 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Powered Estimate of The Extrinsic Parameters on Unmanned Surface Vehicles
Jun 07, 2024Unmanned Surface Vehicles (USVs) are pivotal in marine exploration, but their sensors' accuracy is compromised by the dynamic marine environment. Traditional calibration methods fall short in these conditions. This paper introduces a deep learning architecture that predicts changes in the USV's dynamic metacenter and refines sensors' extrinsic parameters in real time using a Time-Sequence General Regression Neural Network (GRNN) with Euler angles as input. Simulation data from Unity3D ensures robust training and testing. Experimental results show that the Time-Sequence GRNN achieves the lowest mean squared error (MSE) loss, outperforming traditional neural networks. This method significantly enhances sensor calibration for USVs, promising improved data accuracy in challenging maritime conditions. Future work will refine the network and validate results with real-world data.
TabPedia: Towards Comprehensive Visual Table Understanding with Concept Synergy
Jun 03, 2024Tables contain factual and quantitative data accompanied by various structures and contents that pose challenges for machine comprehension. Previous methods generally design task-specific architectures and objectives for individual tasks, resulting in modal isolation and intricate workflows. In this paper, we present a novel large vision-language model, TabPedia, equipped with a concept synergy mechanism. In this mechanism, all the involved diverse visual table understanding (VTU) tasks and multi-source visual embeddings are abstracted as concepts. This unified framework allows TabPedia to seamlessly integrate VTU tasks, such as table detection, table structure recognition, table querying, and table question answering, by leveraging the capabilities of large language models (LLMs). Moreover, the concept synergy mechanism enables table perception-related and comprehension-related tasks to work in harmony, as they can effectively leverage the needed clues from the corresponding source perception embeddings. Furthermore, to better evaluate the VTU task in real-world scenarios, we establish a new and comprehensive table VQA benchmark, ComTQA, featuring approximately 9,000 QA pairs. Extensive quantitative and qualitative experiments on both table perception and comprehension tasks, conducted across various public benchmarks, validate the effectiveness of our TabPedia. The superior performance further confirms the feasibility of using LLMs for understanding visual tables when all concepts work in synergy. The benchmark ComTQA has been open-sourced at https://huggingface.co/datasets/ByteDance/ComTQA. The source code and model will be released later.
W-Net: A Facial Feature-Guided Face Super-Resolution Network
Jun 02, 2024Face Super-Resolution (FSR) aims to recover high-resolution (HR) face images from low-resolution (LR) ones. Despite the progress made by convolutional neural networks in FSR, the results of existing approaches are not ideal due to their low reconstruction efficiency and insufficient utilization of prior information. Considering that faces are highly structured objects, effectively leveraging facial priors to improve FSR results is a worthwhile endeavor. This paper proposes a novel network architecture called W-Net to address this challenge. W-Net leverages meticulously designed Parsing Block to fully exploit the resolution potential of LR image. We use this parsing map as an attention prior, effectively integrating information from both the parsing map and LR images. Simultaneously, we perform multiple fusions in various dimensions through the W-shaped network structure combined with the LPF(LR-Parsing Map Fusion Module). Additionally, we utilize a facial parsing graph as a mask, assigning different weights and loss functions to key facial areas to balance the performance of our reconstructed facial images between perceptual quality and pixel accuracy. We conducted extensive comparative experiments, not only limited to conventional facial super-resolution metrics but also extending to downstream tasks such as facial recognition and facial keypoint detection. The experiments demonstrate that W-Net exhibits outstanding performance in quantitative metrics, visual quality, and downstream tasks.
TD3 Based Collision Free Motion Planning for Robot Navigation
May 24, 2024This paper addresses the challenge of collision-free motion planning in automated navigation within complex environments. Utilizing advancements in Deep Reinforcement Learning (DRL) and sensor technologies like LiDAR, we propose the TD3-DWA algorithm, an innovative fusion of the traditional Dynamic Window Approach (DWA) with the Twin Delayed Deep Deterministic Policy Gradient (TD3). This hybrid algorithm enhances the efficiency of robotic path planning by optimizing the sampling interval parameters of DWA to effectively navigate around both static and dynamic obstacles. The performance of the TD3-DWA algorithm is validated through various simulation experiments, demonstrating its potential to significantly improve the reliability and safety of autonomous navigation systems.
Optimizing Search Advertising Strategies: Integrating Reinforcement Learning with Generalized Second-Price Auctions for Enhanced Ad Ranking and Bidding
May 22, 2024This paper explores the integration of strategic optimization methods in search advertising, focusing on ad ranking and bidding mechanisms within E-commerce platforms. By employing a combination of reinforcement learning and evolutionary strategies, we propose a dynamic model that adjusts to varying user interactions and optimizes the balance between advertiser cost, user relevance, and platform revenue. Our results suggest significant improvements in ad placement accuracy and cost efficiency, demonstrating the model's applicability in real-world scenarios.
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
May 20, 2024Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. However, most TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets using translation engines, the translation-based protocol encounters a substantial ``Visual-textual misalignment'' problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Furthermore, it does not adequately tackle challenges related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we address the task of multilingual TEC-VQA and provide a benchmark with high-quality human expert annotations in 9 diverse languages, called MTVQA. To our knowledge, MTVQA is the first multilingual TEC-VQA benchmark to provide human expert annotations for text-centric scenarios. Further, by evaluating several state-of-the-art Multimodal Large Language Models (MLLMs), including GPT-4V, on our MTVQA dataset, it is evident that there is still room for performance improvement, underscoring the value of our dataset. We hope this dataset will provide researchers with fresh perspectives and inspiration within the community. The MTVQA dataset will be available at https://huggingface.co/datasets/ByteDance/MTVQA.
Localization Through Particle Filter Powered Neural Network Estimated Monocular Camera Poses
Apr 26, 2024The reduced cost and computational and calibration requirements of monocular cameras make them ideal positioning sensors for mobile robots, albeit at the expense of any meaningful depth measurement. Solutions proposed by some scholars to this localization problem involve fusing pose estimates from convolutional neural networks (CNNs) with pose estimates from geometric constraints on motion to generate accurate predictions of robot trajectories. However, the distribution of attitude estimation based on CNN is not uniform, resulting in certain translation problems in the prediction of robot trajectories. This paper proposes improving these CNN-based pose estimates by propagating a SE(3) uniform distribution driven by a particle filter. The particles utilize the same motion model used by the CNN, while updating their weights using CNN-based estimates. The results show that while the rotational component of pose estimation does not consistently improve relative to CNN-based estimation, the translational component is significantly more accurate. This factor combined with the superior smoothness of the filtered trajectories shows that the use of particle filters significantly improves the performance of CNN-based localization algorithms.
Adaptive speed planning for Unmanned Vehicle Based on Deep Reinforcement Learning
Apr 26, 2024In order to solve the problem of frequent deceleration of unmanned vehicles when approaching obstacles, this article uses a Deep Q-Network (DQN) and its extension, the Double Deep Q-Network (DDQN), to develop a local navigation system that adapts to obstacles while maintaining optimal speed planning. By integrating improved reward functions and obstacle angle determination methods, the system demonstrates significant enhancements in maneuvering capabilities without frequent decelerations. Experiments conducted in simulated environments with varying obstacle densities confirm the effectiveness of the proposed method in achieving more stable and efficient path planning.
BotDGT: Dynamicity-aware Social Bot Detection with Dynamic Graph Transformers
Apr 24, 2024Detecting social bots has evolved into a pivotal yet intricate task, aimed at combating the dissemination of misinformation and preserving the authenticity of online interactions. While earlier graph-based approaches, which leverage topological structure of social networks, yielded notable outcomes, they overlooked the inherent dynamicity of social networks -- In reality, they largely depicted the social network as a static graph and solely relied on its most recent state. Due to the absence of dynamicity modeling, such approaches are vulnerable to evasion, particularly when advanced social bots interact with other users to camouflage identities and escape detection. To tackle these challenges, we propose BotDGT, a novel framework that not only considers the topological structure, but also effectively incorporates dynamic nature of social network. Specifically, we characterize a social network as a dynamic graph. A structural module is employed to acquire topological information from each historical snapshot. Additionally, a temporal module is proposed to integrate historical context and model the evolving behavior patterns exhibited by social bots and legitimate users. Experimental results demonstrate the superiority of BotDGT against the leading methods that neglected the dynamic nature of social networks in terms of accuracy, recall, and F1-score.
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Apr 19, 2024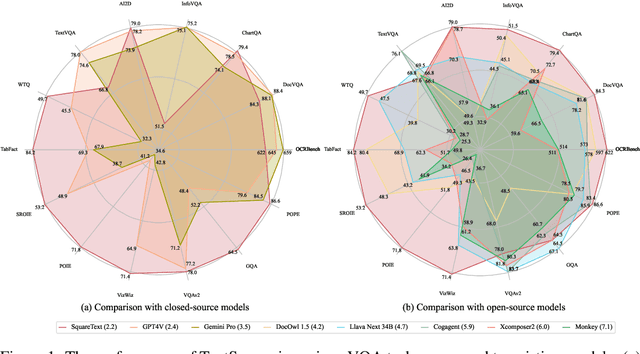

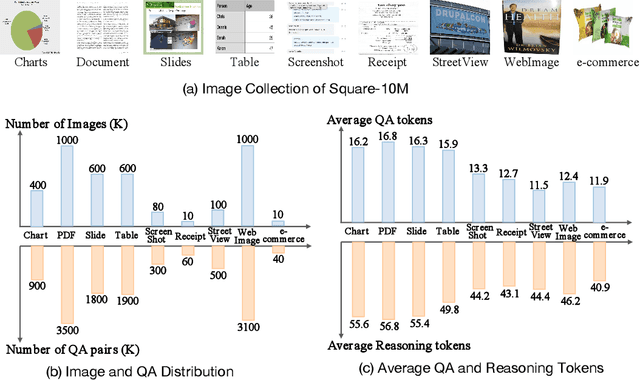
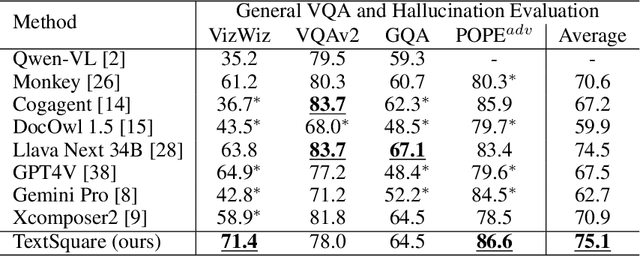
Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.