 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-H: Autonomous Driving with Hierarchical Agents
Jun 05, 2024Due to the impressive capabilities of multimodal large language models (MLLMs), recent works have focused on employing MLLM-based agents for autonomous driving in large-scale and dynamic environments. However, prevalent approaches often directly translate high-level instructions into low-level vehicle control signals, which deviates from the inherent language generation paradigm of MLLMs and fails to fully harness their emergent powers. As a result, the generalizability of these methods is highly restricted by autonomous driving datasets used during fine-tuning. To tackle this challenge, we propose to connect high-level instructions and low-level control signals with mid-level language-driven commands, which are more fine-grained than high-level instructions but more universal and explainable than control signals, and thus can effectively bridge the gap in between. We implement this idea through a hierarchical multi-agent driving system named AD-H, including a MLLM planner for high-level reasoning and a lightweight controller for low-level execution. The hierarchical design liberates the MLLM from low-level control signal decoding and therefore fully releases their emergent capability in high-level perception, reasoning, and planning. We build a new dataset with action hierarchy annotations. Comprehensive closed-loop evaluations demonstrate several key advantages of our proposed AD-H system. First, AD-H can notably outperform state-of-the-art methods in achieving exceptional driving performance, even exhibiting self-correction capabilities during vehicle operation, a scenario not encountered in the training dataset. Second, AD-H demonstrates superior generalization under long-horizon instructions and novel environmental conditions, significantly surpassing current state-of-the-art methods. We will make our data and code publicly accessible at https://github.com/zhangzaibin/AD-H
Auto-Encoding or Auto-Regression? A Reality Check on Causality of Self-Attention-Based Sequential Recommenders
Jun 04, 2024The comparison between Auto-Encoding (AE) and Auto-Regression (AR) has become an increasingly important topic with recent advances in sequential recommendation. At the heart of this discussion lies the comparison of BERT4Rec and SASRec, which serve as representative AE and AR models for self-attentive sequential recommenders. Yet the conclusion of this debate remains uncertain due to: (1) the lack of fair and controlled environments for experiments and evaluations; and (2) the presence of numerous confounding factors w.r.t. feature selection, modeling choices and optimization algorithms. In this work, we aim to answer this question by conducting a series of controlled experiments. We start by tracing the AE/AR debate back to its origin through a systematic re-evaluation of SASRec and BERT4Rec, discovering that AR models generally surpass AE models in sequential recommendation. In addition, we find that AR models further outperforms AE models when using a customized design space that includes additional features, modeling approaches and optimization techniques. Furthermore, the performance advantage of AR models persists in the broader HuggingFace transformer ecosystems. Lastly, we provide potential explanations and insights into AE/AR performance from two key perspectives: low-rank approximation and inductive bias. We make our code and data available at https://github.com/yueqirex/ModSAR
MOSEAC: Streamlined Variable Time Step Reinforcement Learning
Jun 03, 2024Traditional reinforcement learning (RL) methods typically employ a fixed control loop, where each cycle corresponds to an action. This rigidity poses challenges in practical applications, as the optimal control frequency is task-dependent. A suboptimal choice can lead to high computational demands and reduced exploration efficiency. Variable Time Step Reinforcement Learning (VTS-RL) addresses these issues by using adaptive frequencies for the control loop, executing actions only when necessary. This approach, rooted in reactive programming principles, reduces computational load and extends the action space by including action durations. However, VTS-RL's implementation is often complicated by the need to tune multiple hyperparameters that govern exploration in the multi-objective action-duration space (i.e., balancing task performance and number of time steps to achieve a goal). To overcome these challenges, we introduce the Multi-Objective Soft Elastic Actor-Critic (MOSEAC) method. This method features an adaptive reward scheme that adjusts hyperparameters based on observed trends in task rewards during training. This scheme reduces the complexity of hyperparameter tuning, requiring a single hyperparameter to guide exploration, thereby simplifying the learning process and lowering deployment costs. We validate the MOSEAC method through simulations in a Newtonian kinematics environment, demonstrating high task and training performance with fewer time steps, ultimately lowering energy consumption. This validation shows that MOSEAC streamlines RL algorithm deployment by automatically tuning the agent control loop frequency using a single parameter. Its principles can be applied to enhance any RL algorithm, making it a versatile solution for various applications.
Learning Manipulation by Predicting Interaction
Jun 01, 2024Representation learning approaches for robotic manipulation have boomed in recent years. Due to the scarcity of in-domain robot data, prevailing methodologies tend to leverage large-scale human video datasets to extract generalizable features for visuomotor policy learning. Despite the progress achieved, prior endeavors disregard the interactive dynamics that capture behavior patterns and physical interaction during the manipulation process, resulting in an inadequate understanding of the relationship between objects and the environment. To this end, we propose a general pre-training pipeline that learns Manipulation by Predicting the Interaction (MPI) and enhances the visual representation.Given a pair of keyframes representing the initial and final states, along with language instructions, our algorithm predicts the transition frame and detects the interaction object, respectively. These two learning objectives achieve superior comprehension towards "how-to-interact" and "where-to-interact". We conduct a comprehensive evaluation of several challenging robotic tasks.The experimental results demonstrate that MPI exhibits remarkable improvement by 10% to 64% compared with previous state-of-the-art in real-world robot platforms as well as simulation environments. Code and checkpoints are publicly shared at https://github.com/OpenDriveLab/MPI.
Lane Segmentation Refinement with Diffusion Models
May 01, 2024The lane graph is a key component for building high-definition (HD) maps and crucial for downstream tasks such as autonomous driving or navigation planning. Previously, He et al. (2022) explored the extraction of the lane-level graph from aerial imagery utilizing a segmentation based approach. However, segmentation networks struggle to achieve perfect segmentation masks resulting in inaccurate lane graph extraction. We explore additional enhancements to refine this segmentation-based approach and extend it with a diffusion probabilistic model (DPM) component. This combination further improves the GEO F1 and TOPO F1 scores, which are crucial indicators of the quality of a lane graph, in the undirected graph in non-intersection areas. We conduct experiments on a publicly available dataset, demonstrating that our method outperforms the previous approach, particularly in enhancing the connectivity of such a graph, as measured by the TOPO F1 score. Moreover, we perform ablation studies on the individual components of our method to understand their contribution and evaluate their effectiveness.
Other Tokens Matter: Exploring Global and Local Features of Vision Transformers for Object Re-Identification
Apr 23, 2024Object Re-Identification (Re-ID) aims to identify and retrieve specific objects from images captured at different places and times. Recently, object Re-ID has achieved great success with the advances of Vision Transformers (ViT). However, the effects of the global-local relation have not been fully explored in Transformers for object Re-ID. In this work, we first explore the influence of global and local features of ViT and then further propose a novel Global-Local Transformer (GLTrans) for high-performance object Re-ID. We find that the features from last few layers of ViT already have a strong representational ability, and the global and local information can mutually enhance each other. Based on this fact, we propose a Global Aggregation Encoder (GAE) to utilize the class tokens of the last few Transformer layers and learn comprehensive global features effectively. Meanwhile, we propose the Local Multi-layer Fusion (LMF) which leverages both the global cues from GAE and multi-layer patch tokens to explore the discriminative local representations. Extensive experiments demonstrate that our proposed method achieves superior performance on four object Re-ID benchmarks.
Any2Point: Empowering Any-modality Large Models for Efficient 3D Understanding
Apr 11, 2024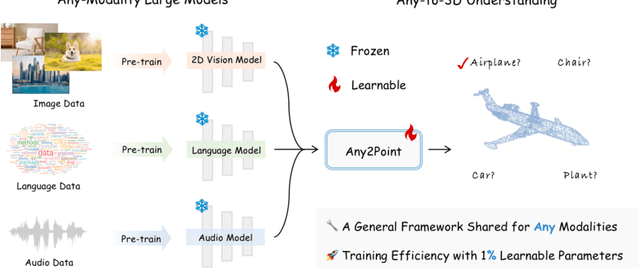
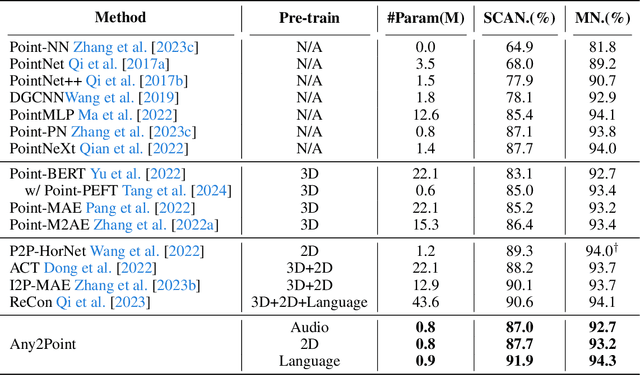
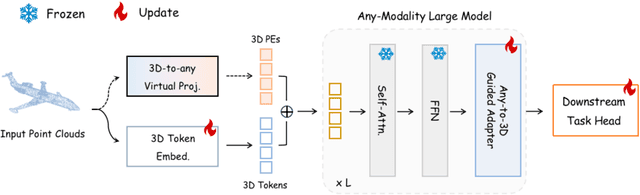

Large foundation models have recently emerged as a prominent focus of interest, attaining superior performance in widespread scenarios. Due to the scarcity of 3D data, many efforts have been made to adapt pre-trained transformers from vision to 3D domains. However, such 2D-to-3D approaches are still limited, due to the potential loss of spatial geometries and high computation cost. More importantly, their frameworks are mainly designed for 2D models, lacking a general any-to-3D paradigm. In this paper, we introduce Any2Point, a parameter-efficient method to empower any-modality large models (vision, language, audio) for 3D understanding. Given a frozen transformer from any source modality, we propose a 3D-to-any (1D or 2D) virtual projection strategy that correlates the input 3D points to the original 1D or 2D positions within the source modality. This mechanism enables us to assign each 3D token with a positional encoding paired with the pre-trained model, which avoids 3D geometry loss caused by the true projection and better motivates the transformer for 3D learning with 1D/2D positional priors. Then, within each transformer block, we insert an any-to-3D guided adapter module for parameter-efficient fine-tuning. The adapter incorporates prior spatial knowledge from the source modality to guide the local feature aggregation of 3D tokens, compelling the semantic adaption of any-modality transformers. We conduct extensive experiments to showcase the effectiveness and efficiency of our method. Code and models are released at https://github.com/Ivan-Tang-3D/Any2Point.
Open-Vocabulary Federated Learning with Multimodal Prototyping
Apr 02, 2024Existing federated learning (FL) studies usually assume the training label space and test label space are identical. However, in real-world applications, this assumption is too ideal to be true. A new user could come up with queries that involve data from unseen classes, and such open-vocabulary queries would directly defect such FL systems. Therefore, in this work, we explicitly focus on the under-explored open-vocabulary challenge in FL. That is, for a new user, the global server shall understand her/his query that involves arbitrary unknown classes. To address this problem, we leverage the pre-trained vision-language models (VLMs). In particular, we present a novel adaptation framework tailored for VLMs in the context of FL, named as Federated Multimodal Prototyping (Fed-MP). Fed-MP adaptively aggregates the local model weights based on light-weight client residuals, and makes predictions based on a novel multimodal prototyping mechanism. Fed-MP exploits the knowledge learned from the seen classes, and robustifies the adapted VLM to unseen categories. Our empirical evaluation on various datasets validates the effectiveness of Fed-MP.
Exploring Dynamic Transformer for Efficient Object Tracking
Mar 26, 2024



The speed-precision trade-off is a critical problem for visual object tracking which usually requires low latency and deployment on constrained resources. Existing solutions for efficient tracking mainly focus on adopting light-weight backbones or modules, which nevertheless come at the cost of a sacrifice in precision. In this paper, inspired by dynamic network routing, we propose DyTrack, a dynamic transformer framework for efficient tracking. Real-world tracking scenarios exhibit diverse levels of complexity. We argue that a simple network is sufficient for easy frames in video sequences, while more computation could be assigned to difficult ones. DyTrack automatically learns to configure proper reasoning routes for various inputs, gaining better utilization of the available computational budget. Thus, it can achieve higher performance with the same running speed. We formulate instance-specific tracking as a sequential decision problem and attach terminating branches to intermediate layers of the entire model. Especially, to fully utilize the computations, we introduce the feature recycling mechanism to reuse the outputs of predecessors. Furthermore, a target-aware self-distillation strategy is designed to enhance the discriminating capabilities of early predictions by effectively mimicking the representation pattern of the deep model. Extensive experiments on multiple benchmarks demonstrate that DyTrack achieves promising speed-precision trade-offs with only a single model. For instance, DyTrack obtains 64.9% AUC on LaSOT with a speed of 256 fps.
HPL-ESS: Hybrid Pseudo-Labeling for Unsupervised Event-based Semantic Segmentation
Mar 25, 2024Event-based semantic segmentation has gained popularity due to its capability to deal with scenarios under high-speed motion and extreme lighting conditions, which cannot be addressed by conventional RGB cameras. Since it is hard to annotate event data, previous approaches rely on event-to-image reconstruction to obtain pseudo labels for training. However, this will inevitably introduce noise, and learning from noisy pseudo labels, especially when generated from a single source, may reinforce the errors. This drawback is also called confirmation bias in pseudo-labeling. In this paper, we propose a novel hybrid pseudo-labeling framework for unsupervised event-based semantic segmentation, HPL-ESS, to alleviate the influence of noisy pseudo labels. In particular, we first employ a plain unsupervised domain adaptation framework as our baseline, which can generate a set of pseudo labels through self-training. Then, we incorporate offline event-to-image reconstruction into the framework, and obtain another set of pseudo labels by predicting segmentation maps on the reconstructed images. A noisy label learning strategy is designed to mix the two sets of pseudo labels and enhance the quality. Moreover, we propose a soft prototypical alignment module to further improve the consistency of target domain features. Extensive experiments show that our proposed method outperforms existing state-of-the-art methods by a large margin on the DSEC-Semantic dataset (+5.88% accuracy, +10.32% mIoU), which even surpasses several supervised methods.