 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration
May 27, 2024This study investigates whether Compressed-Language Models (CLMs), i.e. language models operating on raw byte streams from Compressed File Formats~(CFFs), can understand files compressed by CFFs. We focus on the JPEG format as a representative CFF, given its commonality and its representativeness of key concepts in compression, such as entropy coding and run-length encoding. We test if CLMs understand the JPEG format by probing their capabilities to perform along three axes: recognition of inherent file properties, handling of files with anomalies, and generation of new files. Our findings demonstrate that CLMs can effectively perform these tasks. These results suggest that CLMs can understand the semantics of compressed data when directly operating on the byte streams of files produced by CFFs. The possibility to directly operate on raw compressed files offers the promise to leverage some of their remarkable characteristics, such as their ubiquity, compactness, multi-modality and segment-nature.
Lazy Layers to Make Fine-Tuned Diffusion Models More Traceable
May 01, 2024Foundational generative models should be traceable to protect their owners and facilitate safety regulation. To achieve this, traditional approaches embed identifiers based on supervisory trigger-response signals, which are commonly known as backdoor watermarks. They are prone to failure when the model is fine-tuned with nontrigger data. Our experiments show that this vulnerability is due to energetic changes in only a few 'busy' layers during fine-tuning. This yields a novel arbitrary-in-arbitrary-out (AIAO) strategy that makes watermarks resilient to fine-tuning-based removal. The trigger-response pairs of AIAO samples across various neural network depths can be used to construct watermarked subpaths, employing Monte Carlo sampling to achieve stable verification results. In addition, unlike the existing methods of designing a backdoor for the input/output space of diffusion models, in our method, we propose to embed the backdoor into the feature space of sampled subpaths, where a mask-controlled trigger function is proposed to preserve the generation performance and ensure the invisibility of the embedded backdoor. Our empirical studies on the MS-COCO, AFHQ, LSUN, CUB-200, and DreamBooth datasets confirm the robustness of AIAO; while the verification rates of other trigger-based methods fall from ~90% to ~70% after fine-tuning, those of our method remain consistently above 90%.
Multi-Stream Cellular Test-Time Adaptation of Real-Time Models Evolving in Dynamic Environments
Apr 27, 2024In the era of the Internet of Things (IoT), objects connect through a dynamic network, empowered by technologies like 5G, enabling real-time data sharing. However, smart objects, notably autonomous vehicles, face challenges in critical local computations due to limited resources. Lightweight AI models offer a solution but struggle with diverse data distributions. To address this limitation, we propose a novel Multi-Stream Cellular Test-Time Adaptation (MSC-TTA) setup where models adapt on the fly to a dynamic environment divided into cells. Then, we propose a real-time adaptive student-teacher method that leverages the multiple streams available in each cell to quickly adapt to changing data distributions. We validate our methodology in the context of autonomous vehicles navigating across cells defined based on location and weather conditions. To facilitate future benchmarking, we release a new multi-stream large-scale synthetic semantic segmentation dataset, called DADE, and show that our multi-stream approach outperforms a single-stream baseline. We believe that our work will open research opportunities in the IoT and 5G eras, offering solutions for real-time model adaptation.
Combating Missing Modalities in Egocentric Videos at Test Time
Apr 23, 2024Understanding videos that contain multiple modalities is crucial, especially in egocentric videos, where combining various sensory inputs significantly improves tasks like action recognition and moment localization. However, real-world applications often face challenges with incomplete modalities due to privacy concerns, efficiency needs, or hardware issues. Current methods, while effective, often necessitate retraining the model entirely to handle missing modalities, making them computationally intensive, particularly with large training datasets. In this study, we propose a novel approach to address this issue at test time without requiring retraining. We frame the problem as a test-time adaptation task, where the model adjusts to the available unlabeled data at test time. Our method, MiDl~(Mutual information with self-Distillation), encourages the model to be insensitive to the specific modality source present during testing by minimizing the mutual information between the prediction and the available modality. Additionally, we incorporate self-distillation to maintain the model's original performance when both modalities are available. MiDl represents the first self-supervised, online solution for handling missing modalities exclusively at test time. Through experiments with various pretrained models and datasets, MiDl demonstrates substantial performance improvement without the need for retraining.
Continual Learning on a Diet: Learning from Sparsely Labeled Streams Under Constrained Computation
Apr 19, 2024
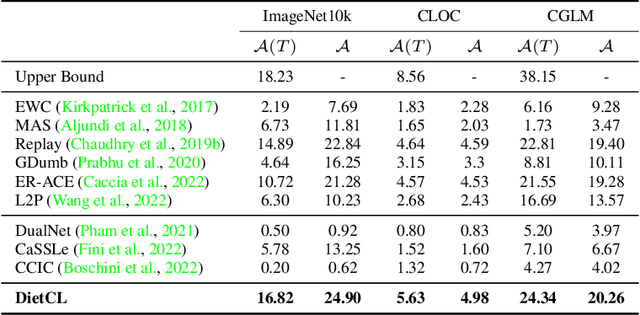


We propose and study a realistic Continual Learning (CL) setting where learning algorithms are granted a restricted computational budget per time step while training. We apply this setting to large-scale semi-supervised Continual Learning scenarios with sparse label rates. Previous proficient CL methods perform very poorly in this challenging setting. Overfitting to the sparse labeled data and insufficient computational budget are the two main culprits for such a poor performance. Our new setting encourages learning methods to effectively and efficiently utilize the unlabeled data during training. To that end, we propose a simple but highly effective baseline, DietCL, which utilizes both unlabeled and labeled data jointly. DietCL meticulously allocates computational budget for both types of data. We validate our baseline, at scale, on several datasets, e.g., CLOC, ImageNet10K, and CGLM, under constraint budget setups. DietCL outperforms, by a large margin, all existing supervised CL algorithms as well as more recent continual semi-supervised methods. Our extensive analysis and ablations demonstrate that DietCL is stable under a full spectrum of label sparsity, computational budget, and various other ablations.
SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
Apr 17, 2024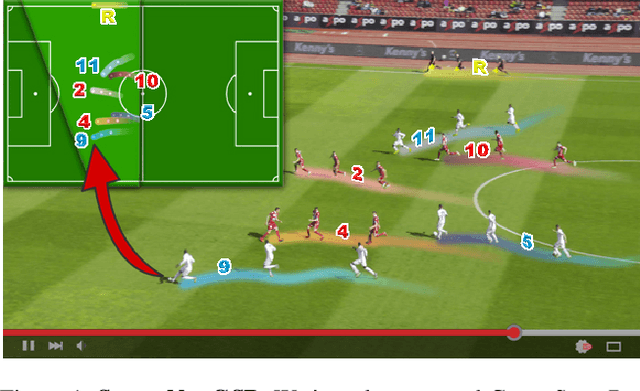
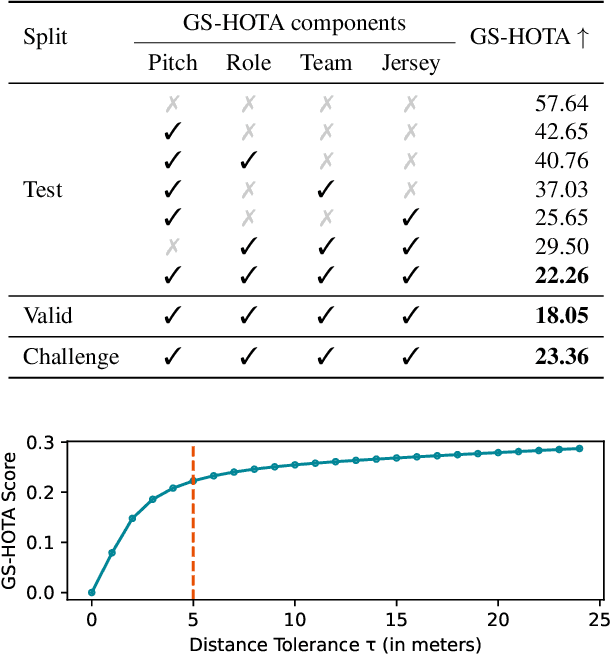
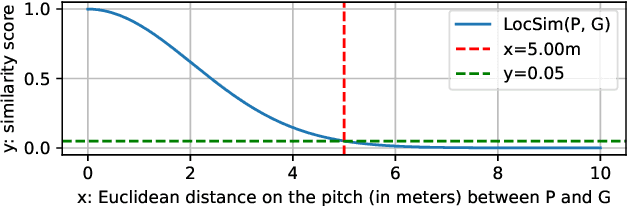

Tracking and identifying athletes on the pitch holds a central role in collecting essential insights from the game, such as estimating the total distance covered by players or understanding team tactics. This tracking and identification process is crucial for reconstructing the game state, defined by the athletes' positions and identities on a 2D top-view of the pitch, (i.e. a minimap). However, reconstructing the game state from videos captured by a single camera is challenging. It requires understanding the position of the athletes and the viewpoint of the camera to localize and identify players within the field. In this work, we formalize the task of Game State Reconstruction and introduce SoccerNet-GSR, a novel Game State Reconstruction dataset focusing on football videos. SoccerNet-GSR is composed of 200 video sequences of 30 seconds, annotated with 9.37 million line points for pitch localization and camera calibration, as well as over 2.36 million athlete positions on the pitch with their respective role, team, and jersey number. Furthermore, we introduce GS-HOTA, a novel metric to evaluate game state reconstruction methods. Finally, we propose and release an end-to-end baseline for game state reconstruction, bootstrapping the research on this task. Our experiments show that GSR is a challenging novel task, which opens the field for future research. Our dataset and codebase are publicly available at https://github.com/SoccerNet/sn-gamestate.
X-VARS: Introducing Explainability in Football Refereeing with Multi-Modal Large Language Model
Apr 07, 2024
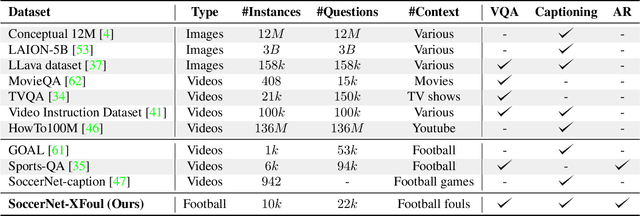
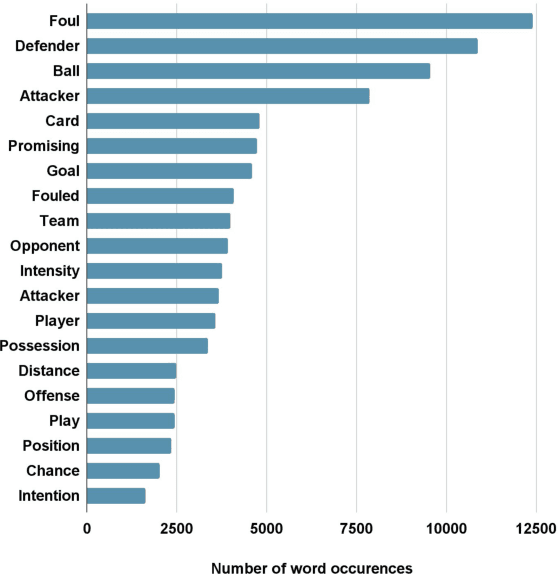

The rapid advancement of artificial intelligence has led to significant improvements in automated decision-making. However, the increased performance of models often comes at the cost of explainability and transparency of their decision-making processes. In this paper, we investigate the capabilities of large language models to explain decisions, using football refereeing as a testing ground, given its decision complexity and subjectivity. We introduce the Explainable Video Assistant Referee System, X-VARS, a multi-modal large language model designed for understanding football videos from the point of view of a referee. X-VARS can perform a multitude of tasks, including video description, question answering, action recognition, and conducting meaningful conversations based on video content and in accordance with the Laws of the Game for football referees. We validate X-VARS on our novel dataset, SoccerNet-XFoul, which consists of more than 22k video-question-answer triplets annotated by over 70 experienced football referees. Our experiments and human study illustrate the impressive capabilities of X-VARS in interpreting complex football clips. Furthermore, we highlight the potential of X-VARS to reach human performance and support football referees in the future.
DATENeRF: Depth-Aware Text-based Editing of NeRFs
Apr 06, 2024Recent advancements in diffusion models have shown remarkable proficiency in editing 2D images based on text prompts. However, extending these techniques to edit scenes in Neural Radiance Fields (NeRF) is complex, as editing individual 2D frames can result in inconsistencies across multiple views. Our crucial insight is that a NeRF scene's geometry can serve as a bridge to integrate these 2D edits. Utilizing this geometry, we employ a depth-conditioned ControlNet to enhance the coherence of each 2D image modification. Moreover, we introduce an inpainting approach that leverages the depth information of NeRF scenes to distribute 2D edits across different images, ensuring robustness against errors and resampling challenges. Our results reveal that this methodology achieves more consistent, lifelike, and detailed edits than existing leading methods for text-driven NeRF scene editing.
Towards Automated Movie Trailer Generation
Apr 04, 2024Movie trailers are an essential tool for promoting films and attracting audiences. However, the process of creating trailers can be time-consuming and expensive. To streamline this process, we propose an automatic trailer generation framework that generates plausible trailers from a full movie by automating shot selection and composition. Our approach draws inspiration from machine translation techniques and models the movies and trailers as sequences of shots, thus formulating the trailer generation problem as a sequence-to-sequence task. We introduce Trailer Generation Transformer (TGT), a deep-learning framework utilizing an encoder-decoder architecture. TGT movie encoder is tasked with contextualizing each movie shot representation via self-attention, while the autoregressive trailer decoder predicts the feature representation of the next trailer shot, accounting for the relevance of shots' temporal order in trailers. Our TGT significantly outperforms previous methods on a comprehensive suite of metrics.
Privacy-preserving Optics for Enhancing Protection in Face De-identification
Mar 31, 2024



The modern surge in camera usage alongside widespread computer vision technology applications poses significant privacy and security concerns. Current artificial intelligence (AI) technologies aid in recognizing relevant events and assisting in daily tasks in homes, offices, hospitals, etc. The need to access or process personal information for these purposes raises privacy concerns. While software-level solutions like face de-identification provide a good privacy/utility trade-off, they present vulnerabilities to sniffing attacks. In this paper, we propose a hardware-level face de-identification method to solve this vulnerability. Specifically, our approach first learns an optical encoder along with a regression model to obtain a face heatmap while hiding the face identity from the source image. We also propose an anonymization framework that generates a new face using the privacy-preserving image, face heatmap, and a reference face image from a public dataset as input. We validate our approach with extensive simulations and hardware experiments.