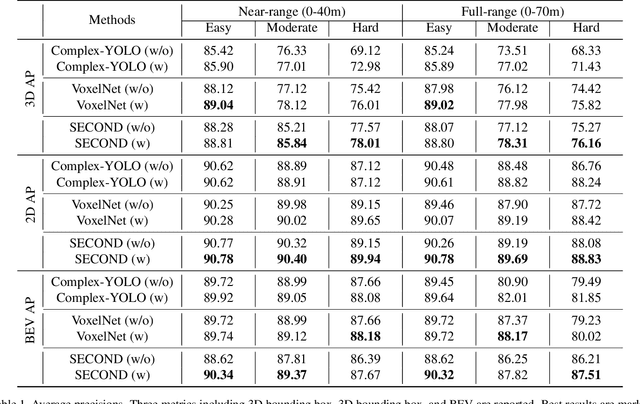
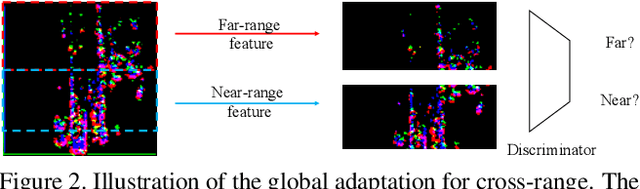

LiDAR-based 3D object detection plays a crucial role in modern autonomous driving systems. LiDAR data often exhibit severe changes in properties across different observation ranges. In this paper, we explore cross-range adaptation for 3D object detection using LiDAR, i.e., far-range observations are adapted to near-range. This way, far-range detection is optimized for similar performance to near-range one. We adopt a bird-eyes view (BEV) detection framework to perform the proposed model adaptation. Our model adaptation consists of an adversarial global adaptation, and a fine-grained local adaptation. The proposed cross range adaptation framework is validated on three state-of-the-art LiDAR based object detection networks, and we consistently observe performance improvement on the far-range objects, without adding any auxiliary parameters to the model. To the best of our knowledge, this paper is the first attempt to study cross-range LiDAR adaptation for object detection in point clouds. To demonstrate the generality of the proposed adaptation framework, experiments on more challenging cross-device adaptation are further conducted, and a new LiDAR dataset with high-quality annotated point clouds is released to promote future research.