 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Prediction-Aware Contrastive Learning Framework for Multi-Intent NLU
May 05, 2024Multi-intent natural language understanding (NLU) presents a formidable challenge due to the model confusion arising from multiple intents within a single utterance. While previous works train the model contrastively to increase the margin between different multi-intent labels, they are less suited to the nuances of multi-intent NLU. They ignore the rich information between the shared intents, which is beneficial to constructing a better embedding space, especially in low-data scenarios. We introduce a two-stage Prediction-Aware Contrastive Learning (PACL) framework for multi-intent NLU to harness this valuable knowledge. Our approach capitalizes on shared intent information by integrating word-level pre-training and prediction-aware contrastive fine-tuning. We construct a pre-training dataset using a word-level data augmentation strategy. Subsequently, our framework dynamically assigns roles to instances during contrastive fine-tuning while introducing a prediction-aware contrastive loss to maximize the impact of contrastive learning. We present experimental results and empirical analysis conducted on three widely used datasets, demonstrating that our method surpasses the performance of three prominent baselines on both low-data and full-data scenarios.
Unlocking Multi-View Insights in Knowledge-Dense Retrieval-Augmented Generation
Apr 19, 2024While Retrieval-Augmented Generation (RAG) plays a crucial role in the application of Large Language Models (LLMs), existing retrieval methods in knowledge-dense domains like law and medicine still suffer from a lack of multi-perspective views, which are essential for improving interpretability and reliability. Previous research on multi-view retrieval often focused solely on different semantic forms of queries, neglecting the expression of specific domain knowledge perspectives. This paper introduces a novel multi-view RAG framework, MVRAG, tailored for knowledge-dense domains that utilizes intention-aware query rewriting from multiple domain viewpoints to enhance retrieval precision, thereby improving the effectiveness of the final inference. Experiments conducted on legal and medical case retrieval demonstrate significant improvements in recall and precision rates with our framework. Our multi-perspective retrieval approach unleashes the potential of multi-view information enhancing RAG tasks, accelerating the further application of LLMs in knowledge-intensive fields.
Tastle: Distract Large Language Models for Automatic Jailbreak Attack
Mar 13, 2024



Large language models (LLMs) have achieved significant advances in recent days. Extensive efforts have been made before the public release of LLMs to align their behaviors with human values. The primary goal of alignment is to ensure their helpfulness, honesty and harmlessness. However, even meticulously aligned LLMs remain vulnerable to malicious manipulations such as jailbreaking, leading to unintended behaviors. The jailbreak is to intentionally develop a malicious prompt that escapes from the LLM security restrictions to produce uncensored detrimental contents. Previous works explore different jailbreak methods for red teaming LLMs, yet they encounter challenges regarding to effectiveness and scalability. In this work, we propose Tastle, a novel black-box jailbreak framework for automated red teaming of LLMs. We designed malicious content concealing and memory reframing with an iterative optimization algorithm to jailbreak LLMs, motivated by the research about the distractibility and over-confidence phenomenon of LLMs. Extensive experiments of jailbreaking both open-source and proprietary LLMs demonstrate the superiority of our framework in terms of effectiveness, scalability and transferability. We also evaluate the effectiveness of existing jailbreak defense methods against our attack and highlight the crucial need to develop more effective and practical defense strategies.
Self-DC: When to retrieve and When to generate? Self Divide-and-Conquer for Compositional Unknown Questions
Feb 21, 2024Retrieve-then-read and generate-then-read are two typical solutions to handle unknown and known questions in open-domain question-answering, while the former retrieves necessary external knowledge and the later prompt the large language models to generate internal known knowledge encoded in the parameters. However, few of previous works consider the compositional unknown questions, which consist of several known or unknown sub-questions. Thus, simple binary classification (known or unknown) becomes sub-optimal and inefficient since it will call external retrieval excessively for each compositional unknown question. To this end, we propose the first Compositional unknown Question-Answering dataset (CuQA), and introduce a Self Divide-and-Conquer (Self-DC) framework to empower LLMs to adaptively call different methods on-demand, resulting in better performance and efficiency. Experimental results on two datasets (CuQA and FreshQA) demonstrate that Self-DC can achieve comparable or even better performance with much more less retrieval times compared with several strong baselines.
StyleBART: Decorate Pretrained Model with Style Adapters for Unsupervised Stylistic Headline Generation
Oct 26, 2023Stylistic headline generation is the task to generate a headline that not only summarizes the content of an article, but also reflects a desired style that attracts users. As style-specific article-headline pairs are scarce, previous researches focus on unsupervised approaches with a standard headline generation dataset and mono-style corpora. In this work, we follow this line and propose StyleBART, an unsupervised approach for stylistic headline generation. Our method decorates the pretrained BART model with adapters that are responsible for different styles and allows the generation of headlines with diverse styles by simply switching the adapters. Different from previous works, StyleBART separates the task of style learning and headline generation, making it possible to freely combine the base model and the style adapters during inference. We further propose an inverse paraphrasing task to enhance the style adapters. Extensive automatic and human evaluations show that StyleBART achieves new state-of-the-art performance in the unsupervised stylistic headline generation task, producing high-quality headlines with the desired style.
Evaluating Explanation Methods for Vision-and-Language Navigation
Oct 10, 2023The ability to navigate robots with natural language instructions in an unknown environment is a crucial step for achieving embodied artificial intelligence (AI). With the improving performance of deep neural models proposed in the field of vision-and-language navigation (VLN), it is equally interesting to know what information the models utilize for their decision-making in the navigation tasks. To understand the inner workings of deep neural models, various explanation methods have been developed for promoting explainable AI (XAI). But they are mostly applied to deep neural models for image or text classification tasks and little work has been done in explaining deep neural models for VLN tasks. In this paper, we address these problems by building quantitative benchmarks to evaluate explanation methods for VLN models in terms of faithfulness. We propose a new erasure-based evaluation pipeline to measure the step-wise textual explanation in the sequential decision-making setting. We evaluate several explanation methods for two representative VLN models on two popular VLN datasets and reveal valuable findings through our experiments.
TADIS: Steering Models for Deep-Thinking about Demonstration Examples
Oct 05, 2023
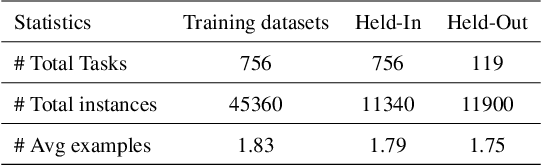
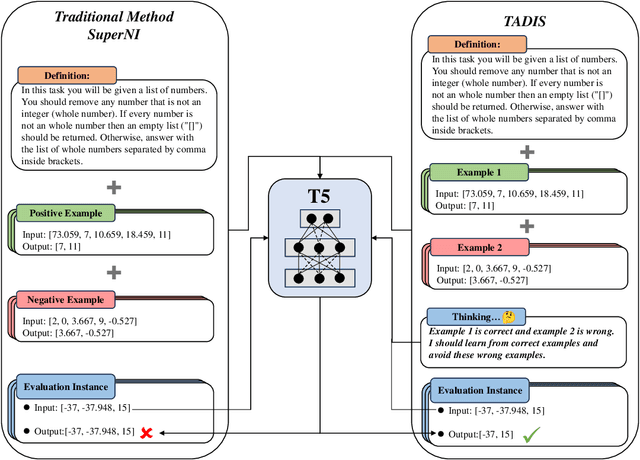
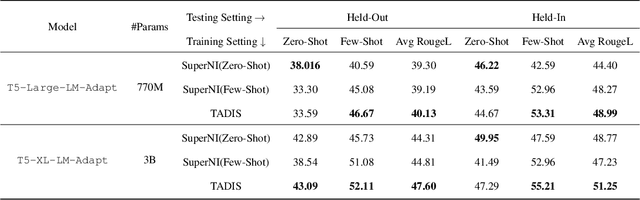
Instruction tuning has been demonstrated that could significantly improve the zero-shot generalization capability to unseen tasks by an apparent margin. By incorporating additional context (e.g., task definition, examples) during the fine-tuning process, Large Language Models (LLMs) achieved much higher performance than before. However, recent work reported that delusive task examples can achieve almost the same performance as correct task examples, indicating the input-label correspondence is less important than previously thought. Intrigued by this counter-intuitive observation, we suspect models have the same illusion of competence as humans. Therefore, we propose a novel method called TADIS that steers LLMs for "Deep-Thinking'' about demonstration examples instead of merely seeing. To alleviate the illusion of competence of models, we first ask the model to verify the correctness of shown examples. Then, using the verification results as conditions to elicit models for a better answer. Our experimental results show that TADIS consistently outperforms competitive baselines on in-domain and out-domain tasks (improving 2.79 and 4.03 average ROUGLE-L on out-domain and in-domain datasets, respectively). Despite the presence of generated examples (not all of the thinking labels are accurate), TADIS can notably enhance performance in zero-shot and few-shot settings. This also suggests that our approach can be adopted on a large scale to improve the instruction following capabilities of models without any manual labor. Moreover, we construct three types of thinking labels with different model sizes and find that small models learn from the format of TADIS but larger models can be steered for "Deep-Thinking''.
Multilingual Sentence Transformer as A Multilingual Word Aligner
Jan 28, 2023



Multilingual pretrained language models (mPLMs) have shown their effectiveness in multilingual word alignment induction. However, these methods usually start from mBERT or XLM-R. In this paper, we investigate whether multilingual sentence Transformer LaBSE is a strong multilingual word aligner. This idea is non-trivial as LaBSE is trained to learn language-agnostic sentence-level embeddings, while the alignment extraction task requires the more fine-grained word-level embeddings to be language-agnostic. We demonstrate that the vanilla LaBSE outperforms other mPLMs currently used in the alignment task, and then propose to finetune LaBSE on parallel corpus for further improvement. Experiment results on seven language pairs show that our best aligner outperforms previous state-of-the-art models of all varieties. In addition, our aligner supports different language pairs in a single model, and even achieves new state-of-the-art on zero-shot language pairs that does not appear in the finetuning process.
Meta-analysis of individualized treatment rules via sign-coherency
Nov 28, 2022



Medical treatments tailored to a patient's baseline characteristics hold the potential of improving patient outcomes while reducing negative side effects. Learning individualized treatment rules (ITRs) often requires aggregation of multiple datasets(sites); however, current ITR methodology does not take between-site heterogeneity into account, which can hurt model generalizability when deploying back to each site. To address this problem, we develop a method for individual-level meta-analysis of ITRs, which jointly learns site-specific ITRs while borrowing information about feature sign-coherency via a scientifically-motivated directionality principle. We also develop an adaptive procedure for model tuning, using information criteria tailored to the ITR learning problem. We study the proposed methods through numerical experiments to understand their performance under different levels of between-site heterogeneity and apply the methodology to estimate ITRs in a large multi-center database of electronic health records. This work extends several popular methodologies for estimating ITRs (A-learning, weighted learning) to the multiple-sites setting.
Policy Learning for Optimal Individualized Dose Intervals
Feb 24, 2022



We study the problem of learning individualized dose intervals using observational data. There are very few previous works for policy learning with continuous treatment, and all of them focused on recommending an optimal dose rather than an optimal dose interval. In this paper, we propose a new method to estimate such an optimal dose interval, named probability dose interval (PDI). The potential outcomes for doses in the PDI are guaranteed better than a pre-specified threshold with a given probability (e.g., 50%). The associated nonconvex optimization problem can be efficiently solved by the Difference-of-Convex functions (DC) algorithm. We prove that our estimated policy is consistent, and its risk converges to that of the best-in-class policy at a root-n rate. Numerical simulations show the advantage of the proposed method over outcome modeling based benchmarks. We further demonstrate the performance of our method in determining individualized Hemoglobin A1c (HbA1c) control intervals for elderly patients with diabetes.